 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunmin Yang
Object-Centric Domain Randomization for 3D Shape Reconstruction in the Wild
Mar 21, 2024
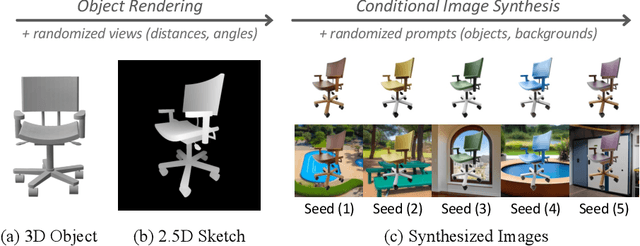


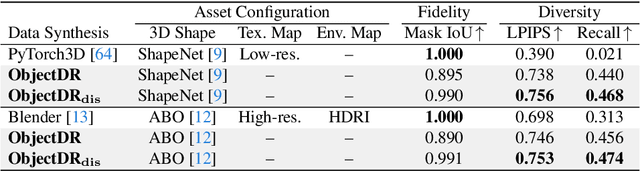
One of the biggest challenges in single-view 3D shape reconstruction in the wild is the scarcity of <3D shape, 2D image>-paired data from real-world environments. Inspired by remarkable achievements via domain randomization, we propose ObjectDR which synthesizes such paired data via a random simulation of visual variations in object appearances and backgrounds. Our data synthesis framework exploits a conditional generative model (e.g., ControlNet) to generate images conforming to spatial conditions such as 2.5D sketches, which are obtainable through a rendering process of 3D shapes from object collections (e.g., Objaverse-XL). To simulate diverse variations while preserving object silhouettes embedded in spatial conditions, we also introduce a disentangled framework which leverages an initial object guidance. After synthesizing a wide range of data, we pre-train a model on them so that it learns to capture a domain-invariant geometry prior which is consistent across various domains. We validate its effectiveness by substantially improving 3D shape reconstruction models on a real-world benchmark. In a scale-up evaluation, our pre-training achieves 23.6% superior results compared with the pre-training on high-quality computer graphics renderings.
ACTIVE: Towards Highly Transferable 3D Physical Camouflage for Universal and Robust Vehicle Evasion
Aug 16, 2023



Adversarial camouflage has garnered attention for its ability to attack object detectors from any viewpoint by covering the entire object's surface. However, universality and robustness in existing methods often fall short as the transferability aspect is often overlooked, thus restricting their application only to a specific target with limited performance. To address these challenges, we present Adversarial Camouflage for Transferable and Intensive Vehicle Evasion (ACTIVE), a state-of-the-art physical camouflage attack framework designed to generate universal and robust adversarial camouflage capable of concealing any 3D vehicle from detectors. Our framework incorporates innovative techniques to enhance universality and robustness, including a refined texture rendering that enables common texture application to different vehicles without being constrained to a specific texture map, a novel stealth loss that renders the vehicle undetectable, and a smooth and camouflage loss to enhance the naturalness of the adversarial camouflage. Our extensive experiments on 15 different models show that ACTIVE consistently outperforms existing works on various public detectors, including the latest YOLOv7. Notably, our universality evaluations reveal promising transferability to other vehicle classes, tasks (segmentation models), and the real world, not just other vehicles.
PromptStyler: Prompt-driven Style Generation for Source-free Domain Generalization
Aug 15, 2023



In a joint vision-language space, a text feature (e.g., from "a photo of a dog") could effectively represent its relevant image features (e.g., from dog photos). Also, a recent study has demonstrated the cross-modal transferability phenomenon of this joint space. From these observations, we propose PromptStyler which simulates various distribution shifts in the joint space by synthesizing diverse styles via prompts without using any images to deal with source-free domain generalization. The proposed method learns to generate a variety of style features (from "a S* style of a") via learnable style word vectors for pseudo-words S*. To ensure that learned styles do not distort content information, we force style-content features (from "a S* style of a [class]") to be located nearby their corresponding content features (from "[class]") in the joint vision-language space. After learning style word vectors, we train a linear classifier using synthesized style-content features. PromptStyler achieves the state of the art on PACS, VLCS, OfficeHome and DomainNet, even though it does not require any images for training.
DTA: Physical Camouflage Attacks using Differentiable Transformation Network
Mar 18, 2022



To perform adversarial attacks in the physical world, many studies have proposed adversarial camouflage, a method to hide a target object by applying camouflage patterns on 3D object surfaces. For obtaining optimal physical adversarial camouflage, previous studies have utilized the so-called neural renderer, as it supports differentiability. However, existing neural renderers cannot fully represent various real-world transformations due to a lack of control of scene parameters compared to the legacy photo-realistic renderers. In this paper, we propose the Differentiable Transformation Attack (DTA), a framework for generating a robust physical adversarial pattern on a target object to camouflage it against object detection models with a wide range of transformations. It utilizes our novel Differentiable Transformation Network (DTN), which learns the expected transformation of a rendered object when the texture is changed while preserving the original properties of the target object. Using our attack framework, an adversary can gain both the advantages of the legacy photo-realistic renderers including various physical-world transformations and the benefit of white-box access by offering differentiability. Our experiments show that our camouflaged 3D vehicles can successfully evade state-of-the-art object detection models in the photo-realistic environment (i.e., CARLA on Unreal Engine). Furthermore, our demonstration on a scaled Tesla Model 3 proves the applicability and transferability of our method to the real world.