 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJames Steven Supancic III
Tracking as Online Decision-Making: Learning a Policy from Streaming Videos with Reinforcement Learning
Jul 17, 2017

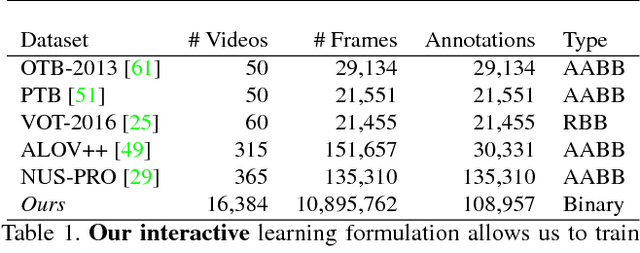
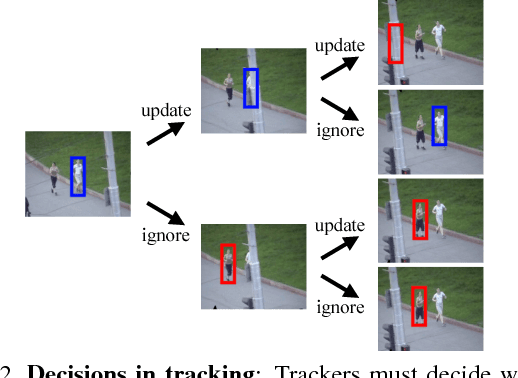
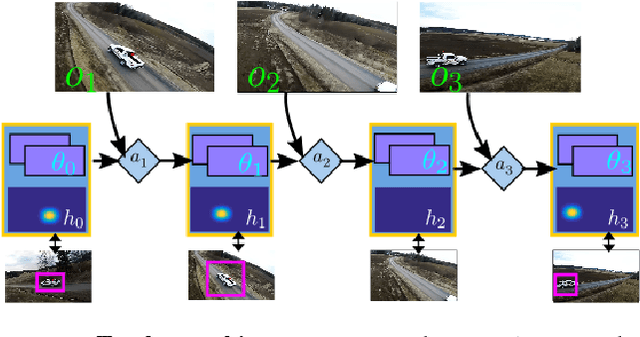
We formulate tracking as an online decision-making process, where a tracking agent must follow an object despite ambiguous image frames and a limited computational budget. Crucially, the agent must decide where to look in the upcoming frames, when to reinitialize because it believes the target has been lost, and when to update its appearance model for the tracked object. Such decisions are typically made heuristically. Instead, we propose to learn an optimal decision-making policy by formulating tracking as a partially observable decision-making process (POMDP). We learn policies with deep reinforcement learning algorithms that need supervision (a reward signal) only when the track has gone awry. We demonstrate that sparse rewards allow us to quickly train on massive datasets, several orders of magnitude more than past work. Interestingly, by treating the data source of Internet videos as unlimited streams, we both learn and evaluate our trackers in a single, unified computational stream.
Depth-based hand pose estimation: methods, data, and challenges
May 06, 2015
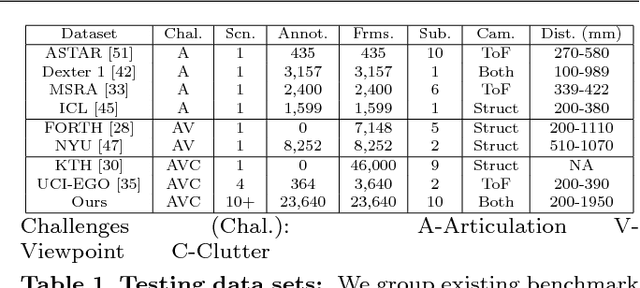


Hand pose estimation has matured rapidly in recent years. The introduction of commodity depth sensors and a multitude of practical applications have spurred new advances. We provide an extensive analysis of the state-of-the-art, focusing on hand pose estimation from a single depth frame. To do so, we have implemented a considerable number of systems, and will release all software and evaluation code. We summarize important conclusions here: (1) Pose estimation appears roughly solved for scenes with isolated hands. However, methods still struggle to analyze cluttered scenes where hands may be interacting with nearby objects and surfaces. To spur further progress we introduce a challenging new dataset with diverse, cluttered scenes. (2) Many methods evaluate themselves with disparate criteria, making comparisons difficult. We define a consistent evaluation criteria, rigorously motivated by human experiments. (3) We introduce a simple nearest-neighbor baseline that outperforms most existing systems. This implies that most systems do not generalize beyond their training sets. This also reinforces the under-appreciated point that training data is as important as the model itself. We conclude with directions for future progress.