 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJason Wolfe
ZEROTOP: Zero-Shot Task-Oriented Semantic Parsing using Large Language Models
Dec 21, 2022
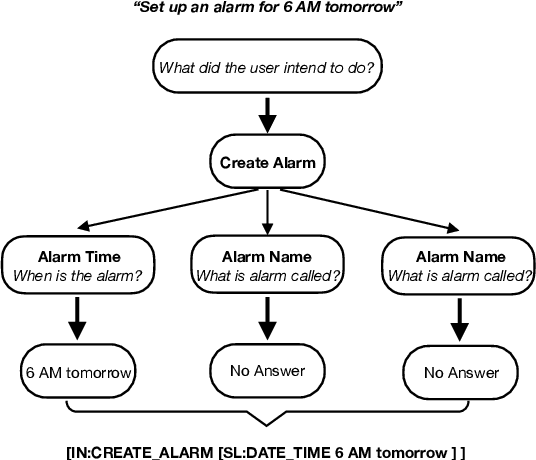

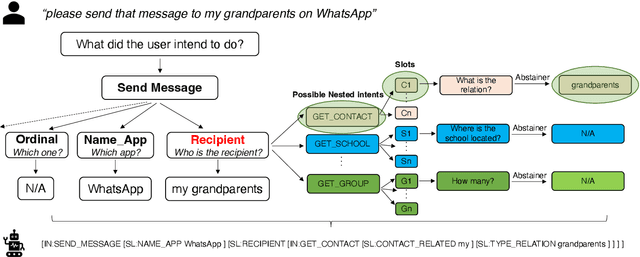
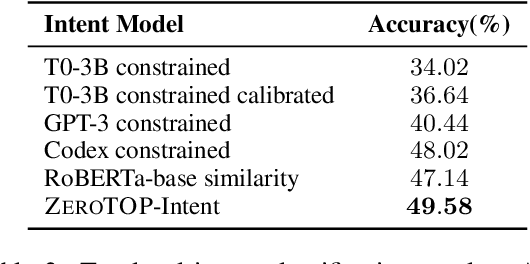
We explore the use of large language models (LLMs) for zero-shot semantic parsing. Semantic parsing involves mapping natural language utterances to task-specific meaning representations. Language models are generally trained on the publicly available text and code and cannot be expected to directly generalize to domain-specific parsing tasks in a zero-shot setting. In this work, we propose ZEROTOP, a zero-shot task-oriented parsing method that decomposes a semantic parsing problem into a set of abstractive and extractive question-answering (QA) problems, enabling us to leverage the ability of LLMs to zero-shot answer reading comprehension questions. For each utterance, we prompt the LLM with questions corresponding to its top-level intent and a set of slots and use the LLM generations to construct the target meaning representation. We observe that current LLMs fail to detect unanswerable questions; and as a result, cannot handle questions corresponding to missing slots. To address this problem, we fine-tune a language model on public QA datasets using synthetic negative samples. Experimental results show that our QA-based decomposition paired with the fine-tuned LLM can correctly parse ~16% of utterances in the MTOP dataset without requiring any annotated data.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.