 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonglin Mu
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Mar 31, 2024
Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safety issues as various vulnerabilities are exposed. Faced with the problem, the field of red teaming is experiencing fast-paced growth, which highlights the need for a comprehensive organization covering the entire pipeline and addressing emerging topics for the community. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the searcher framework that unifies various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around multilingual models, overkill of harmless queries, and safety of downstream applications. We hope this survey can provide a systematic perspective on the field and unlock new areas of research.
Beyond Static Evaluation: A Dynamic Approach to Assessing AI Assistants' API Invocation Capabilities
Mar 27, 2024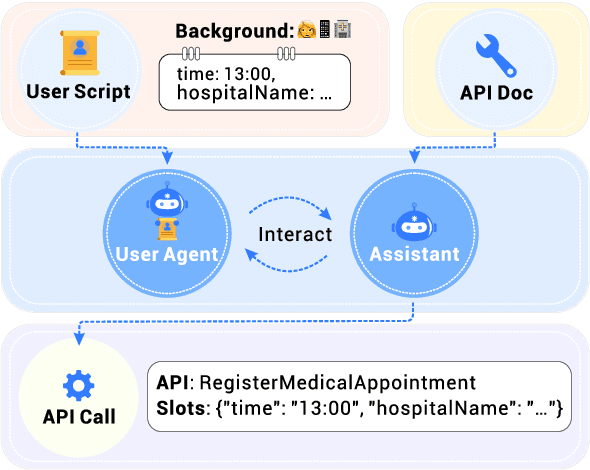
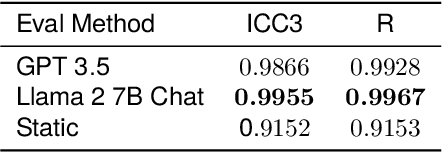
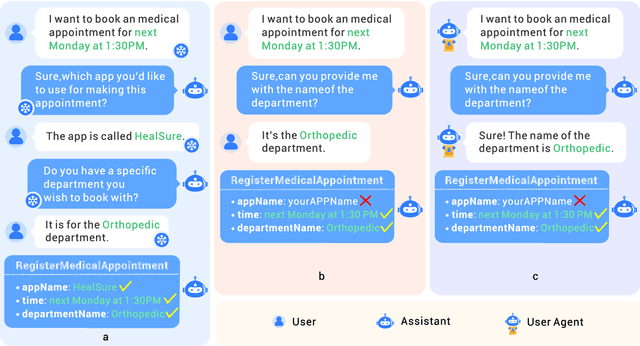

With the rise of Large Language Models (LLMs), AI assistants' ability to utilize tools, especially through API calls, has advanced notably. This progress has necessitated more accurate evaluation methods. Many existing studies adopt static evaluation, where they assess AI assistants' API call based on pre-defined dialogue histories. However, such evaluation method can be misleading, as an AI assistant might fail in generating API calls from preceding human interaction in real cases. Instead of the resource-intensive method of direct human-machine interactions, we propose Automated Dynamic Evaluation (AutoDE) to assess an assistant's API call capability without human involvement. In our framework, we endeavor to closely mirror genuine human conversation patterns in human-machine interactions, using a LLM-based user agent, equipped with a user script to ensure human alignment. Experimental results highlight that AutoDE uncovers errors overlooked by static evaluations, aligning more closely with human assessment. Testing four AI assistants using our crafted benchmark, our method further mirrored human evaluation compared to conventional static evaluations.
Improving Domain Generalization for Sound Classification with Sparse Frequency-Regularized Transformer
Jul 19, 2023



Sound classification models' performance suffers from generalizing on out-of-distribution (OOD) data. Numerous methods have been proposed to help the model generalize. However, most either introduce inference overheads or focus on long-lasting CNN-variants, while Transformers has been proven to outperform CNNs on numerous natural language processing and computer vision tasks. We propose FRITO, an effective regularization technique on Transformer's self-attention, to improve the model's generalization ability by limiting each sequence position's attention receptive field along the frequency dimension on the spectrogram. Experiments show that our method helps Transformer models achieve SOTA generalization performance on TAU 2020 and Nsynth datasets while saving 20% inference time.
MixPro: Simple yet Effective Data Augmentation for Prompt-based Learning
Apr 19, 2023
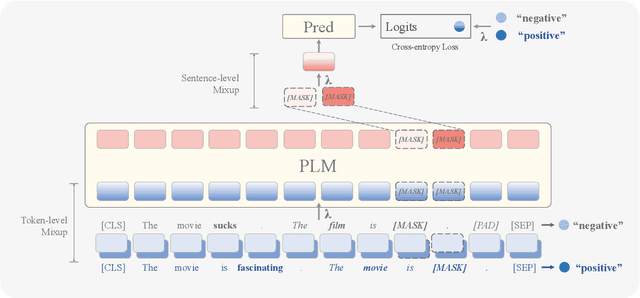
Prompt-based learning reformulates downstream tasks as cloze problems by combining the original input with a template. This technique is particularly useful in few-shot learning, where a model is trained on a limited amount of data. However, the limited templates and text used in few-shot prompt-based learning still leave significant room for performance improvement. Additionally, existing methods using model ensembles can constrain the model efficiency. To address these issues, we propose an augmentation method called MixPro, which augments both the vanilla input text and the templates through token-level, sentence-level, and epoch-level Mixup strategies. We conduct experiments on five few-shot datasets, and the results show that MixPro outperforms other augmentation baselines, improving model performance by an average of 5.08% compared to before augmentation.