 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdo Dagan
Efficient Data Generation for Source-grounded Information-seeking Dialogs: A Use Case for Meeting Transcripts
May 02, 2024
Existing methods for creating source-grounded information-seeking dialog datasets are often costly and hard to implement due to their sole reliance on human annotators. We propose combining large language models (LLMs) prompting with human expertise for more efficient and reliable data generation. Instead of the labor-intensive Wizard-of-Oz (WOZ) method, where two annotators generate a dialog from scratch, role-playing agent and user, we use LLM generation to simulate the two roles. Annotators then verify the output and augment it with attribution data. We demonstrate our method by constructing MISeD -- Meeting Information Seeking Dialogs dataset -- the first information-seeking dialog dataset focused on meeting transcripts. Models finetuned with MISeD demonstrate superior performance on our test set, as well as on a novel fully-manual WOZ test set and an existing query-based summarization benchmark, suggesting the utility of our approach.
Attribute First, then Generate: Locally-attributable Grounded Text Generation
Apr 01, 2024Recent efforts to address hallucinations in Large Language Models (LLMs) have focused on attributed text generation, which supplements generated texts with citations of supporting sources for post-generation fact-checking and corrections. Yet, these citations often point to entire documents or paragraphs, burdening users with extensive verification work. In this paper, we introduce a locally-attributable text generation approach, prioritizing concise attributions. Our method, named ``Attribute First, then Generate'', breaks down the conventional end-to-end generation process into three intuitive steps: content selection, sentence planning, and sequential sentence generation. By initially identifying relevant source segments (``select first'') and then conditioning the generation process on them (``then generate''), we ensure these segments also act as the output's fine-grained attributions (``select'' becomes ``attribute''). Tested on Multi-document Summarization and Long-form Question-answering, our method not only yields more concise citations than the baselines but also maintains - and in some cases enhances - both generation quality and attribution accuracy. Furthermore, it significantly reduces the time required for fact verification by human assessors.
Multi-Review Fusion-in-Context
Mar 31, 2024Grounded text generation, encompassing tasks such as long-form question-answering and summarization, necessitates both content selection and content consolidation. Current end-to-end methods are difficult to control and interpret due to their opaqueness. Accordingly, recent works have proposed a modular approach, with separate components for each step. Specifically, we focus on the second subtask, of generating coherent text given pre-selected content in a multi-document setting. Concretely, we formalize Fusion-in-Context (FiC) as a standalone task, whose input consists of source texts with highlighted spans of targeted content. A model then needs to generate a coherent passage that includes all and only the target information. Our work includes the development of a curated dataset of 1000 instances in the reviews domain, alongside a novel evaluation framework for assessing the faithfulness and coverage of highlights, which strongly correlate to human judgment. Several baseline models exhibit promising outcomes and provide insightful analyses. This study lays the groundwork for further exploration of modular text generation in the multi-document setting, offering potential improvements in the quality and reliability of generated content. Our benchmark, FuseReviews, including the dataset, evaluation framework, and designated leaderboard, can be found at https://fusereviews.github.io/.
OpenAsp: A Benchmark for Multi-document Open Aspect-based Summarization
Dec 07, 2023The performance of automatic summarization models has improved dramatically in recent years. Yet, there is still a gap in meeting specific information needs of users in real-world scenarios, particularly when a targeted summary is sought, such as in the useful aspect-based summarization setting targeted in this paper. Previous datasets and studies for this setting have predominantly concentrated on a limited set of pre-defined aspects, focused solely on single document inputs, or relied on synthetic data. To advance research on more realistic scenarios, we introduce OpenAsp, a benchmark for multi-document \textit{open} aspect-based summarization. This benchmark is created using a novel and cost-effective annotation protocol, by which an open aspect dataset is derived from existing generic multi-document summarization datasets. We analyze the properties of OpenAsp showcasing its high-quality content. Further, we show that the realistic open-aspect setting realized in OpenAsp poses a challenge for current state-of-the-art summarization models, as well as for large language models.
CHAMP: Efficient Annotation and Consolidation of Cluster Hierarchies
Nov 19, 2023Various NLP tasks require a complex hierarchical structure over nodes, where each node is a cluster of items. Examples include generating entailment graphs, hierarchical cross-document coreference resolution, annotating event and subevent relations, etc. To enable efficient annotation of such hierarchical structures, we release CHAMP, an open source tool allowing to incrementally construct both clusters and hierarchy simultaneously over any type of texts. This incremental approach significantly reduces annotation time compared to the common pairwise annotation approach and also guarantees maintaining transitivity at the cluster and hierarchy levels. Furthermore, CHAMP includes a consolidation mode, where an adjudicator can easily compare multiple cluster hierarchy annotations and resolve disagreements.
Optimizing Retrieval-augmented Reader Models via Token Elimination
Oct 20, 2023Fusion-in-Decoder (FiD) is an effective retrieval-augmented language model applied across a variety of open-domain tasks, such as question answering, fact checking, etc. In FiD, supporting passages are first retrieved and then processed using a generative model (Reader), which can cause a significant bottleneck in decoding time, particularly with long outputs. In this work, we analyze the contribution and necessity of all the retrieved passages to the performance of reader models, and propose eliminating some of the retrieved information, at the token level, that might not contribute essential information to the answer generation process. We demonstrate that our method can reduce run-time by up to 62.2%, with only a 2% reduction in performance, and in some cases, even improve the performance results.
The Curious Case of Hallucinatory Unanswerablity: Finding Truths in the Hidden States of Over-Confident Large Language Models
Oct 18, 2023Large language models (LLMs) have been shown to possess impressive capabilities, while also raising crucial concerns about the faithfulness of their responses. A primary issue arising in this context is the management of unanswerable queries by LLMs, which often results in hallucinatory behavior, due to overconfidence. In this paper, we explore the behavior of LLMs when presented with unanswerable queries. We ask: do models \textbf{represent} the fact that the question is unanswerable when generating a hallucinatory answer? Our results show strong indications that such models encode the answerability of an input query, with the representation of the first decoded token often being a strong indicator. These findings shed new light on the spatial organization within the latent representations of LLMs, unveiling previously unexplored facets of these models. Moreover, they pave the way for the development of improved decoding techniques with better adherence to factual generation, particularly in scenarios where query unanswerability is a concern.
Dont Add, dont Miss: Effective Content Preserving Generation from Pre-Selected Text Spans
Oct 13, 2023The recently introduced Controlled Text Reduction (CTR) task isolates the text generation step within typical summarization-style tasks. It does so by challenging models to generate coherent text conforming to pre-selected content within the input text ("highlights"). This framing enables increased modularity in summarization-like tasks, allowing to couple a single CTR model with various content-selection setups and modules. However, there are currently no reliable CTR models, while the performance of the existing baseline for the task is mediocre, falling short of practical utility. Here, we address this gap by introducing a high-quality, open-source CTR model that tackles two prior key limitations: inadequate enforcement of the content-preservation constraint, and suboptimal silver training data. Addressing these, we amplify the content-preservation constraint in both training, via RL, and inference, via a controlled decoding strategy. Further, we substantially improve the silver training data quality via GPT-4 distillation. Overall, pairing the distilled dataset with the highlight-adherence strategies yields marked gains over the current baseline, of up to 30 ROUGE-L points, providing a reliable CTR model for downstream use.
SummHelper: Collaborative Human-Computer Summarization
Aug 16, 2023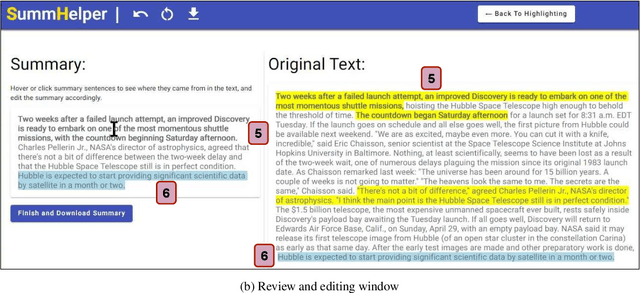
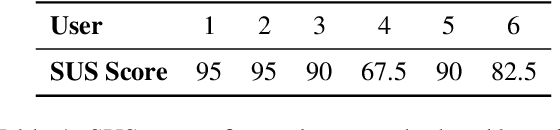
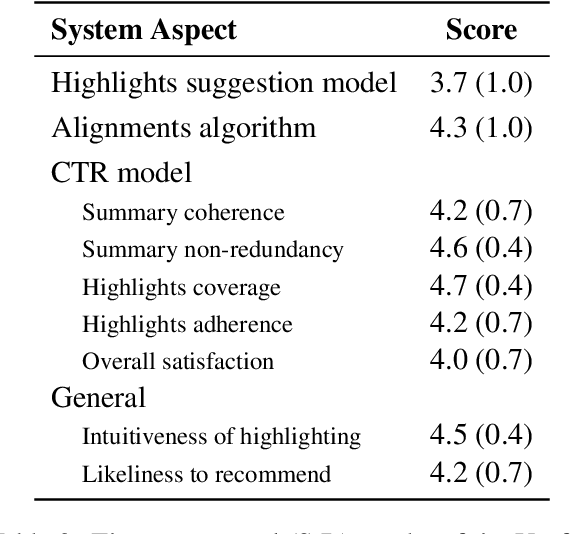

Current approaches for text summarization are predominantly automatic, with rather limited space for human intervention and control over the process. In this paper, we introduce SummHelper, a 2-phase summarization assistant designed to foster human-machine collaboration. The initial phase involves content selection, where the system recommends potential content, allowing users to accept, modify, or introduce additional selections. The subsequent phase, content consolidation, involves SummHelper generating a coherent summary from these selections, which users can then refine using visual mappings between the summary and the source text. Small-scale user studies reveal the effectiveness of our application, with participants being especially appreciative of the balance between automated guidance and opportunities for personal input.
Peek Across: Improving Multi-Document Modeling via Cross-Document Question-Answering
May 24, 2023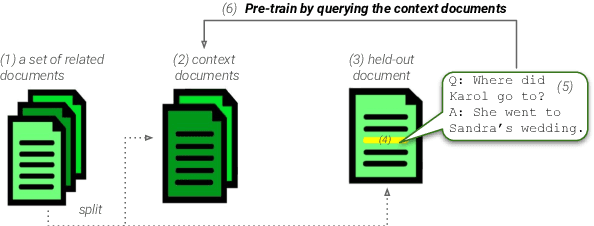
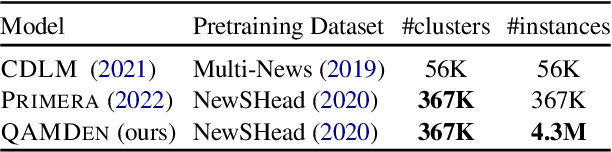
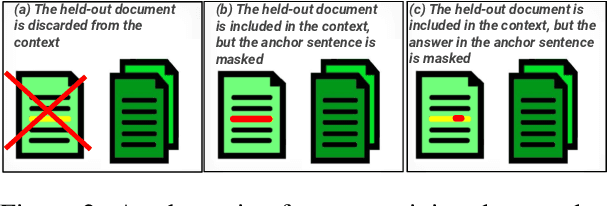
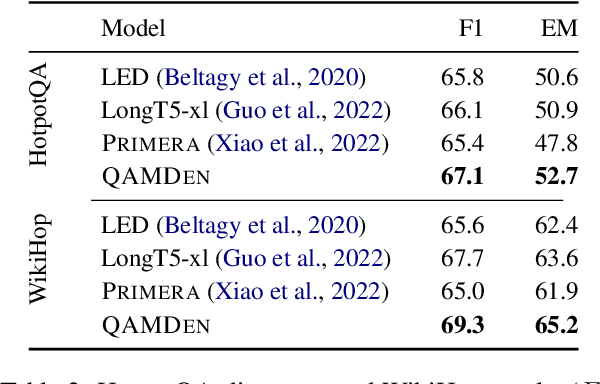
The integration of multi-document pre-training objectives into language models has resulted in remarkable improvements in multi-document downstream tasks. In this work, we propose extending this idea by pre-training a generic multi-document model from a novel cross-document question answering pre-training objective. To that end, given a set (or cluster) of topically-related documents, we systematically generate semantically-oriented questions from a salient sentence in one document and challenge the model, during pre-training, to answer these questions while "peeking" into other topically-related documents. In a similar manner, the model is also challenged to recover the sentence from which the question was generated, again while leveraging cross-document information. This novel multi-document QA formulation directs the model to better recover cross-text informational relations, and introduces a natural augmentation that artificially increases the pre-training data. Further, unlike prior multi-document models that focus on either classification or summarization tasks, our pre-training objective formulation enables the model to perform tasks that involve both short text generation (e.g., QA) and long text generation (e.g., summarization). Following this scheme, we pre-train our model -- termed QAmden -- and evaluate its performance across several multi-document tasks, including multi-document QA, summarization, and query-focused summarization, yielding improvements of up to 7%, and significantly outperforms zero-shot GPT-3.5 and GPT-4.