 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJason Choi
Generate-then-Retrieve: Intent-Aware FAQ Retrieval in Product Search
Jun 06, 2023
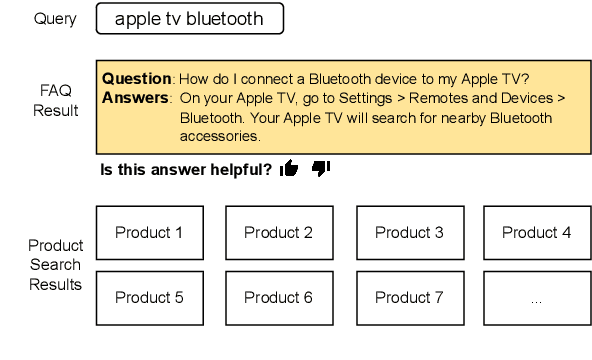
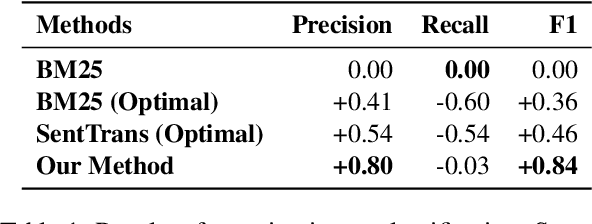
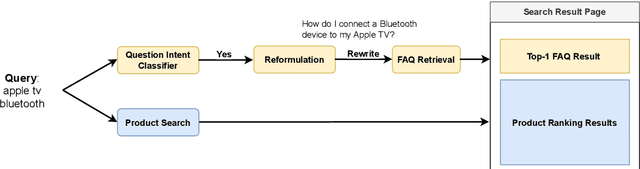

Customers interacting with product search engines are increasingly formulating information-seeking queries. Frequently Asked Question (FAQ) retrieval aims to retrieve common question-answer pairs for a user query with question intent. Integrating FAQ retrieval in product search can not only empower users to make more informed purchase decisions, but also enhance user retention through efficient post-purchase support. Determining when an FAQ entry can satisfy a user's information need within product search, without disrupting their shopping experience, represents an important challenge. We propose an intent-aware FAQ retrieval system consisting of (1) an intent classifier that predicts when a user's information need can be answered by an FAQ; (2) a reformulation model that rewrites a query into a natural question. Offline evaluation demonstrates that our approach improves Hit@1 by 13% on retrieving ground-truth FAQs, while reducing latency by 95% compared to baseline systems. These improvements are further validated by real user feedback, where 71% of displayed FAQs on top of product search results received explicit positive user feedback. Overall, our findings show promising directions for integrating FAQ retrieval into product search at scale.
Ericson: An Interactive Open-Domain Conversational Search Agent
Apr 05, 2023
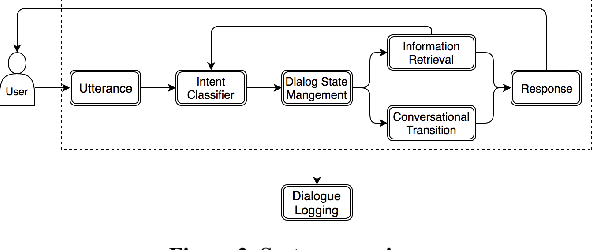

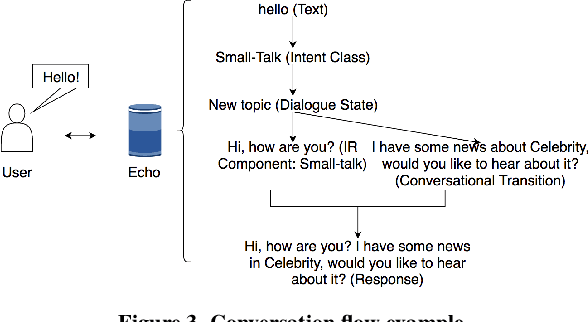
Open-domain conversational search (ODCS) aims to provide valuable, up-to-date information, while maintaining natural conversations to help users refine and ultimately answer information needs. However, creating an effective and robust ODCS agent is challenging. In this paper, we present a fully functional ODCS system, Ericson, which includes state-of-the-art question answering and information retrieval components, as well as intent inference and dialogue management models for proactive question refinement and recommendations. Our system was stress-tested in the Amazon Alexa Prize, by engaging in live conversations with thousands of Alexa users, thus providing empirical basis for the analysis of the ODCS system in real settings. Our interaction data analysis revealed that accurate intent classification, encouraging user engagement, and careful proactive recommendations contribute most to the users satisfaction. Our study further identifies limitations of the existing search techniques, and can serve as a building block for the next generation of ODCS agents.
Lyapunov Density Models: Constraining Distribution Shift in Learning-Based Control
Jun 21, 2022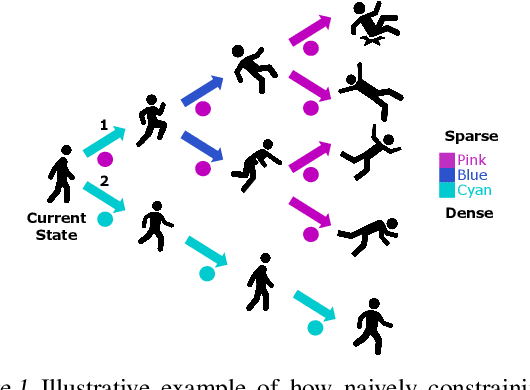
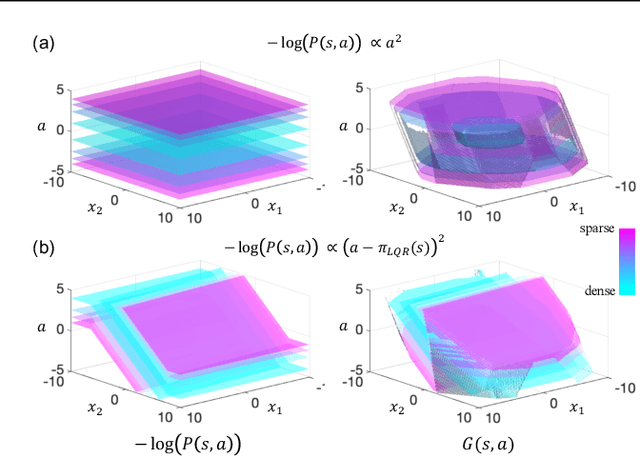
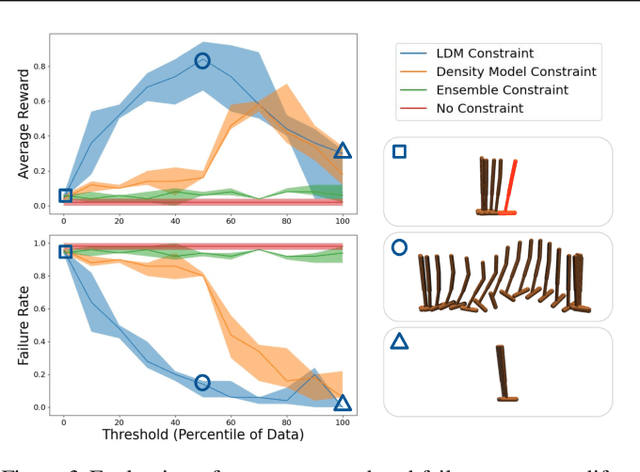
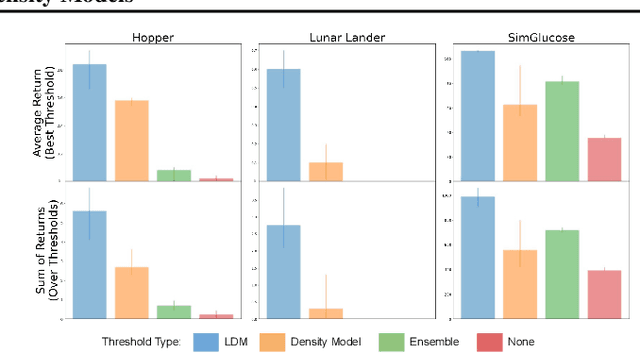
Learned models and policies can generalize effectively when evaluated within the distribution of the training data, but can produce unpredictable and erroneous outputs on out-of-distribution inputs. In order to avoid distribution shift when deploying learning-based control algorithms, we seek a mechanism to constrain the agent to states and actions that resemble those that it was trained on. In control theory, Lyapunov stability and control-invariant sets allow us to make guarantees about controllers that stabilize the system around specific states, while in machine learning, density models allow us to estimate the training data distribution. Can we combine these two concepts, producing learning-based control algorithms that constrain the system to in-distribution states using only in-distribution actions? In this work, we propose to do this by combining concepts from Lyapunov stability and density estimation, introducing Lyapunov density models: a generalization of control Lyapunov functions and density models that provides guarantees on an agent's ability to stay in-distribution over its entire trajectory.
Reinforcement Learning for Safety-Critical Control under Model Uncertainty, using Control Lyapunov Functions and Control Barrier Functions
Apr 16, 2020

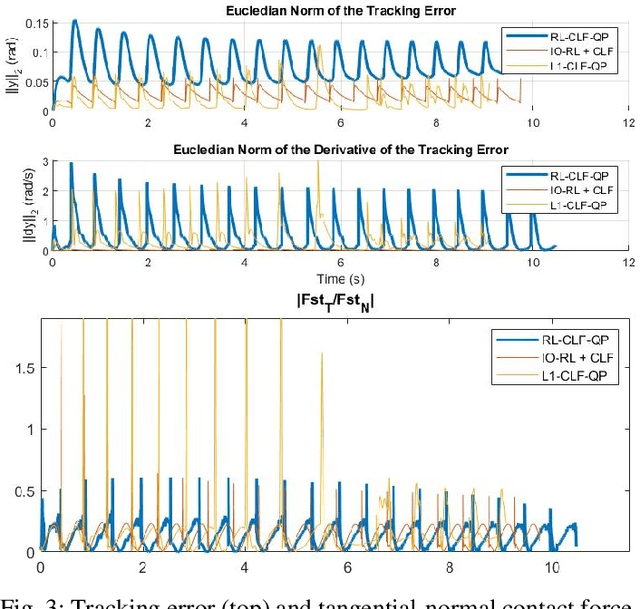
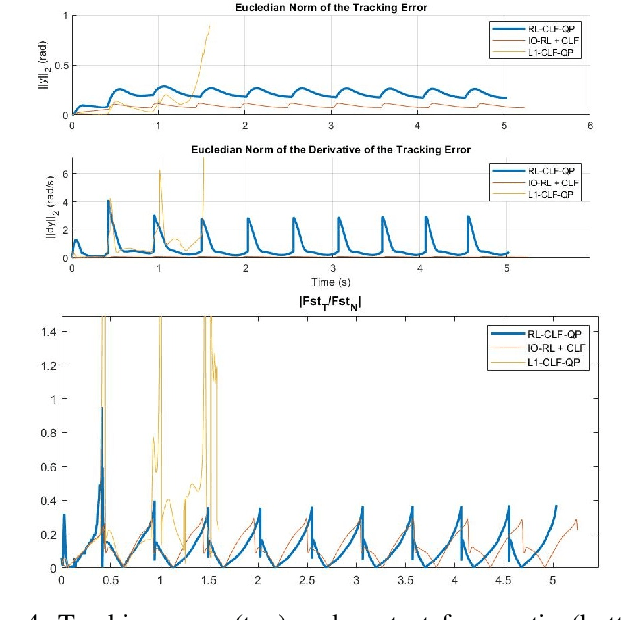
In this paper, the issue of model uncertainty in safety-critical control is addressed with a data-driven approach. For this purpose, we utilize a structure of an input-ouput linearization controller based on a nominal model, and Control Barrier Function (CBF) and Control Lyapunov Function (CLF)-based control methods. Specifically, a novel Reinforcement Learning framework which learns the model uncertainty in CBF and CLF constraints, as well as other dynamic constraints is proposed. The trained policy is combined with the nominal model-based CBF-CLF-QP, resulting in the Reinforcement Learning based CBF-CLF-QP (RL-CBF-CLF-QP), which now addresses the problem of uncertainty in the safety constraints. The performance of the proposed method is validated by testing it on an underactuated nonlinear bipedal robot walking on randomly spaced stepping stones with one step preview.