 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJagadeesh Balam
Stateful Conformer with Cache-based Inference for Streaming Automatic Speech Recognition
Jan 11, 2024
In this paper, we propose an efficient and accurate streaming speech recognition model based on the FastConformer architecture. We adapted the FastConformer architecture for streaming applications through: (1) constraining both the look-ahead and past contexts in the encoder, and (2) introducing an activation caching mechanism to enable the non-autoregressive encoder to operate autoregressively during inference. The proposed model is thoughtfully designed in a way to eliminate the accuracy disparity between the train and inference time which is common for many streaming models. Furthermore, our proposed encoder works with various decoder configurations including Connectionist Temporal Classification (CTC) and RNN-Transducer (RNNT) decoders. Additionally, we introduced a hybrid CTC/RNNT architecture which utilizes a shared encoder with both a CTC and RNNT decoder to boost the accuracy and save computation. We evaluate the proposed model on LibriSpeech dataset and a multi-domain large scale dataset and demonstrate that it can achieve better accuracy with lower latency and inference time compared to a conventional buffered streaming model baseline. We also showed that training a model with multiple latencies can achieve better accuracy than single latency models while it enables us to support multiple latencies with a single model. Our experiments also showed the hybrid architecture would not only speedup the convergence of the CTC decoder but also improves the accuracy of streaming models compared to single decoder models.
The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
Oct 18, 2023We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.
Property-Aware Multi-Speaker Data Simulation: A Probabilistic Modelling Technique for Synthetic Data Generation
Oct 18, 2023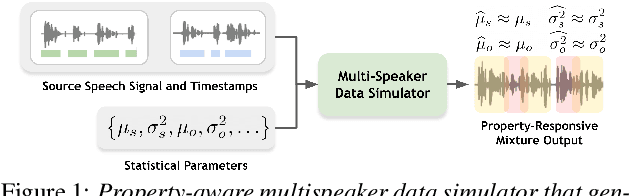
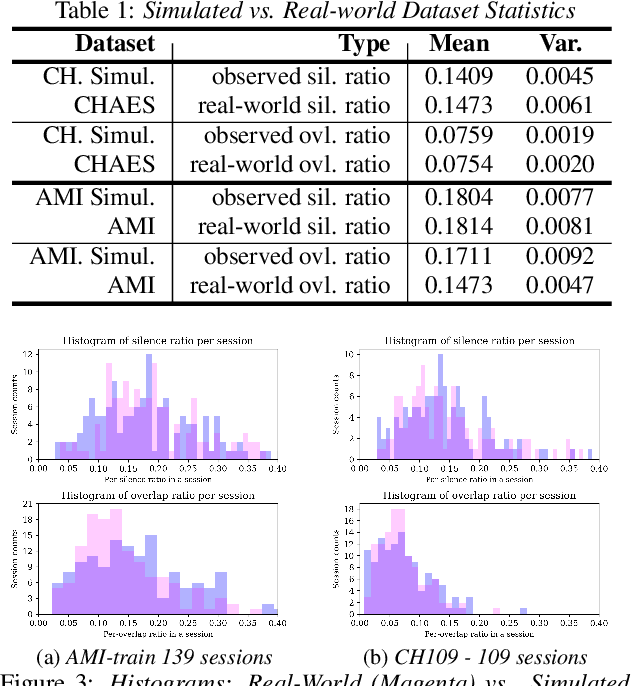
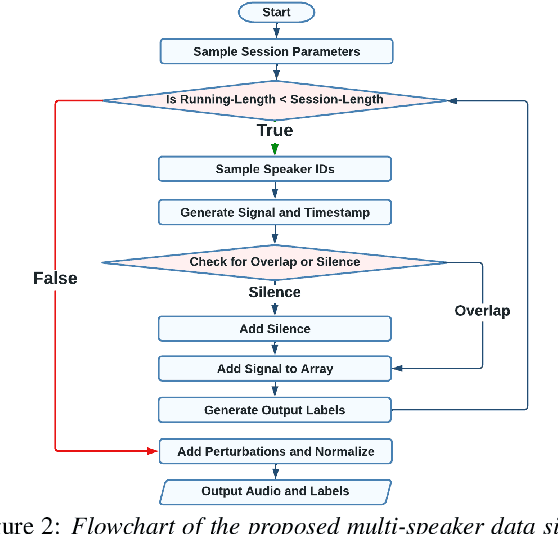
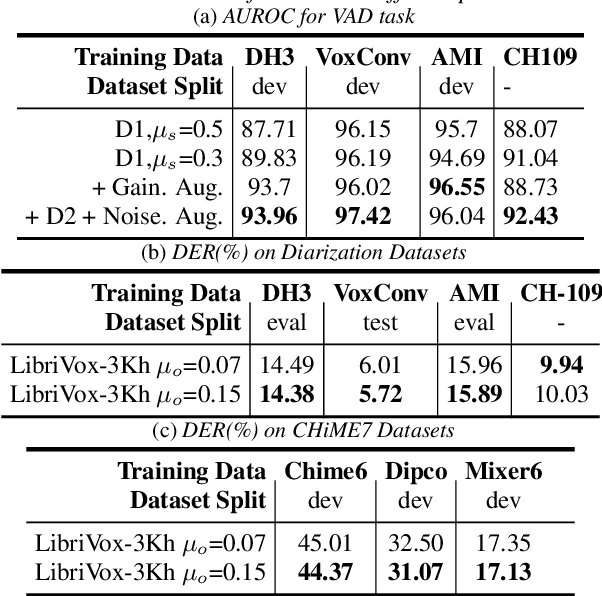
We introduce a sophisticated multi-speaker speech data simulator, specifically engineered to generate multi-speaker speech recordings. A notable feature of this simulator is its capacity to modulate the distribution of silence and overlap via the adjustment of statistical parameters. This capability offers a tailored training environment for developing neural models suited for speaker diarization and voice activity detection. The acquisition of substantial datasets for speaker diarization often presents a significant challenge, particularly in multi-speaker scenarios. Furthermore, the precise time stamp annotation of speech data is a critical factor for training both speaker diarization and voice activity detection. Our proposed multi-speaker simulator tackles these problems by generating large-scale audio mixtures that maintain statistical properties closely aligned with the input parameters. We demonstrate that the proposed multi-speaker simulator generates audio mixtures with statistical properties that closely align with the input parameters derived from real-world statistics. Additionally, we present the effectiveness of speaker diarization and voice activity detection models, which have been trained exclusively on the generated simulated datasets.
SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
Oct 13, 2023We present a novel Speech Augmented Language Model (SALM) with {\em multitask} and {\em in-context} learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST. Moreover, {\em speech supervised in-context training} is proposed to bridge the gap between LLM training and downstream speech tasks, which further boosts the in-context learning ability of speech-to-text models. Proposed model is open-sourced via NeMo toolkit.
Investigating End-to-End ASR Architectures for Long Form Audio Transcription
Sep 20, 2023
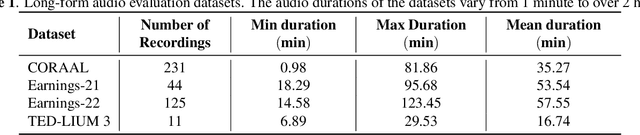


This paper presents an overview and evaluation of some of the end-to-end ASR models on long-form audios. We study three categories of Automatic Speech Recognition(ASR) models based on their core architecture: (1) convolutional, (2) convolutional with squeeze-and-excitation and (3) convolutional models with attention. We selected one ASR model from each category and evaluated Word Error Rate, maximum audio length and real-time factor for each model on a variety of long audio benchmarks: Earnings-21 and 22, CORAAL, and TED-LIUM3. The model from the category of self-attention with local attention and global token has the best accuracy comparing to other architectures. We also compared models with CTC and RNNT decoders and showed that CTC-based models are more robust and efficient than RNNT on long form audio.
Discrete Audio Representation as an Alternative to Mel-Spectrograms for Speaker and Speech Recognition
Sep 19, 2023Discrete audio representation, aka audio tokenization, has seen renewed interest driven by its potential to facilitate the application of text language modeling approaches in audio domain. To this end, various compression and representation-learning based tokenization schemes have been proposed. However, there is limited investigation into the performance of compression-based audio tokens compared to well-established mel-spectrogram features across various speaker and speech related tasks. In this paper, we evaluate compression based audio tokens on three tasks: Speaker Verification, Diarization and (Multi-lingual) Speech Recognition. Our findings indicate that (i) the models trained on audio tokens perform competitively, on average within $1\%$ of mel-spectrogram features for all the tasks considered, and do not surpass them yet. (ii) these models exhibit robustness for out-of-domain narrowband data, particularly in speaker tasks. (iii) audio tokens allow for compression to 20x compared to mel-spectrogram features with minimal loss of performance in speech and speaker related tasks, which is crucial for low bit-rate applications, and (iv) the examined Residual Vector Quantization (RVQ) based audio tokenizer exhibits a low-pass frequency response characteristic, offering a plausible explanation for the observed results, and providing insight for future tokenizer designs.
Enhancing Speaker Diarization with Large Language Models: A Contextual Beam Search Approach
Sep 14, 2023



Large language models (LLMs) have shown great promise for capturing contextual information in natural language processing tasks. We propose a novel approach to speaker diarization that incorporates the prowess of LLMs to exploit contextual cues in human dialogues. Our method builds upon an acoustic-based speaker diarization system by adding lexical information from an LLM in the inference stage. We model the multi-modal decoding process probabilistically and perform joint acoustic and lexical beam search to incorporate cues from both modalities: audio and text. Our experiments demonstrate that infusing lexical knowledge from the LLM into an acoustics-only diarization system improves overall speaker-attributed word error rate (SA-WER). The experimental results show that LLMs can provide complementary information to acoustic models for the speaker diarization task via proposed beam search decoding approach showing up to 39.8% relative delta-SA-WER improvement from the baseline system. Thus, we substantiate that the proposed technique is able to exploit contextual information that is inaccessible to acoustics-only systems which is represented by speaker embeddings. In addition, these findings point to the potential of using LLMs to improve speaker diarization and other speech processing tasks by capturing semantic and contextual cues.
Leveraging Pretrained ASR Encoders for Effective and Efficient End-to-End Speech Intent Classification and Slot Filling
Jul 13, 2023



We study speech intent classification and slot filling (SICSF) by proposing to use an encoder pretrained on speech recognition (ASR) to initialize an end-to-end (E2E) Conformer-Transformer model, which achieves the new state-of-the-art results on the SLURP dataset, with 90.14% intent accuracy and 82.27% SLURP-F1. We compare our model with encoders pretrained on self-supervised learning (SSL), and show that ASR pretraining is much more effective than SSL for SICSF. To explore parameter efficiency, we freeze the encoder and add Adapter modules, and show that parameter efficiency is only achievable with an ASR-pretrained encoder, while the SSL encoder needs full finetuning to achieve comparable results. In addition, we provide an in-depth comparison on end-to-end models versus cascading models (ASR+NLU), and show that E2E models are better than cascaded models unless an oracle ASR model is provided. Last but not least, our model is the first E2E model that achieves the same performance as cascading models with oracle ASR. Code, checkpoints and configs are available.
AmberNet: A Compact End-to-End Model for Spoken Language Identification
Oct 27, 2022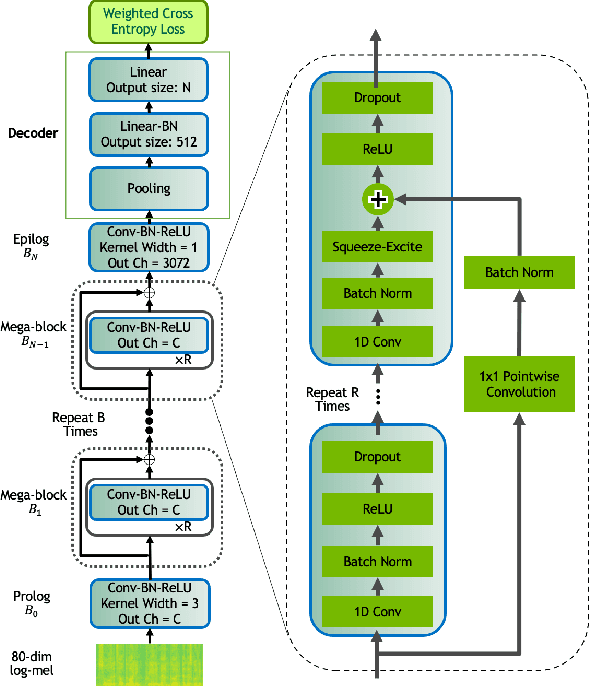
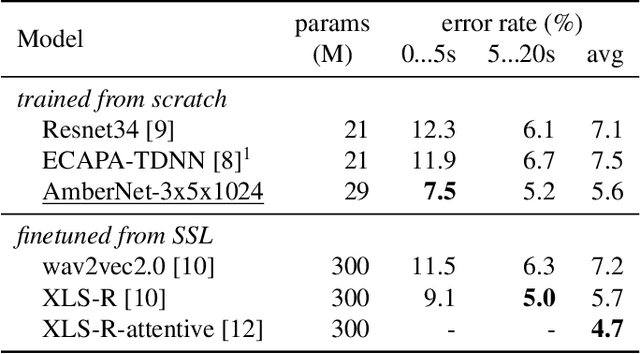
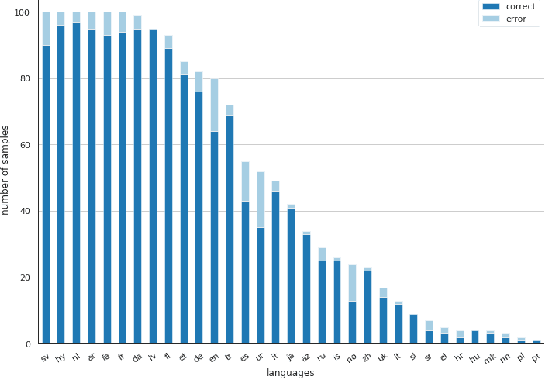

We present AmberNet, a compact end-to-end neural network for Spoken Language Identification. AmberNet consists of 1D depth-wise separable convolutions and Squeeze-and-Excitation layers with global context, followed by statistics pooling and linear layers. AmberNet achieves performance similar to state-of-the-art(SOTA) models on VoxLingua107 dataset, while being 10x smaller. AmberNet can be adapted to unseen languages and new acoustic conditions with simple finetuning. It attains SOTA accuracy of 75.8% on FLEURS benchmark. We show the model is easily scalable to achieve a better trade-off between accuracy and speed. We further inspect the model's sensitivity to input length and show that AmberNet performs well even on short utterances.
Multi-scale Speaker Diarization with Dynamic Scale Weighting
Mar 30, 2022



Speaker diarization systems are challenged by a trade-off between the temporal resolution and the fidelity of the speaker representation. By obtaining a superior temporal resolution with an enhanced accuracy, a multi-scale approach is a way to cope with such a trade-off. In this paper, we propose a more advanced multi-scale diarization system based on a multi-scale diarization decoder. There are two main contributions in this study that significantly improve the diarization performance. First, we use multi-scale clustering as an initialization to estimate the number of speakers and obtain the average speaker representation vector for each speaker and each scale. Next, we propose the use of 1-D convolutional neural networks that dynamically determine the importance of each scale at each time step. To handle a variable number of speakers and overlapping speech, the proposed system can estimate the number of existing speakers. Our proposed system achieves a state-of-art performance on the CALLHOME and AMI MixHeadset datasets, with 3.92% and 1.05% diarization error rates, respectively.