 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInderjit S. Dhillon
Towards Quantifying the Preconditioning Effect of Adam
Feb 11, 2024
There is a notable dearth of results characterizing the preconditioning effect of Adam and showing how it may alleviate the curse of ill-conditioning -- an issue plaguing gradient descent (GD). In this work, we perform a detailed analysis of Adam's preconditioning effect for quadratic functions and quantify to what extent Adam can mitigate the dependence on the condition number of the Hessian. Our key finding is that Adam can suffer less from the condition number but at the expense of suffering a dimension-dependent quantity. Specifically, for a $d$-dimensional quadratic with a diagonal Hessian having condition number $\kappa$, we show that the effective condition number-like quantity controlling the iteration complexity of Adam without momentum is $\mathcal{O}(\min(d, \kappa))$. For a diagonally dominant Hessian, we obtain a bound of $\mathcal{O}(\min(d \sqrt{d \kappa}, \kappa))$ for the corresponding quantity. Thus, when $d < \mathcal{O}(\kappa^p)$ where $p = 1$ for a diagonal Hessian and $p = 1/3$ for a diagonally dominant Hessian, Adam can outperform GD (which has an $\mathcal{O}(\kappa)$ dependence). On the negative side, our results suggest that Adam can be worse than GD for a sufficiently non-diagonal Hessian even if $d \ll \mathcal{O}(\kappa^{1/3})$; we corroborate this with empirical evidence. Finally, we extend our analysis to functions satisfying per-coordinate Lipschitz smoothness and a modified version of the Polyak-\L ojasiewicz condition.
Automatic Engineering of Long Prompts
Nov 16, 2023Large language models (LLMs) have demonstrated remarkable capabilities in solving complex open-domain tasks, guided by comprehensive instructions and demonstrations provided in the form of prompts. However, these prompts can be lengthy, often comprising hundreds of lines and thousands of tokens, and their design often requires considerable human effort. Recent research has explored automatic prompt engineering for short prompts, typically consisting of one or a few sentences. However, the automatic design of long prompts remains a challenging problem due to its immense search space. In this paper, we investigate the performance of greedy algorithms and genetic algorithms for automatic long prompt engineering. We demonstrate that a simple greedy approach with beam search outperforms other methods in terms of search efficiency. Moreover, we introduce two novel techniques that utilize search history to enhance the effectiveness of LLM-based mutation in our search algorithm. Our results show that the proposed automatic long prompt engineering algorithm achieves an average of 9.2% accuracy gain on eight tasks in Big Bench Hard, highlighting the significance of automating prompt designs to fully harness the capabilities of LLMs.
FINGER: Fast Inference for Graph-based Approximate Nearest Neighbor Search
Jun 22, 2022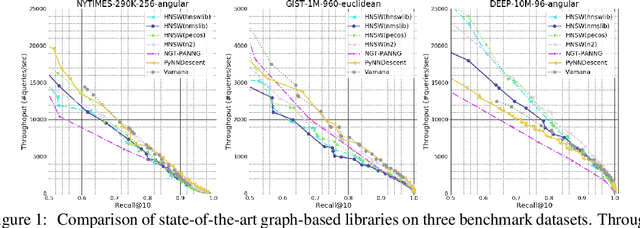
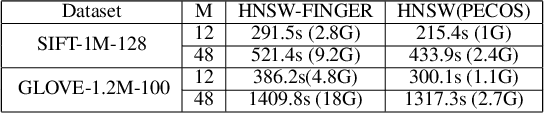
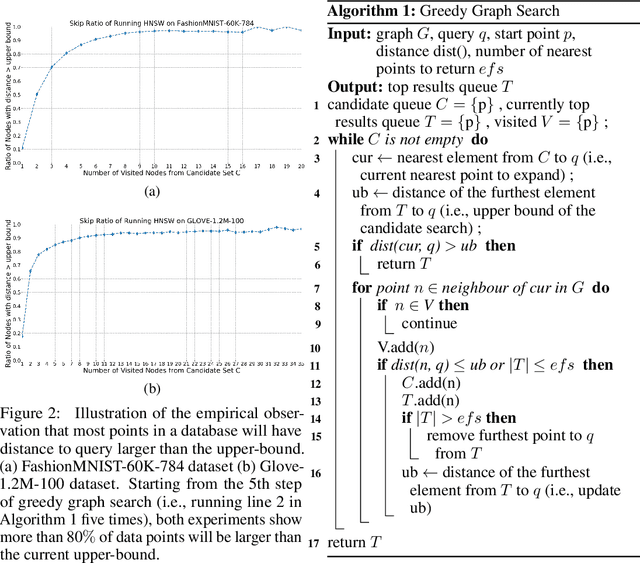
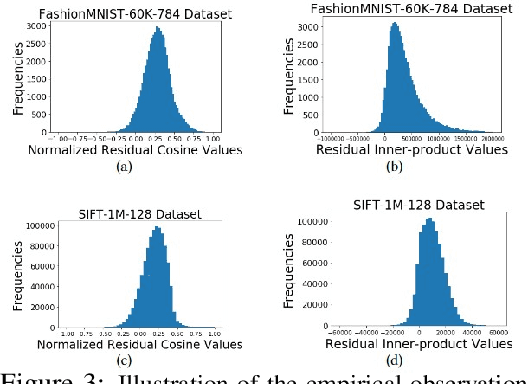
Approximate K-Nearest Neighbor Search (AKNNS) has now become ubiquitous in modern applications, for example, as a fast search procedure with two tower deep learning models. Graph-based methods for AKNNS in particular have received great attention due to their superior performance. These methods rely on greedy graph search to traverse the data points as embedding vectors in a database. Under this greedy search scheme, we make a key observation: many distance computations do not influence search updates so these computations can be approximated without hurting performance. As a result, we propose FINGER, a fast inference method to achieve efficient graph search. FINGER approximates the distance function by estimating angles between neighboring residual vectors with low-rank bases and distribution matching. The approximated distance can be used to bypass unnecessary computations, which leads to faster searches. Empirically, accelerating a popular graph-based method named HNSW by FINGER is shown to outperform existing graph-based methods by 20%-60% across different benchmark datasets.
Counterfactual Learning To Rank for Utility-Maximizing Query Autocompletion
Apr 22, 2022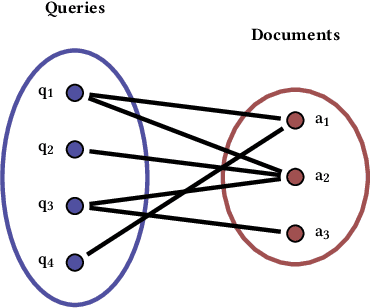

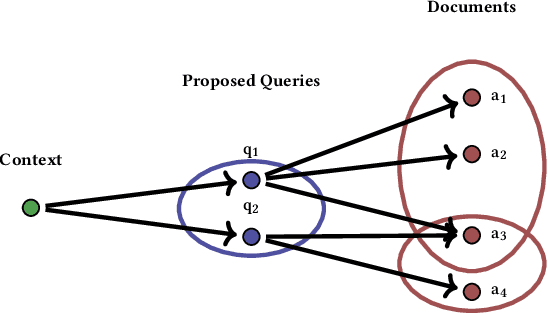
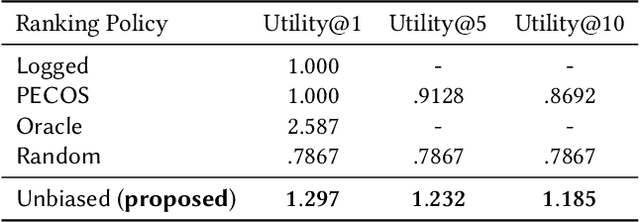
Conventional methods for query autocompletion aim to predict which completed query a user will select from a list. A shortcoming of this approach is that users often do not know which query will provide the best retrieval performance on the current information retrieval system, meaning that any query autocompletion methods trained to mimic user behavior can lead to suboptimal query suggestions. To overcome this limitation, we propose a new approach that explicitly optimizes the query suggestions for downstream retrieval performance. We formulate this as a problem of ranking a set of rankings, where each query suggestion is represented by the downstream item ranking it produces. We then present a learning method that ranks query suggestions by the quality of their item rankings. The algorithm is based on a counterfactual learning approach that is able to leverage feedback on the items (e.g., clicks, purchases) to evaluate query suggestions through an unbiased estimator, thus avoiding the assumption that users write or select optimal queries. We establish theoretical support for the proposed approach and provide learning-theoretic guarantees. We also present empirical results on publicly available datasets, and demonstrate real-world applicability using data from an online shopping store.
Sample Efficiency of Data Augmentation Consistency Regularization
Feb 24, 2022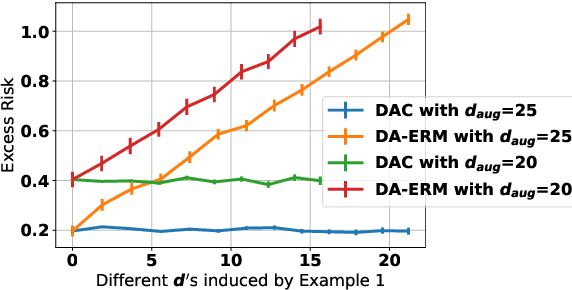

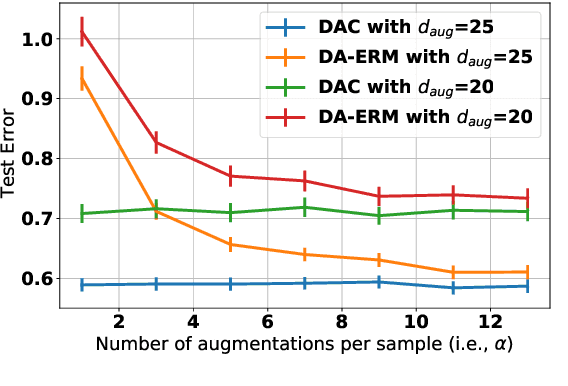

Data augmentation is popular in the training of large neural networks; currently, however, there is no clear theoretical comparison between different algorithmic choices on how to use augmented data. In this paper, we take a step in this direction - we first present a simple and novel analysis for linear regression, demonstrating that data augmentation consistency (DAC) is intrinsically more efficient than empirical risk minimization on augmented data (DA-ERM). We then propose a new theoretical framework for analyzing DAC, which reframes DAC as a way to reduce function class complexity. The new framework characterizes the sample efficiency of DAC for various non-linear models (e.g., neural networks). Further, we perform experiments that make a clean and apples-to-apples comparison (i.e., with no extra modeling or data tweaks) between ERM and consistency regularization using CIFAR-100 and WideResNet; these together demonstrate the superior efficacy of DAC.
Cluster-and-Conquer: A Framework For Time-Series Forecasting
Oct 26, 2021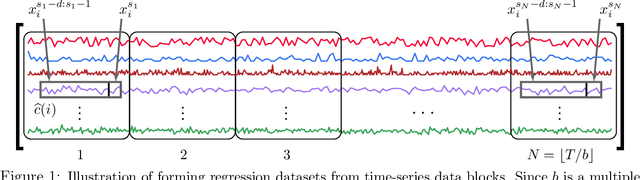
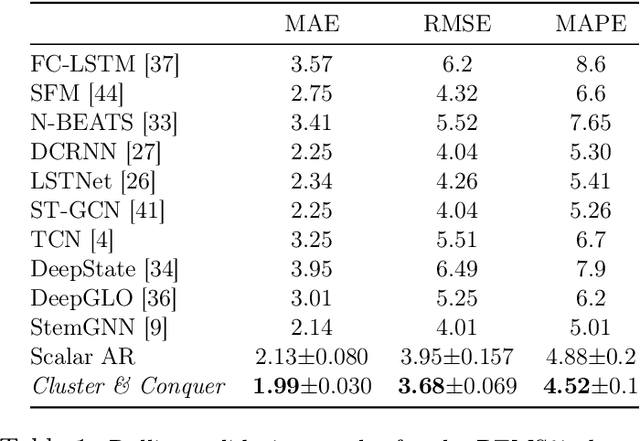
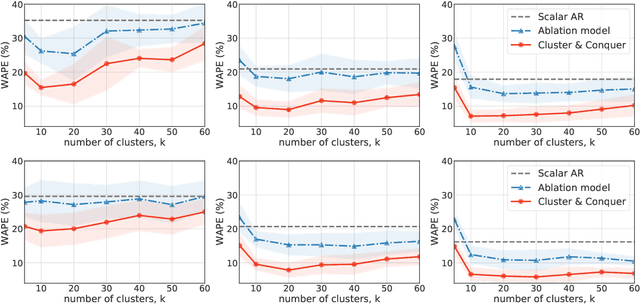
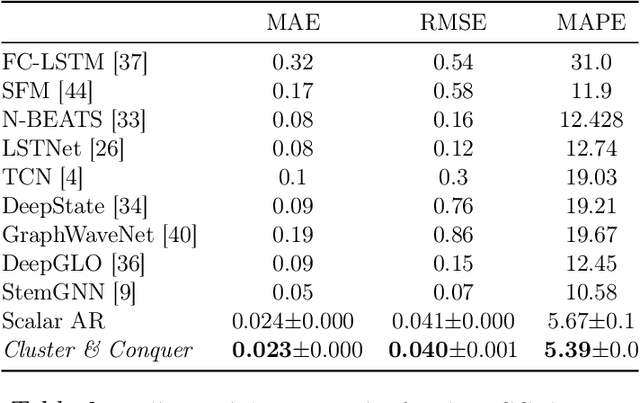
We propose a three-stage framework for forecasting high-dimensional time-series data. Our method first estimates parameters for each univariate time series. Next, we use these parameters to cluster the time series. These clusters can be viewed as multivariate time series, for which we then compute parameters. The forecasted values of a single time series can depend on the history of other time series in the same cluster, accounting for intra-cluster similarity while minimizing potential noise in predictions by ignoring inter-cluster effects. Our framework -- which we refer to as "cluster-and-conquer" -- is highly general, allowing for any time-series forecasting and clustering method to be used in each step. It is computationally efficient and embarrassingly parallel. We motivate our framework with a theoretical analysis in an idealized mixed linear regression setting, where we provide guarantees on the quality of the estimates. We accompany these guarantees with experimental results that demonstrate the advantages of our framework: when instantiated with simple linear autoregressive models, we are able to achieve state-of-the-art results on several benchmark datasets, sometimes outperforming deep-learning-based approaches.
Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification
Oct 01, 2021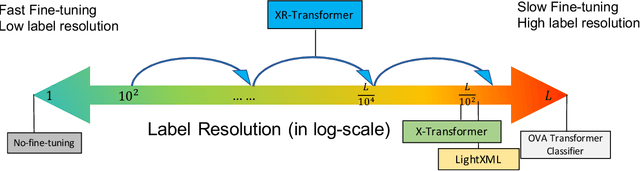
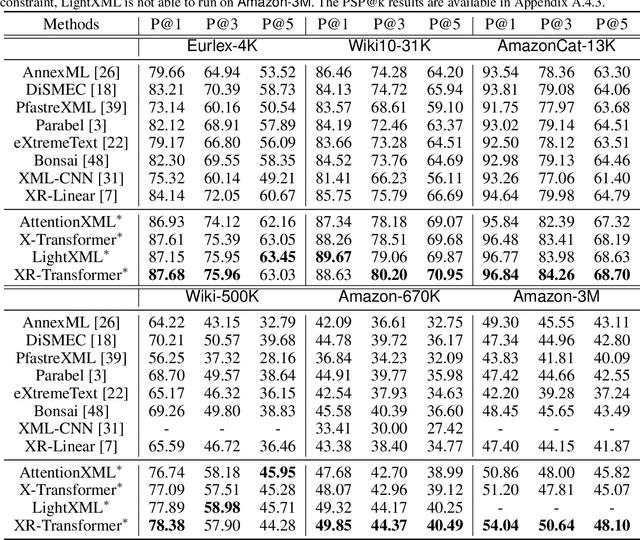

Extreme multi-label text classification (XMC) seeks to find relevant labels from an extreme large label collection for a given text input. Many real-world applications can be formulated as XMC problems, such as recommendation systems, document tagging and semantic search. Recently, transformer based XMC methods, such as X-Transformer and LightXML, have shown significant improvement over other XMC methods. Despite leveraging pre-trained transformer models for text representation, the fine-tuning procedure of transformer models on large label space still has lengthy computational time even with powerful GPUs. In this paper, we propose a novel recursive approach, XR-Transformer to accelerate the procedure through recursively fine-tuning transformer models on a series of multi-resolution objectives related to the original XMC objective function. Empirical results show that XR-Transformer takes significantly less training time compared to other transformer-based XMC models while yielding better state-of-the-art results. In particular, on the public Amazon-3M dataset with 3 million labels, XR-Transformer is not only 20x faster than X-Transformer but also improves the Precision@1 from 51% to 54%.
Label Disentanglement in Partition-based Extreme Multilabel Classification
Jun 24, 2021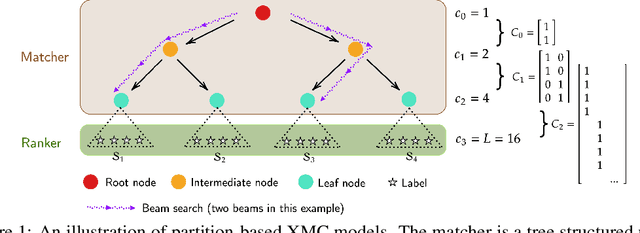
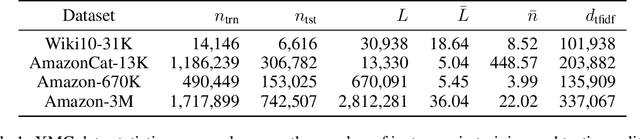
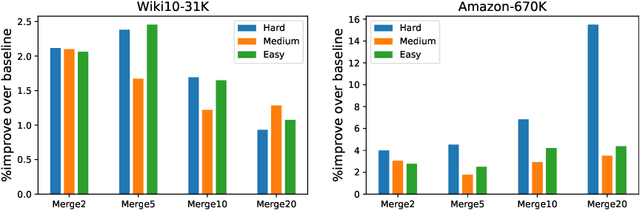
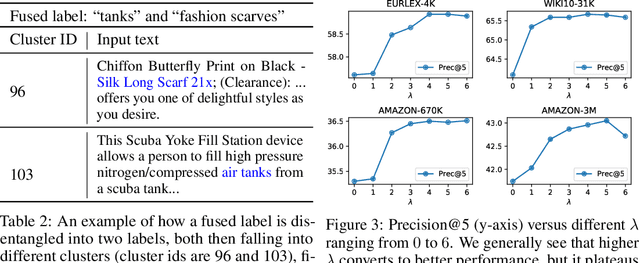
Partition-based methods are increasingly-used in extreme multi-label classification (XMC) problems due to their scalability to large output spaces (e.g., millions or more). However, existing methods partition the large label space into mutually exclusive clusters, which is sub-optimal when labels have multi-modality and rich semantics. For instance, the label "Apple" can be the fruit or the brand name, which leads to the following research question: can we disentangle these multi-modal labels with non-exclusive clustering tailored for downstream XMC tasks? In this paper, we show that the label assignment problem in partition-based XMC can be formulated as an optimization problem, with the objective of maximizing precision rates. This leads to an efficient algorithm to form flexible and overlapped label clusters, and a method that can alternatively optimizes the cluster assignments and the model parameters for partition-based XMC. Experimental results on synthetic and real datasets show that our method can successfully disentangle multi-modal labels, leading to state-of-the-art (SOTA) results on four XMC benchmarks.
Extreme Multi-label Learning for Semantic Matching in Product Search
Jun 23, 2021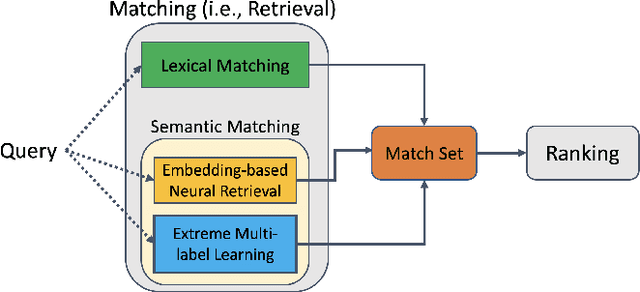

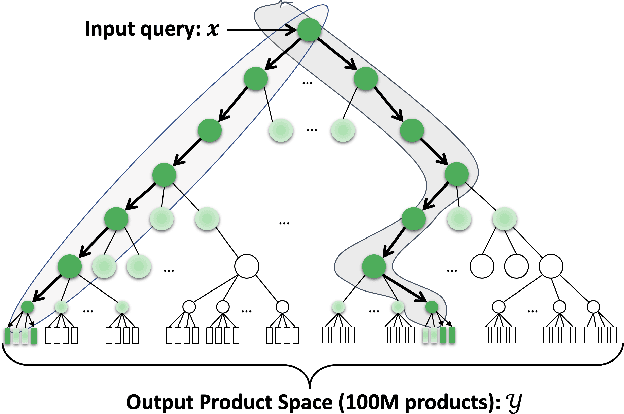
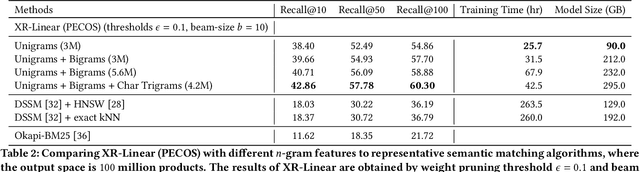
We consider the problem of semantic matching in product search: given a customer query, retrieve all semantically related products from a huge catalog of size 100 million, or more. Because of large catalog spaces and real-time latency constraints, semantic matching algorithms not only desire high recall but also need to have low latency. Conventional lexical matching approaches (e.g., Okapi-BM25) exploit inverted indices to achieve fast inference time, but fail to capture behavioral signals between queries and products. In contrast, embedding-based models learn semantic representations from customer behavior data, but the performance is often limited by shallow neural encoders due to latency constraints. Semantic product search can be viewed as an eXtreme Multi-label Classification (XMC) problem, where customer queries are input instances and products are output labels. In this paper, we aim to improve semantic product search by using tree-based XMC models where inference time complexity is logarithmic in the number of products. We consider hierarchical linear models with n-gram features for fast real-time inference. Quantitatively, our method maintains a low latency of 1.25 milliseconds per query and achieves a 65% improvement of Recall@100 (60.9% v.s. 36.8%) over a competing embedding-based DSSM model. Our model is robust to weight pruning with varying thresholds, which can flexibly meet different system requirements for online deployments. Qualitatively, our method can retrieve products that are complementary to existing product search system and add diversity to the match set.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021
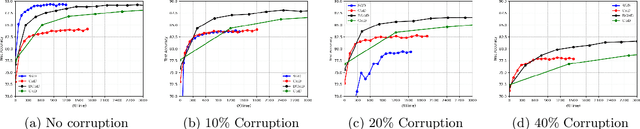
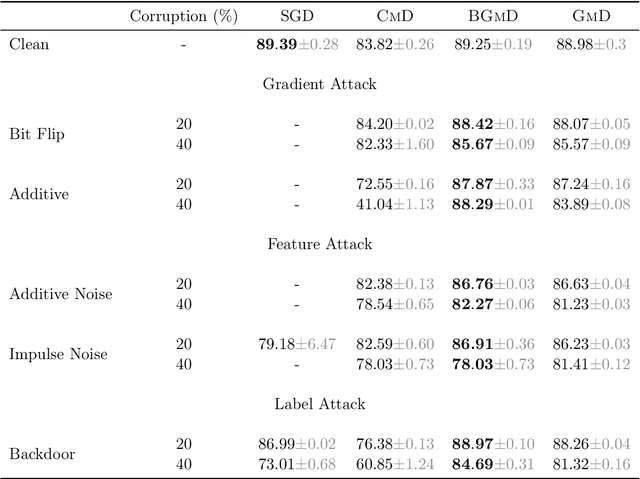
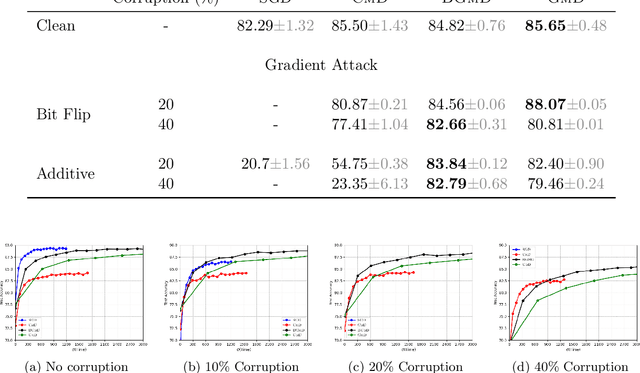
Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.