 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJannik Peters
Proportional Fairness in Clustering: A Social Choice Perspective
Oct 27, 2023
We study the proportional clustering problem of Chen et al. [ICML'19] and relate it to the area of multiwinner voting in computational social choice. We show that any clustering satisfying a weak proportionality notion of Brill and Peters [EC'23] simultaneously obtains the best known approximations to the proportional fairness notion of Chen et al. [ICML'19], but also to individual fairness [Jung et al., FORC'20] and the "core" [Li et al. ICML'21]. In fact, we show that any approximation to proportional fairness is also an approximation to individual fairness and vice versa. Finally, we also study stronger notions of proportional representation, in which deviations do not only happen to single, but multiple candidate centers, and show that stronger proportionality notions of Brill and Peters [EC'23] imply approximations to these stronger guarantees.
schlably: A Python Framework for Deep Reinforcement Learning Based Scheduling Experiments
Jan 10, 2023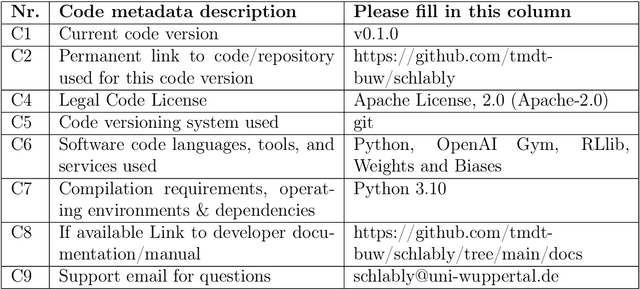
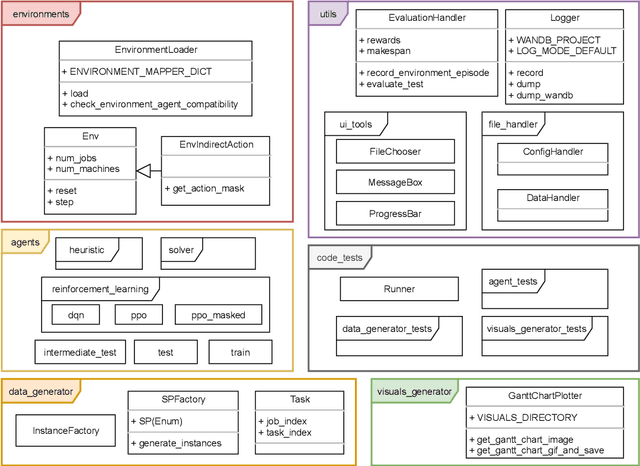
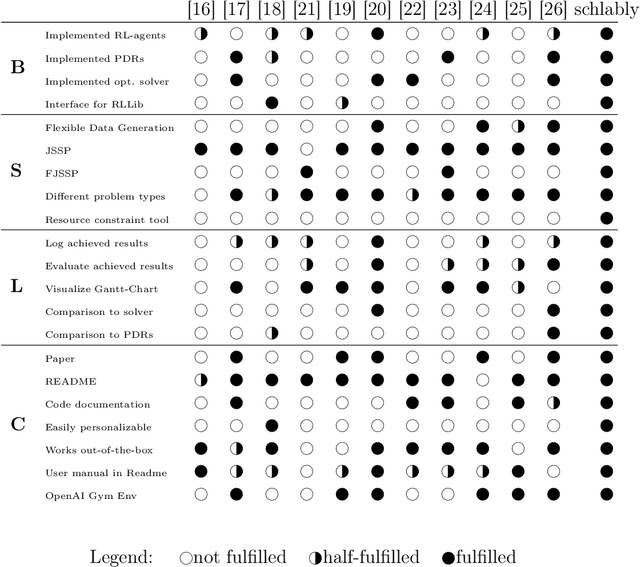
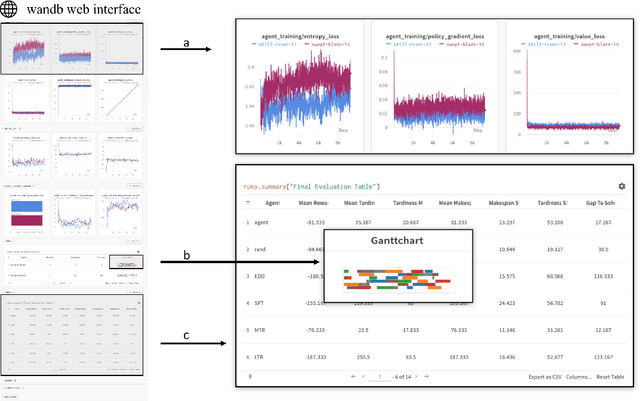
Research on deep reinforcement learning (DRL) based production scheduling (PS) has gained a lot of attention in recent years, primarily due to the high demand for optimizing scheduling problems in diverse industry settings. Numerous studies are carried out and published as stand-alone experiments that often vary only slightly with respect to problem setups and solution approaches. The programmatic core of these experiments is typically very similar. Despite this fact, no standardized and resilient framework for experimentation on PS problems with DRL algorithms could be established so far. In this paper, we introduce schlably, a Python-based framework that provides researchers a comprehensive toolset to facilitate the development of PS solution strategies based on DRL. schlably eliminates the redundant overhead work that the creation of a sturdy and flexible backbone requires and increases the comparability and reusability of conducted research work.
Maps for Learning Indexable Classes
Oct 15, 2020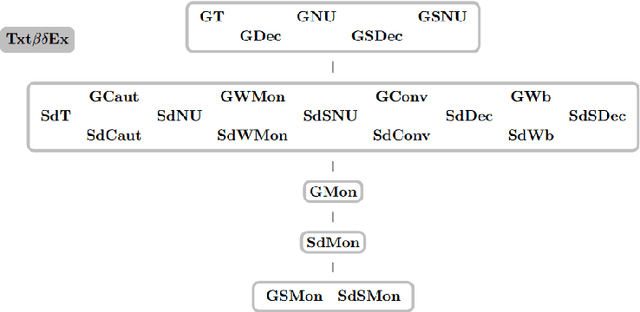
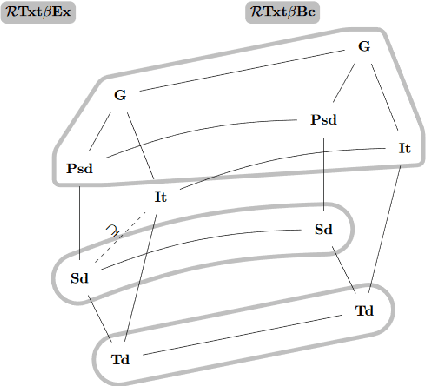
We study learning of indexed families from positive data where a learner can freely choose a hypothesis space (with uniformly decidable membership) comprising at least the languages to be learned. This abstracts a very universal learning task which can be found in many areas, for example learning of (subsets of) regular languages or learning of natural languages. We are interested in various restrictions on learning, such as consistency, conservativeness or set-drivenness, exemplifying various natural learning restrictions. Building on previous results from the literature, we provide several maps (depictions of all pairwise relations) of various groups of learning criteria, including a map for monotonicity restrictions and similar criteria and a map for restrictions on data presentation. Furthermore, we consider, for various learning criteria, whether learners can be assumed consistent.