 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuaidong Zhang
Towards a Smaller Student: Capacity Dynamic Distillation for Efficient Image Retrieval
Mar 16, 2023
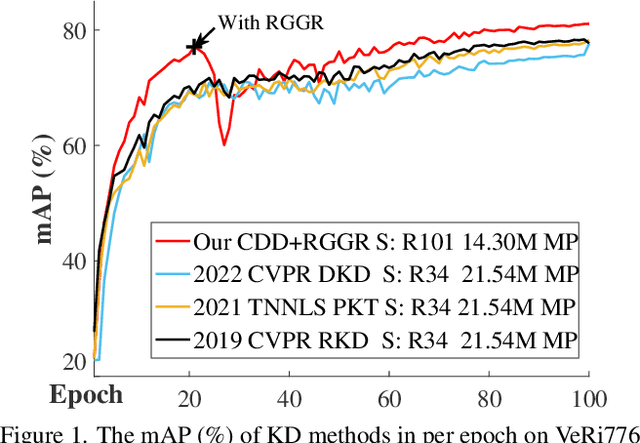

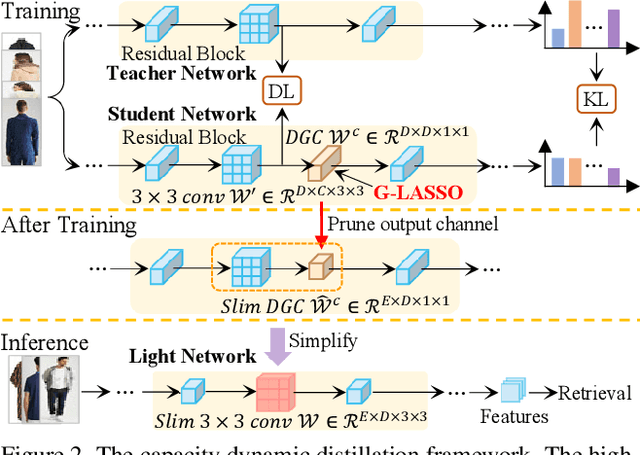
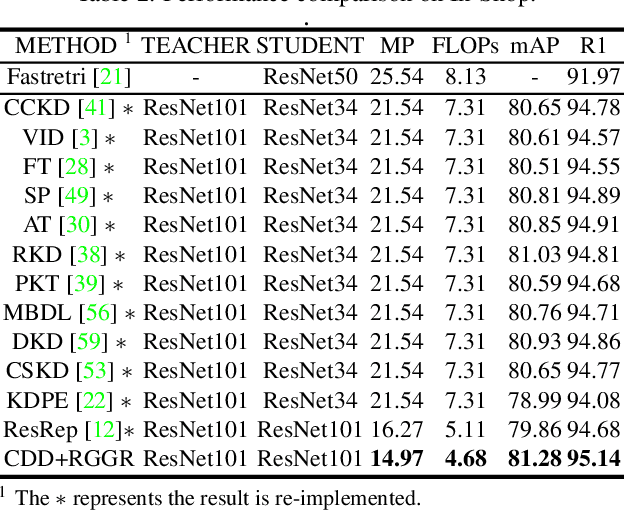
Previous Knowledge Distillation based efficient image retrieval methods employs a lightweight network as the student model for fast inference. However, the lightweight student model lacks adequate representation capacity for effective knowledge imitation during the most critical early training period, causing final performance degeneration. To tackle this issue, we propose a Capacity Dynamic Distillation framework, which constructs a student model with editable representation capacity. Specifically, the employed student model is initially a heavy model to fruitfully learn distilled knowledge in the early training epochs, and the student model is gradually compressed during the training. To dynamically adjust the model capacity, our dynamic framework inserts a learnable convolutional layer within each residual block in the student model as the channel importance indicator. The indicator is optimized simultaneously by the image retrieval loss and the compression loss, and a retrieval-guided gradient resetting mechanism is proposed to release the gradient conflict. Extensive experiments show that our method has superior inference speed and accuracy, e.g., on the VeRi-776 dataset, given the ResNet101 as a teacher, our method saves 67.13% model parameters and 65.67% FLOPs (around 24.13% and 21.94% higher than state-of-the-arts) without sacrificing accuracy (around 2.11% mAP higher than state-of-the-arts).
Context-aware and Scale-insensitive Temporal Repetition Counting
May 18, 2020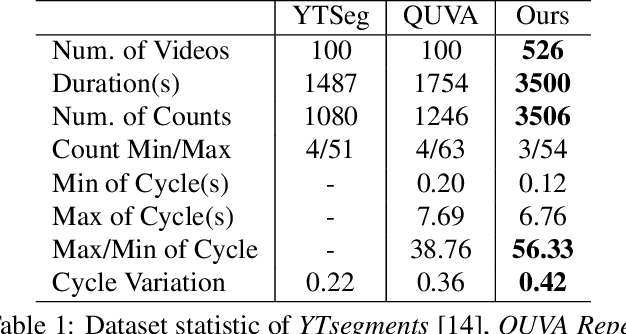
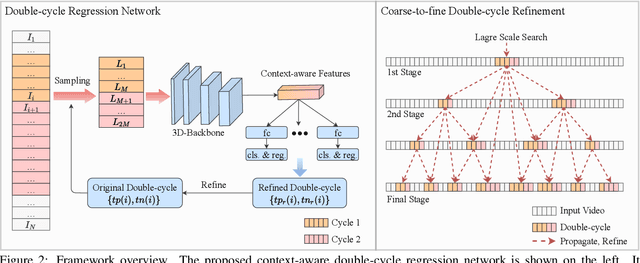
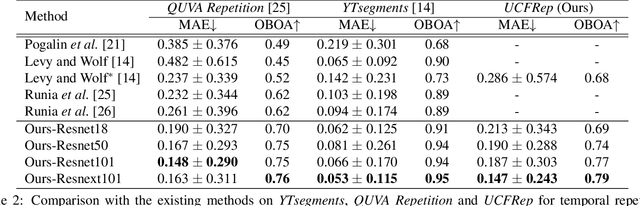

Temporal repetition counting aims to estimate the number of cycles of a given repetitive action. Existing deep learning methods assume repetitive actions are performed in a fixed time-scale, which is invalid for the complex repetitive actions in real life. In this paper, we tailor a context-aware and scale-insensitive framework, to tackle the challenges in repetition counting caused by the unknown and diverse cycle-lengths. Our approach combines two key insights: (1) Cycle lengths from different actions are unpredictable that require large-scale searching, but, once a coarse cycle length is determined, the variety between repetitions can be overcome by regression. (2) Determining the cycle length cannot only rely on a short fragment of video but a contextual understanding. The first point is implemented by a coarse-to-fine cycle refinement method. It avoids the heavy computation of exhaustively searching all the cycle lengths in the video, and, instead, it propagates the coarse prediction for further refinement in a hierarchical manner. We secondly propose a bidirectional cycle length estimation method for a context-aware prediction. It is a regression network that takes two consecutive coarse cycles as input, and predicts the locations of the previous and next repetitive cycles. To benefit the training and evaluation of temporal repetition counting area, we construct a new and largest benchmark, which contains 526 videos with diverse repetitive actions. Extensive experiments show that the proposed network trained on a single dataset outperforms state-of-the-art methods on several benchmarks, indicating that the proposed framework is general enough to capture repetition patterns across domains.