 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Jin
Characterizing the Spectrum of the NTK via a Power Series Expansion
Nov 15, 2022

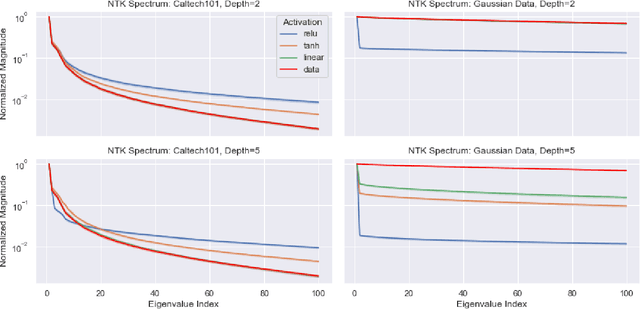
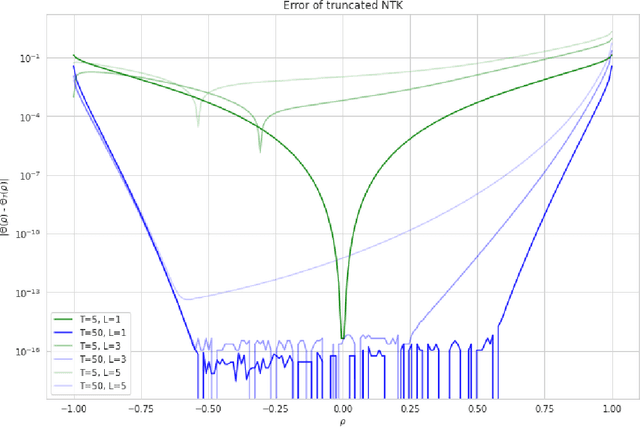
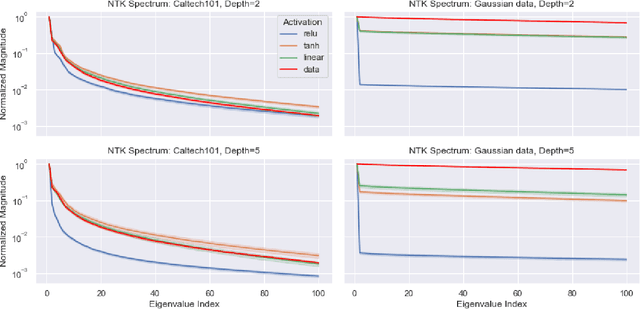
Under mild conditions on the network initialization we derive a power series expansion for the Neural Tangent Kernel (NTK) of arbitrarily deep feedforward networks in the infinite width limit. We provide expressions for the coefficients of this power series which depend on both the Hermite coefficients of the activation function as well as the depth of the network. We observe faster decay of the Hermite coefficients leads to faster decay in the NTK coefficients. Using this series, first we relate the effective rank of the NTK to the effective rank of the input-data Gram. Second, for data drawn uniformly on the sphere we derive an explicit formula for the eigenvalues of the NTK, which shows faster decay in the NTK coefficients implies a faster decay in its spectrum. From this we recover existing results on eigenvalue asymptotics for ReLU networks and comment on how the activation function influences the RKHS. Finally, for generic data and activation functions with sufficiently fast Hermite coefficient decay, we derive an asymptotic upper bound on the spectrum of the NTK.
Learning curves for Gaussian process regression with power-law priors and targets
Oct 23, 2021

We study the power-law asymptotics of learning curves for Gaussian process regression (GPR). When the eigenspectrum of the prior decays with rate $\alpha$ and the eigenexpansion coefficients of the target function decay with rate $\beta$, we show that the generalization error behaves as $\tilde O(n^{\max\{\frac{1}{\alpha}-1, \frac{1-2\beta}{\alpha}\}})$ with high probability over the draw of $n$ input samples. Under similar assumptions, we show that the generalization error of kernel ridge regression (KRR) has the same asymptotics. Infinitely wide neural networks can be related to KRR with respect to the neural tangent kernel (NTK), which in several cases is known to have a power-law spectrum. Hence our methods can be applied to study the generalization error of infinitely wide neural networks. We present toy experiments demonstrating the theory.
Implicit bias of gradient descent for mean squared error regression with wide neural networks
Jun 12, 2020
We investigate gradient descent training of wide neural networks and the corresponding implicit bias in function space. Focusing on 1D regression, we show that the solution of training a width-$n$ shallow ReLU network is within $n^{- 1/2}$ of the function which fits the training data and whose difference from initialization has smallest 2-norm of the second derivative weighted by $1/\zeta$. The curvature penalty function $1/\zeta$ is expressed in terms of the probability distribution that is utilized to initialize the network parameters, and we compute it explicitly for various common initialization procedures. For instance, asymmetric initialization with a uniform distribution yields a constant curvature penalty, and thence the solution function is the natural cubic spline interpolation of the training data. The statement generalizes to the training trajectories, which in turn are captured by trajectories of spatially adaptive smoothing splines with decreasing regularization strength.