 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJake Fawkes
Results on Counterfactual Invariance
Jul 17, 2023
In this paper we provide a theoretical analysis of counterfactual invariance. We present a variety of existing definitions, study how they relate to each other and what their graphical implications are. We then turn to the current major question surrounding counterfactual invariance, how does it relate to conditional independence? We show that whilst counterfactual invariance implies conditional independence, conditional independence does not give any implications about the degree or likelihood of satisfying counterfactual invariance. Furthermore, we show that for discrete causal models counterfactually invariant functions are often constrained to be functions of particular variables, or even constant.
Returning The Favour: When Regression Benefits From Probabilistic Causal Knowledge
Jan 26, 2023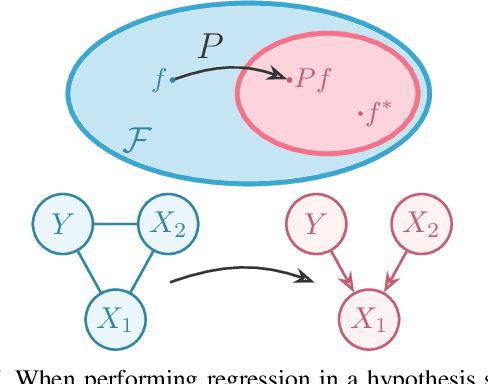
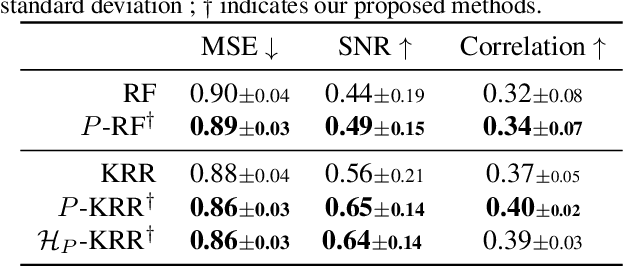

A directed acyclic graph (DAG) provides valuable prior knowledge that is often discarded in regression tasks in machine learning. We show that the independences arising from the presence of collider structures in DAGs provide meaningful inductive biases, which constrain the regression hypothesis space and improve predictive performance. We introduce collider regression, a framework to incorporate probabilistic causal knowledge from a collider in a regression problem. When the hypothesis space is a reproducing kernel Hilbert space, we prove a strictly positive generalisation benefit under mild assumptions and provide closed-form estimators of the empirical risk minimiser. Experiments on synthetic and climate model data demonstrate performance gains of the proposed methodology.
Doubly Robust Kernel Statistics for Testing Distributional Treatment Effects Even Under One Sided Overlap
Dec 09, 2022
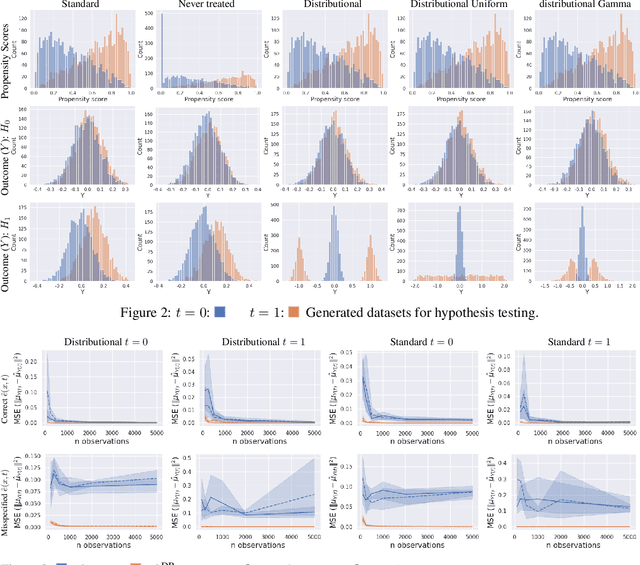

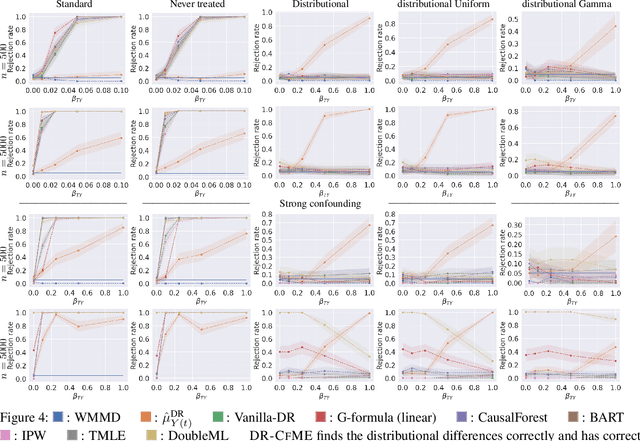
As causal inference becomes more widespread the importance of having good tools to test for causal effects increases. In this work we focus on the problem of testing for causal effects that manifest in a difference in distribution for treatment and control. We build on work applying kernel methods to causality, considering the previously introduced Counterfactual Mean Embedding framework (\textsc{CfME}). We improve on this by proposing the \emph{Doubly Robust Counterfactual Mean Embedding} (\textsc{DR-CfME}), which has better theoretical properties than its predecessor by leveraging semiparametric theory. This leads us to propose new kernel based test statistics for distributional effects which are based upon doubly robust estimators of treatment effects. We propose two test statistics, one which is a direct improvement on previous work and one which can be applied even when the support of the treatment arm is a subset of that of the control arm. We demonstrate the validity of our methods on simulated and real-world data, as well as giving an application in off-policy evaluation.
Selection, Ignorability and Challenges With Causal Fairness
Mar 02, 2022


In this paper we look at popular fairness methods that use causal counterfactuals. These methods capture the intuitive notion that a prediction is fair if it coincides with the prediction that would have been made if someone's race, gender or religion were counterfactually different. In order to achieve this, we must have causal models that are able to capture what someone would be like if we were to counterfactually change these traits. However, we argue that any model that can do this must lie outside the particularly well behaved class that is commonly considered in the fairness literature. This is because in fairness settings, models in this class entail a particularly strong causal assumption, normally only seen in a randomised controlled trial. We argue that in general this is unlikely to hold. Furthermore, we show in many cases it can be explicitly rejected due to the fact that samples are selected from a wider population. We show this creates difficulties for counterfactual fairness as well as for the application of more general causal fairness methods.