 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI. V. Oseledets
AA-ICP: Iterative Closest Point with Anderson Acceleration
Sep 16, 2017
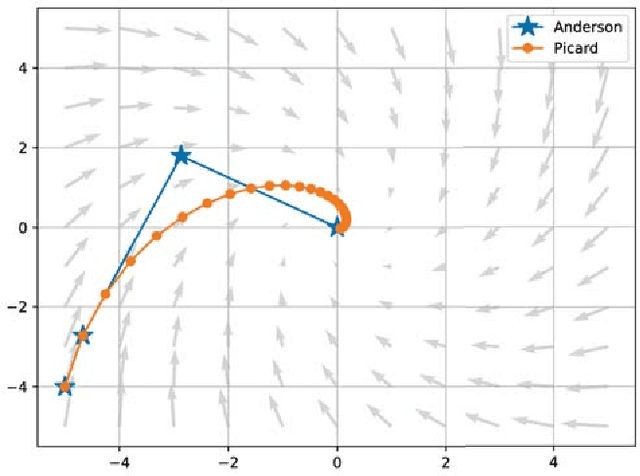

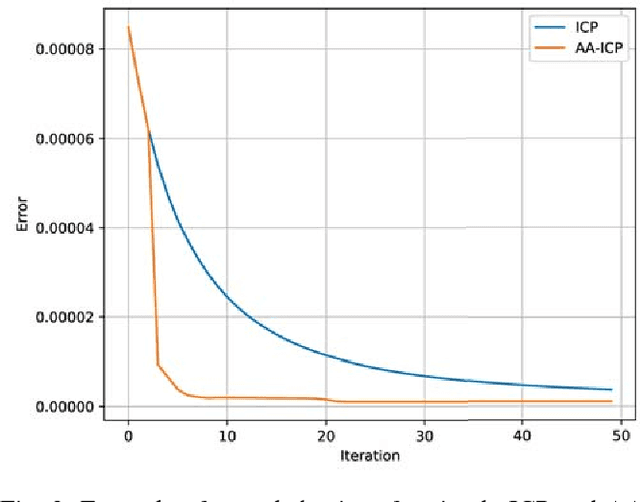
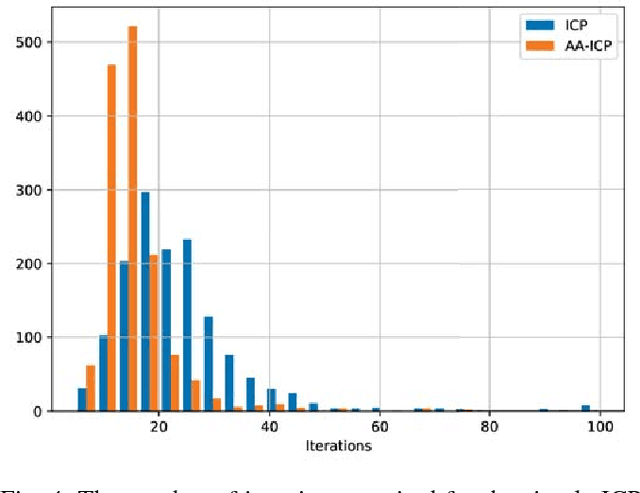
Iterative Closest Point (ICP) is a widely used method for performing scan-matching and registration. Being simple and robust method, it is still computationally expensive and may be challenging to use in real-time applications with limited resources on mobile platforms. In this paper we propose novel effective method for acceleration of ICP which does not require substantial modifications to the existing code. This method is based on an idea of Anderson acceleration which is an iterative procedure for finding a fixed point of contractive mapping. The latter is often faster than a standard Picard iteration, usually used in ICP implementations. We show that ICP, being a fixed point problem, can be significantly accelerated by this method enhanced by heuristics to improve overall robustness. We implement proposed approach into Point Cloud Library (PCL) and make it available online. Benchmarking on real-world data fully supports our claims.
Tensor Networks for Dimensionality Reduction and Large-Scale Optimizations. Part 2 Applications and Future Perspectives
Aug 30, 2017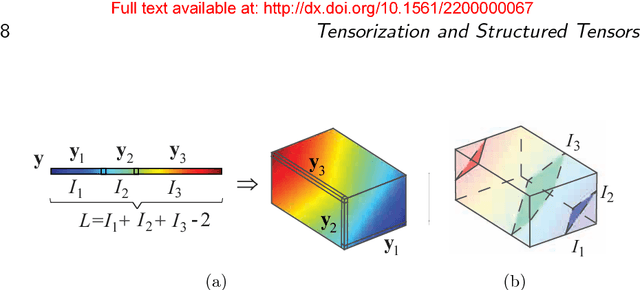

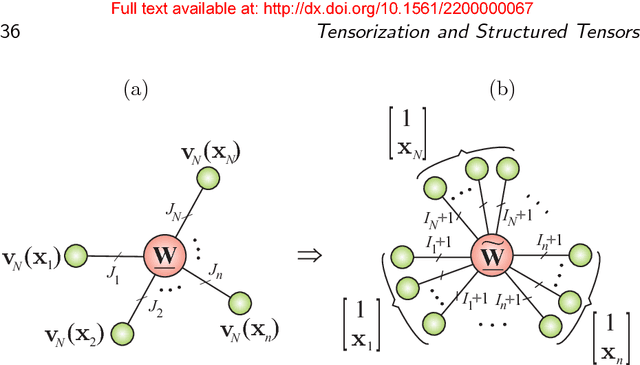
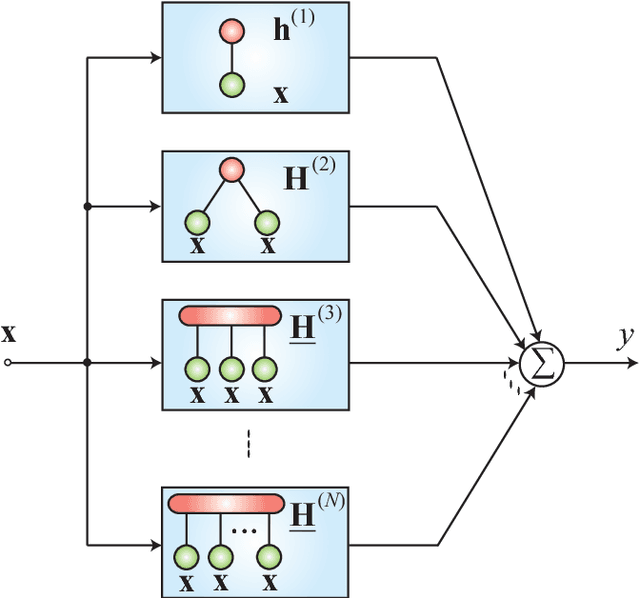
Part 2 of this monograph builds on the introduction to tensor networks and their operations presented in Part 1. It focuses on tensor network models for super-compressed higher-order representation of data/parameters and related cost functions, while providing an outline of their applications in machine learning and data analytics. A particular emphasis is on the tensor train (TT) and Hierarchical Tucker (HT) decompositions, and their physically meaningful interpretations which reflect the scalability of the tensor network approach. Through a graphical approach, we also elucidate how, by virtue of the underlying low-rank tensor approximations and sophisticated contractions of core tensors, tensor networks have the ability to perform distributed computations on otherwise prohibitively large volumes of data/parameters, thereby alleviating or even eliminating the curse of dimensionality. The usefulness of this concept is illustrated over a number of applied areas, including generalized regression and classification (support tensor machines, canonical correlation analysis, higher order partial least squares), generalized eigenvalue decomposition, Riemannian optimization, and in the optimization of deep neural networks. Part 1 and Part 2 of this work can be used either as stand-alone separate texts, or indeed as a conjoint comprehensive review of the exciting field of low-rank tensor networks and tensor decompositions.
* 232 pages