 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuadong Li
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 08, 2023
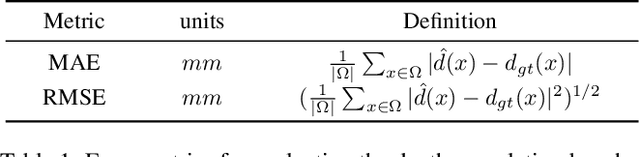

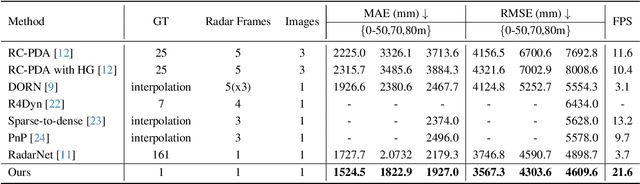
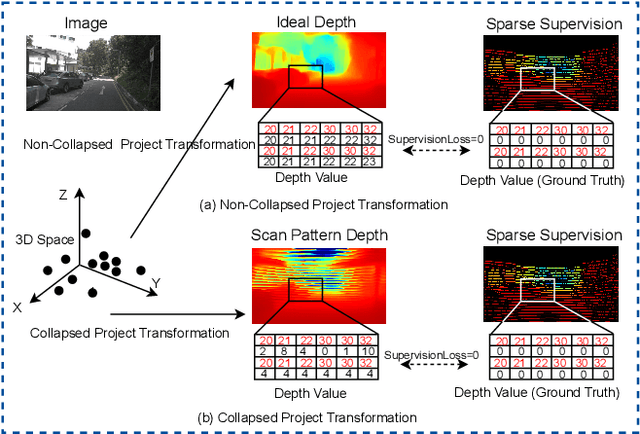
It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...
Discriminative-Region Attention and Orthogonal-View Generation Model for Vehicle Re-Identification
Apr 28, 2022



Vehicle re-identification (Re-ID) is urgently demanded to alleviate thepressure caused by the increasingly onerous task of urban traffic management. Multiple challenges hamper the applications of vision-based vehicle Re-ID methods: (1) The appearances of different vehicles of the same brand/model are often similar; However, (2) the appearances of the same vehicle differ significantly from different viewpoints. Previous methods mainly use manually annotated multi-attribute datasets to assist the network in getting detailed cues and in inferencing multi-view to improve the vehicle Re-ID performance. However, finely labeled vehicle datasets are usually unattainable in real application scenarios. Hence, we propose a Discriminative-Region Attention and Orthogonal-View Generation (DRA-OVG) model, which only requires identity (ID) labels to conquer the multiple challenges of vehicle Re-ID.The proposed DRA model can automatically extract the discriminative region features, which can distinguish similar vehicles. And the OVG model can generate multi-view features based on the input view features to reduce the impact of viewpoint mismatches. Finally, the distance between vehicle appearances is presented by the discriminative region features and multi-view features together. Therefore, the significance of pairwise distance measure between vehicles is enhanced in acomplete feature space. Extensive experiments substantiate the effectiveness of each proposed ingredient, and experimental results indicate that our approach achieves remarkable improvements over the state- of-the-art vehicle Re-ID methods on VehicleID and VeRi-776 datasets.