 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuanxuan Liao
Imagination Augmented Generation: Learning to Imagine Richer Context for Question Answering over Large Language Models
Mar 28, 2024
Retrieval-Augmented-Generation and Gener-ation-Augmented-Generation have been proposed to enhance the knowledge required for question answering over Large Language Models (LLMs). However, the former depends on external resources, and both require incorporating the explicit documents into the context, which results in longer contexts that lead to more resource consumption. Recent works indicate that LLMs have modeled rich knowledge, albeit not effectively triggered or activated. Inspired by this, we propose a novel knowledge-augmented framework, Imagination-Augmented-Generation (IAG), which simulates the human capacity to compensate for knowledge deficits while answering questions solely through imagination, without relying on external resources. Guided by IAG, we propose an imagine richer context method for question answering (IMcQA), which obtains richer context through the following two modules: explicit imagination by generating a short dummy document with long context compress and implicit imagination with HyperNetwork for generating adapter weights. Experimental results on three datasets demonstrate that IMcQA exhibits significant advantages in both open-domain and closed-book settings, as well as in both in-distribution performance and out-of-distribution generalizations. Our code will be available at https://github.com/Xnhyacinth/IAG.
LMTuner: An user-friendly and highly-integrable Training Framework for fine-tuning Large Language Models
Aug 20, 2023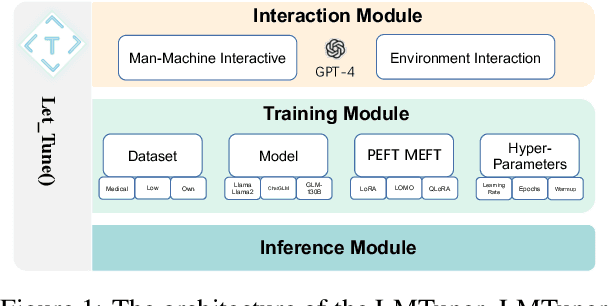
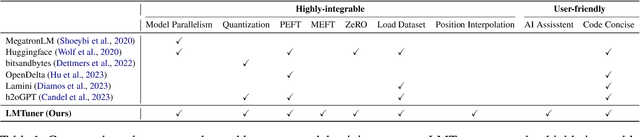
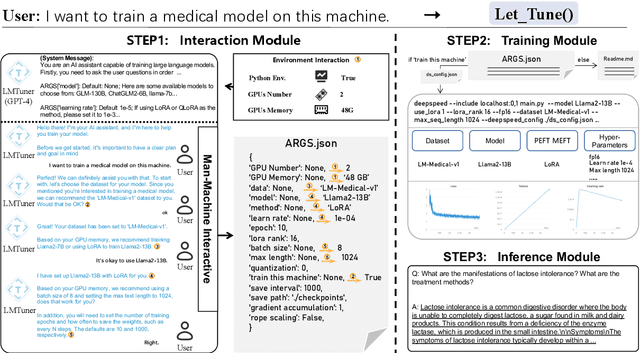
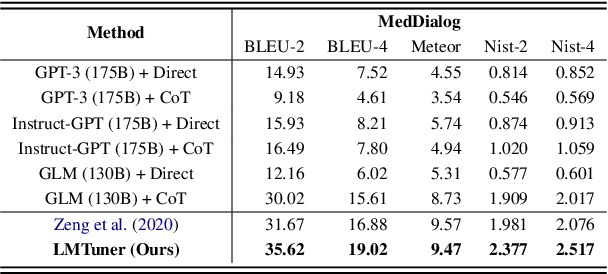
With the burgeoning development in the realm of large language models (LLMs), the demand for efficient incremental training tailored to specific industries and domains continues to increase. Currently, the predominantly employed frameworks lack modular design, it often takes a lot of coding work to kickstart the training of LLM. To address this, we present "LMTuner", a highly usable, integrable, and scalable system for training LLMs expeditiously and with minimal user-input. LMTuner comprises three main modules - the Interaction, Training, and Inference Modules. We advocate that LMTuner's usability and integrality alleviate the complexities in training large language models. Remarkably, even a novice user could commence training large language models within five minutes. Furthermore, it integrates DeepSpeed frameworks and supports Efficient Fine-Tuning methodologies like Low Rank Adaptation (LoRA), Quantized LoRA (QLoRA), etc., enabling the training of language models scaling from 300M to a whopping 130B parameters using a single server. The LMTuner's homepage (https://wengsyx.github.io/LMTuner/)and screencast video (https://youtu.be/nsXmWOmN3rE) are now publicly available.