 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyin Tang
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Jun 11, 2023


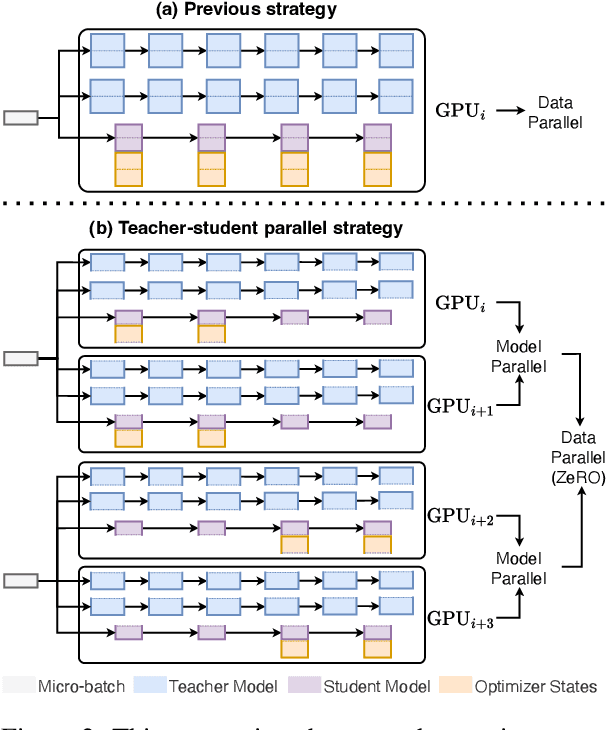
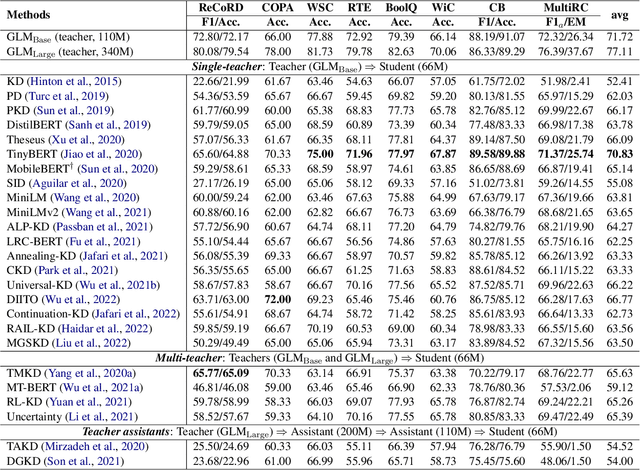
Currently, the reduction in the parameter scale of large-scale pre-trained language models (PLMs) through knowledge distillation has greatly facilitated their widespread deployment on various devices. However, the deployment of knowledge distillation systems faces great challenges in real-world industrial-strength applications, which require the use of complex distillation methods on even larger-scale PLMs (over 10B), limited by memory on GPUs and the switching of methods. To overcome these challenges, we propose GKD, a general knowledge distillation framework that supports distillation on larger-scale PLMs using various distillation methods. With GKD, developers can build larger distillation models on memory-limited GPUs and easily switch and combine different distillation methods within a single framework. Experimental results show that GKD can support the distillation of at least 100B-scale PLMs and 25 mainstream methods on 8 NVIDIA A100 (40GB) GPUs.
Multi-task Transformer with Relation-attention and Type-attention for Named Entity Recognition
Mar 20, 2023



Named entity recognition (NER) is an important research problem in natural language processing. There are three types of NER tasks, including flat, nested and discontinuous entity recognition. Most previous sequential labeling models are task-specific, while recent years have witnessed the rising of generative models due to the advantage of unifying all NER tasks into the seq2seq model framework. Although achieving promising performance, our pilot studies demonstrate that existing generative models are ineffective at detecting entity boundaries and estimating entity types. This paper proposes a multi-task Transformer, which incorporates an entity boundary detection task into the named entity recognition task. More concretely, we achieve entity boundary detection by classifying the relations between tokens within the sentence. To improve the accuracy of entity-type mapping during decoding, we adopt an external knowledge base to calculate the prior entity-type distributions and then incorporate the information into the model via the self and cross-attention mechanisms. We perform experiments on an extensive set of NER benchmarks, including two flat, three nested, and three discontinuous NER datasets. Experimental results show that our approach considerably improves the generative NER model's performance.
Inflected Forms Are Redundant in Question Generation Models
Jan 01, 2023



Neural models with an encoder-decoder framework provide a feasible solution to Question Generation (QG). However, after analyzing the model vocabulary we find that current models (both RNN-based and pre-training based) have more than 23\% inflected forms. As a result, the encoder will generate separate embeddings for the inflected forms, leading to a waste of training data and parameters. Even worse, in decoding these models are vulnerable to irrelevant noise and they suffer from high computational costs. In this paper, we propose an approach to enhance the performance of QG by fusing word transformation. Firstly, we identify the inflected forms of words from the input of encoder, and replace them with the root words, letting the encoder pay more attention to the repetitive root words. Secondly, we propose to adapt QG as a combination of the following actions in the encode-decoder framework: generating a question word, copying a word from the source sequence or generating a word transformation type. Such extension can greatly decrease the size of predicted words in the decoder as well as noise. We apply our approach to a typical RNN-based model and \textsc{UniLM} to get the improved versions. We conduct extensive experiments on SQuAD and MS MARCO datasets. The experimental results show that the improved versions can significantly outperform the corresponding baselines in terms of BLEU, ROUGE-L and METEOR as well as time cost.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022



Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.
VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction
Dec 08, 2021



With the booming of pre-trained transformers, remarkable progress has been made on textual pair modeling to support relevant natural language applications. Two lines of approaches are developed for text matching: interaction-based models performing full interactions over the textual pair, and representation-based models encoding the pair independently with siamese encoders. The former achieves compelling performance due to its deep interaction modeling ability, yet with a sacrifice in inference latency. The latter is efficient and widely adopted for practical use, however, suffers from severe performance degradation due to the lack of interactions. Though some prior works attempt to integrate interactive knowledge into representation-based models, considering the computational cost, they only perform late interaction or knowledge transferring at the top layers. Interactive information in the lower layers is still missing, which limits the performance of representation-based solutions. To remedy this, we propose a novel \textit{Virtual} InteRacTion mechanism, termed as VIRT, to enable full and deep interaction modeling in representation-based models without \textit{actual} inference computations. Concretely, VIRT asks representation-based encoders to conduct virtual interactions to mimic the behaviors as interaction-based models do. In addition, the knowledge distilled from interaction-based encoders is taken as supervised signals to promise the effectiveness of virtual interactions. Since virtual interactions only happen at the training stage, VIRT would not increase the inference cost. Furthermore, we design a VIRT-adapted late interaction strategy to fully utilize the learned virtual interactive knowledge.
Improving Document Representations by Generating Pseudo Query Embeddings for Dense Retrieval
May 08, 2021



Recently, the retrieval models based on dense representations have been gradually applied in the first stage of the document retrieval tasks, showing better performance than traditional sparse vector space models. To obtain high efficiency, the basic structure of these models is Bi-encoder in most cases. However, this simple structure may cause serious information loss during the encoding of documents since the queries are agnostic. To address this problem, we design a method to mimic the queries on each of the documents by an iterative clustering process and represent the documents by multiple pseudo queries (i.e., the cluster centroids). To boost the retrieval process using approximate nearest neighbor search library, we also optimize the matching function with a two-step score calculation procedure. Experimental results on several popular ranking and QA datasets show that our model can achieve state-of-the-art results.