 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyungwon Choi
Improving Diffusion Models for Virtual Try-on
Mar 08, 2024
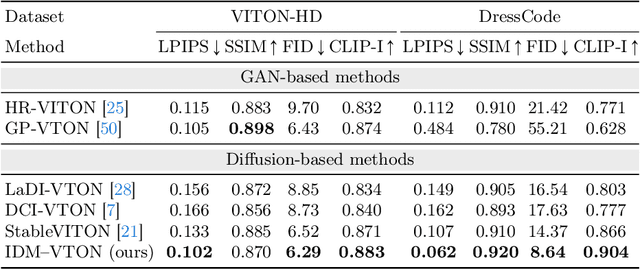
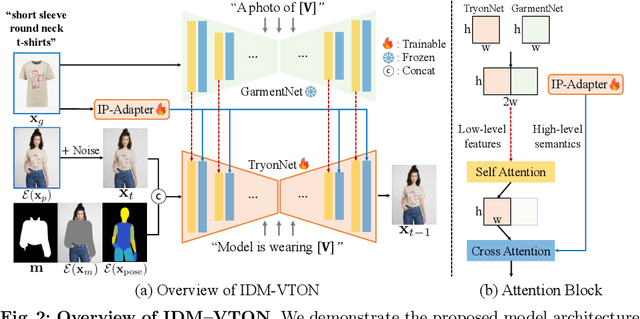
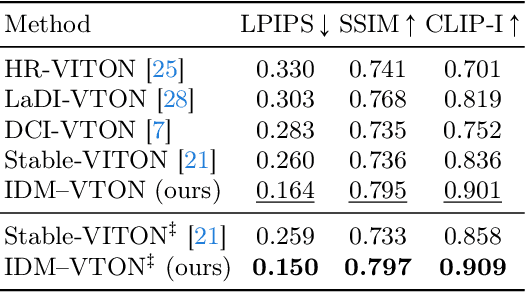

This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario.
Adiabatic Persistent Contrastive Divergence Learning
Feb 14, 2017

This paper studies the problem of parameter learning in probabilistic graphical models having latent variables, where the standard approach is the expectation maximization algorithm alternating expectation (E) and maximization (M) steps. However, both E and M steps are computationally intractable for high dimensional data, while the substitution of one step to a faster surrogate for combating against intractability can often cause failure in convergence. We propose a new learning algorithm which is computationally efficient and provably ensures convergence to a correct optimum. Its key idea is to run only a few cycles of Markov Chains (MC) in both E and M steps. Such an idea of running incomplete MC has been well studied only for M step in the literature, called Contrastive Divergence (CD) learning. While such known CD-based schemes find approximated gradients of the log-likelihood via the mean-field approach in E step, our proposed algorithm does exact ones via MC algorithms in both steps due to the multi-time-scale stochastic approximation theory. Despite its theoretical guarantee in convergence, the proposed scheme might suffer from the slow mixing of MC in E step. To tackle it, we also propose a hybrid approach applying both mean-field and MC approximation in E step, where the hybrid approach outperforms the bare mean-field CD scheme in our experiments on real-world datasets.