 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuicong Zhang
Uncertainty-Aware Pseudo-Label Filtering for Source-Free Unsupervised Domain Adaptation
Mar 17, 2024
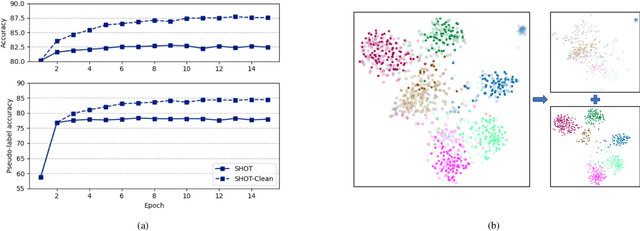
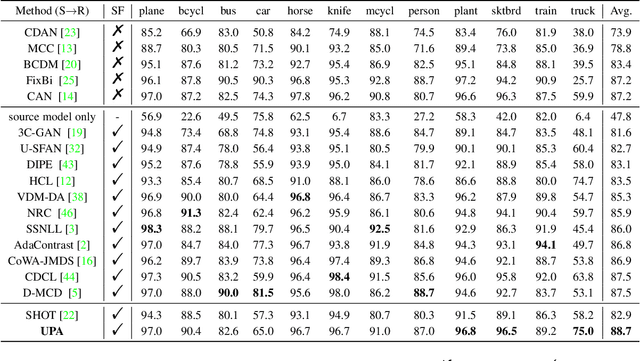
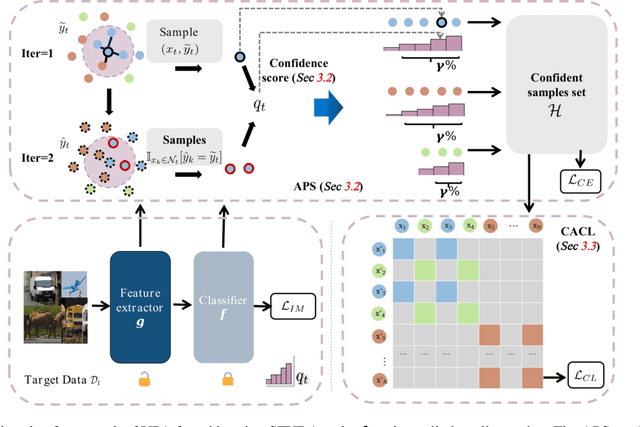
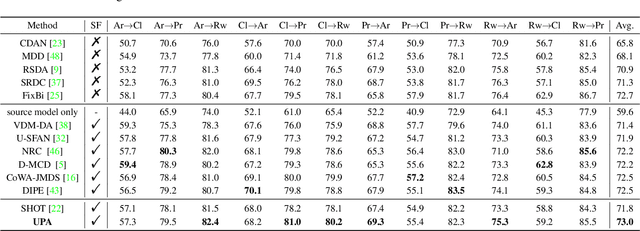
Source-free unsupervised domain adaptation (SFUDA) aims to enable the utilization of a pre-trained source model in an unlabeled target domain without access to source data. Self-training is a way to solve SFUDA, where confident target samples are iteratively selected as pseudo-labeled samples to guide target model learning. However, prior heuristic noisy pseudo-label filtering methods all involve introducing extra models, which are sensitive to model assumptions and may introduce additional errors or mislabeling. In this work, we propose a method called Uncertainty-aware Pseudo-label-filtering Adaptation (UPA) to efficiently address this issue in a coarse-to-fine manner. Specially, we first introduce a sample selection module named Adaptive Pseudo-label Selection (APS), which is responsible for filtering noisy pseudo labels. The APS utilizes a simple sample uncertainty estimation method by aggregating knowledge from neighboring samples and confident samples are selected as clean pseudo-labeled. Additionally, we incorporate Class-Aware Contrastive Learning (CACL) to mitigate the memorization of pseudo-label noise by learning robust pair-wise representation supervised by pseudo labels. Through extensive experiments conducted on three widely used benchmarks, we demonstrate that our proposed method achieves competitive performance on par with state-of-the-art SFUDA methods. Code is available at https://github.com/chenxi52/UPA.
Spatio-Temporal Deformable Attention Network for Video Deblurring
Jul 22, 2022



The key success factor of the video deblurring methods is to compensate for the blurry pixels of the mid-frame with the sharp pixels of the adjacent video frames. Therefore, mainstream methods align the adjacent frames based on the estimated optical flows and fuse the alignment frames for restoration. However, these methods sometimes generate unsatisfactory results because they rarely consider the blur levels of pixels, which may introduce blurry pixels from video frames. Actually, not all the pixels in the video frames are sharp and beneficial for deblurring. To address this problem, we propose the spatio-temporal deformable attention network (STDANet) for video delurring, which extracts the information of sharp pixels by considering the pixel-wise blur levels of the video frames. Specifically, STDANet is an encoder-decoder network combined with the motion estimator and spatio-temporal deformable attention (STDA) module, where motion estimator predicts coarse optical flows that are used as base offsets to find the corresponding sharp pixels in STDA module. Experimental results indicate that the proposed STDANet performs favorably against state-of-the-art methods on the GoPro, DVD, and BSD datasets.