 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJean Rabault
Opportunities for machine learning in scientific discovery
May 07, 2024
Technological advancements have substantially increased computational power and data availability, enabling the application of powerful machine-learning (ML) techniques across various fields. However, our ability to leverage ML methods for scientific discovery, {\it i.e.} to obtain fundamental and formalized knowledge about natural processes, is still in its infancy. In this review, we explore how the scientific community can increasingly leverage ML techniques to achieve scientific discoveries. We observe that the applicability and opportunity of ML depends strongly on the nature of the problem domain, and whether we have full ({\it e.g.}, turbulence), partial ({\it e.g.}, computational biochemistry), or no ({\it e.g.}, neuroscience) {\it a-priori} knowledge about the governing equations and physical properties of the system. Although challenges remain, principled use of ML is opening up new avenues for fundamental scientific discoveries. Throughout these diverse fields, there is a theme that ML is enabling researchers to embrace complexity in observational data that was previously intractable to classic analysis and numerical investigations.
Active flow control for three-dimensional cylinders through deep reinforcement learning
Sep 04, 2023



This paper presents for the first time successful results of active flow control with multiple independently controlled zero-net-mass-flux synthetic jets. The jets are placed on a three-dimensional cylinder along its span with the aim of reducing the drag coefficient. The method is based on a deep-reinforcement-learning framework that couples a computational-fluid-dynamics solver with an agent using the proximal-policy-optimization algorithm. We implement a multi-agent reinforcement-learning framework which offers numerous advantages: it exploits local invariants, makes the control adaptable to different geometries, facilitates transfer learning and cross-application of agents and results in significant training speedup. In this contribution we report significant drag reduction after applying the DRL-based control in three different configurations of the problem.
Effective control of two-dimensional Rayleigh--Bénard convection: invariant multi-agent reinforcement learning is all you need
Apr 05, 2023



Rayleigh-B\'enard convection (RBC) is a recurrent phenomenon in several industrial and geoscience flows and a well-studied system from a fundamental fluid-mechanics viewpoint. However, controlling RBC, for example by modulating the spatial distribution of the bottom-plate heating in the canonical RBC configuration, remains a challenging topic for classical control-theory methods. In the present work, we apply deep reinforcement learning (DRL) for controlling RBC. We show that effective RBC control can be obtained by leveraging invariant multi-agent reinforcement learning (MARL), which takes advantage of the locality and translational invariance inherent to RBC flows inside wide channels. The MARL framework applied to RBC allows for an increase in the number of control segments without encountering the curse of dimensionality that would result from a naive increase in the DRL action-size dimension. This is made possible by the MARL ability for re-using the knowledge generated in different parts of the RBC domain. We show in a case study that MARL DRL is able to discover an advanced control strategy that destabilizes the spontaneous RBC double-cell pattern, changes the topology of RBC by coalescing adjacent convection cells, and actively controls the resulting coalesced cell to bring it to a new stable configuration. This modified flow configuration results in reduced convective heat transfer, which is beneficial in several industrial processes. Therefore, our work both shows the potential of MARL DRL for controlling large RBC systems, as well as demonstrates the possibility for DRL to discover strategies that move the RBC configuration between different topological configurations, yielding desirable heat-transfer characteristics. These results are useful for both gaining further understanding of the intrinsic properties of RBC, as well as for developing industrial applications.
Comparative analysis of machine learning methods for active flow control
Feb 25, 2022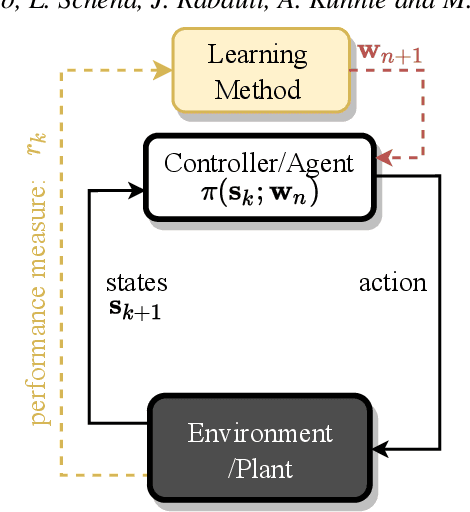

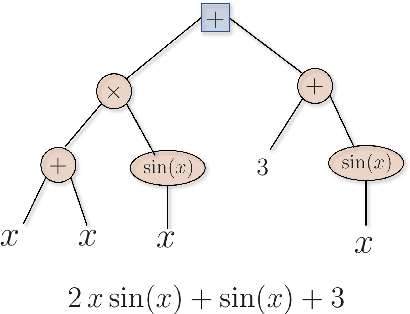
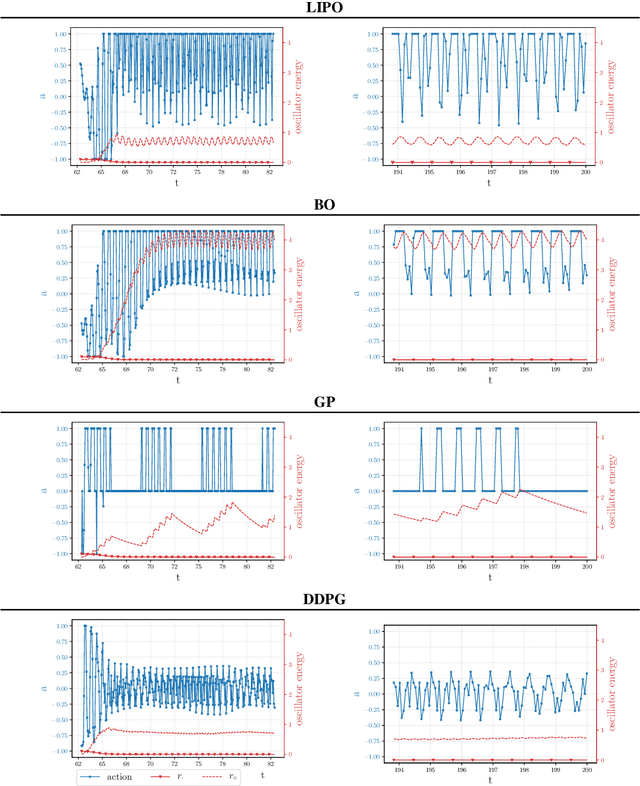
Machine learning frameworks such as Genetic Programming (GP) and Reinforcement Learning (RL) are gaining popularity in flow control. This work presents a comparative analysis of the two, bench-marking some of their most representative algorithms against global optimization techniques such as Bayesian Optimization (BO) and Lipschitz global optimization (LIPO). First, we review the general framework of the flow control problem, linking optimal control theory with model-free machine learning methods. Then, we test the control algorithms on three test cases. These are (1) the stabilization of a nonlinear dynamical system featuring frequency cross-talk, (2) the wave cancellation from a Burgers' flow and (3) the drag reduction in a cylinder wake flow. Although the control of these problems has been tackled in the recent literature with one method or the other, we present a comprehensive comparison to illustrate their differences in exploration versus exploitation and their balance between `model capacity' in the control law definition versus `required complexity'. We believe that such a comparison opens the path towards hybridization of the various methods, and we offer some perspective on their future development in the literature of flow control problems.
A review on Deep Reinforcement Learning for Fluid Mechanics
Aug 12, 2019
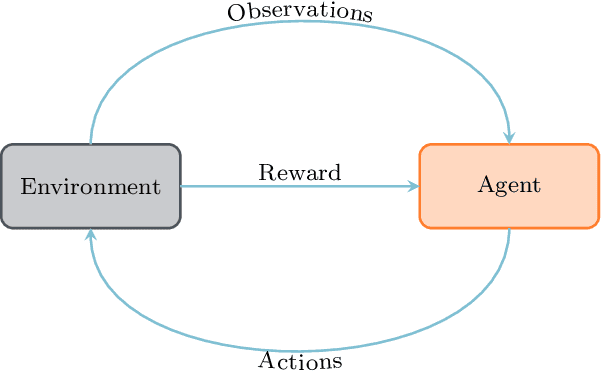


Deep reinforcement learning (DRL) has recently been adopted in a wide range of physics and engineering domains for its ability to solve decision-making problems that were previously out of reach due to a combination of non-linearity and high dimensionality. In the last few years, it has spread in the field of computational mechanics, and particularly in fluid dynamics, with recent applications in flow control and shape optimization. In this work, we conduct a detailed review of existing DRL applications to fluid mechanics problems. In addition, we present recent results that further illustrate the potential of DRL in Fluid Mechanics. The coupling methods used in each case are covered, detailing their advantages and limitations. Our review also focuses on the comparison with classical methods for optimal control and optimization. Finally, several test cases are described that illustrate recent progress made in this field. The goal of this publication is to provide an understanding of DRL capabilities along with state-of-the-art applications in fluid dynamics to researchers wishing to address new problems with these methods.