 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyunwoo Ha
Revisiting Learning-based Video Motion Magnification for Real-time Processing
Mar 04, 2024
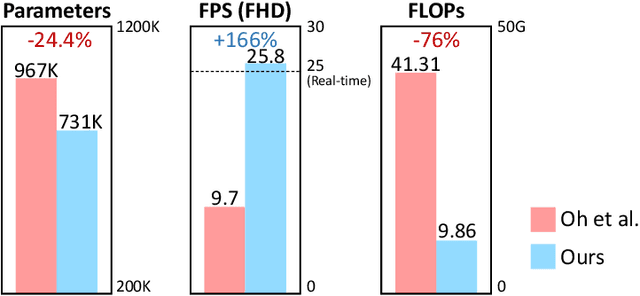

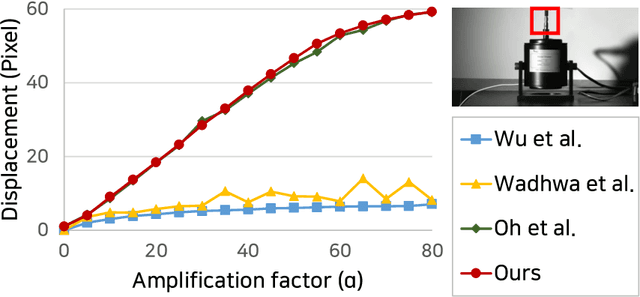
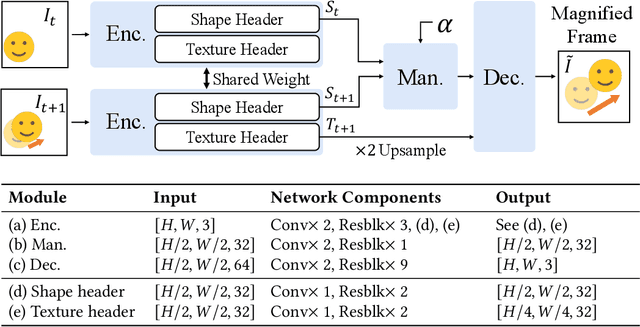
Video motion magnification is a technique to capture and amplify subtle motion in a video that is invisible to the naked eye. The deep learning-based prior work successfully demonstrates the modelling of the motion magnification problem with outstanding quality compared to conventional signal processing-based ones. However, it still lags behind real-time performance, which prevents it from being extended to various online applications. In this paper, we investigate an efficient deep learning-based motion magnification model that runs in real time for full-HD resolution videos. Due to the specified network design of the prior art, i.e. inhomogeneous architecture, the direct application of existing neural architecture search methods is complicated. Instead of automatic search, we carefully investigate the architecture module by module for its role and importance in the motion magnification task. Two key findings are 1) Reducing the spatial resolution of the latent motion representation in the decoder provides a good trade-off between computational efficiency and task quality, and 2) surprisingly, only a single linear layer and a single branch in the encoder are sufficient for the motion magnification task. Based on these findings, we introduce a real-time deep learning-based motion magnification model with4.2X fewer FLOPs and is 2.7X faster than the prior art while maintaining comparable quality.
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Mar 30, 2023
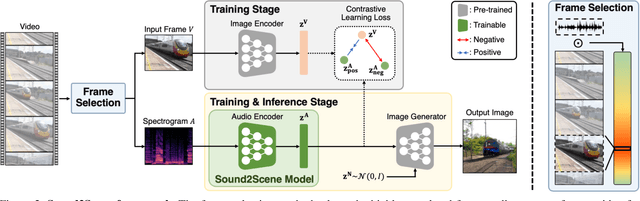


How does audio describe the world around us? In this paper, we propose a method for generating an image of a scene from sound. Our method addresses the challenges of dealing with the large gaps that often exist between sight and sound. We design a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. We translate the input audio to visual features, then use a pre-trained generator to produce an image. To further improve the quality of our generated images, we use sound source localization to select the audio-visual pairs that have strong cross-modal correlations. We obtain substantially better results on the VEGAS and VGGSound datasets than prior approaches. We also show that we can control our model's predictions by applying simple manipulations to the input waveform, or to the latent space.