 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJean-François Goudou
Training Discriminative Models to Evaluate Generative Ones
Jun 28, 2018
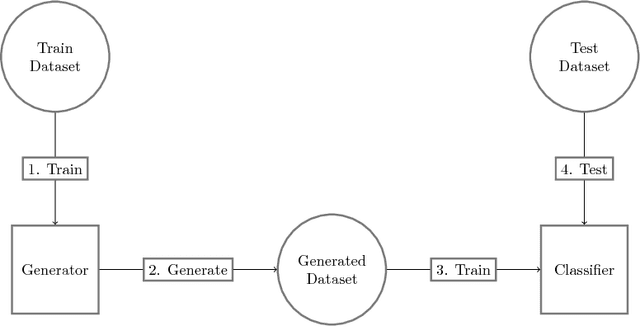
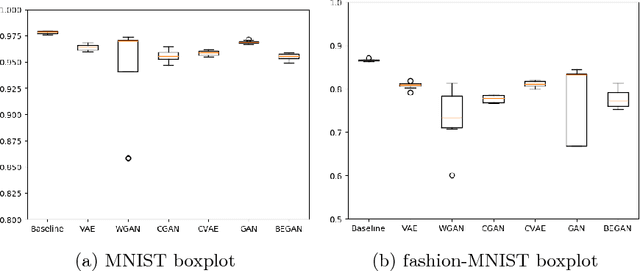
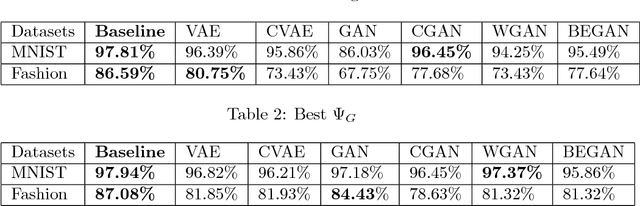
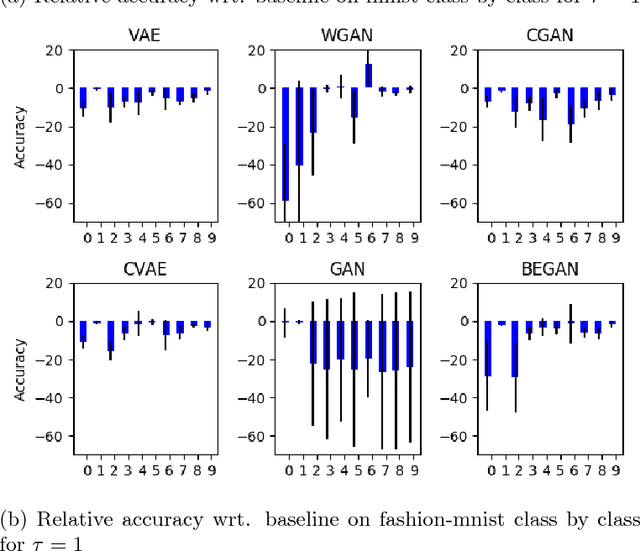
Generative models are known to be difficult to assess. Recent works, especially on generative adversarial networks (GANs), produce good visual samples of varied categories of images. However, the validation of their quality is still difficult to define and there is no existing agreement on the best evaluation process. This paper aims at making a step toward an objective evaluation process for generative models. It presents a new method to assess a trained generative model by evaluating its capacity to teach a classification task to a discriminative model. Our approach evaluates generators on a testing set by using, as a proxy, a neural network classifier trained on generated samples. Neural networks classifier are known to be difficult to train on an unbalanced or biased dataset. We use this weakness as a proxy to evaluate generated data and hence generative models. Our assumption is that to train a successful neural network classifier, the training data should contain meaningful and varied information, that fit and capture the whole distribution of the testing dataset. By comparing results with different generated datasets we can classify generative models. The motivation of this approach is also to evaluate if generative models can help discriminative neural networks to learn, i.e., measure if training on generated data is able to make a model successful at testing on real settings. Our experiments compare different generators from the VAE and GAN framework on MNIST and fashion MNIST datasets. The results of our different experiments show that none of the generative models are able to replace completely true data to train a discriminative model. It also shows that the initial GAN and WGAN are the best choices to generate comparable datasets on MNIST and fashion MNIST but suffer from instability. VAE and CVAE are a bit less well-performing but are much more stable.
State Representation Learning for Control: An Overview
Jun 05, 2018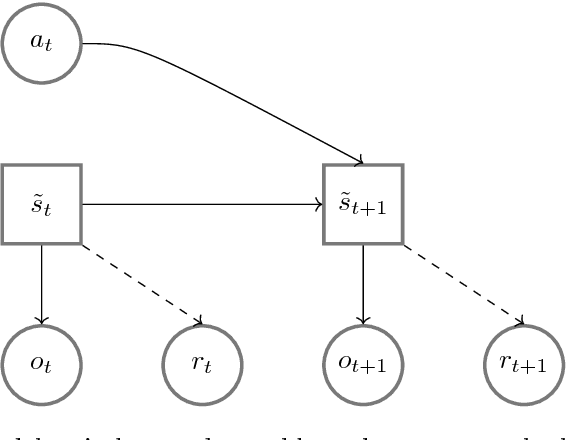
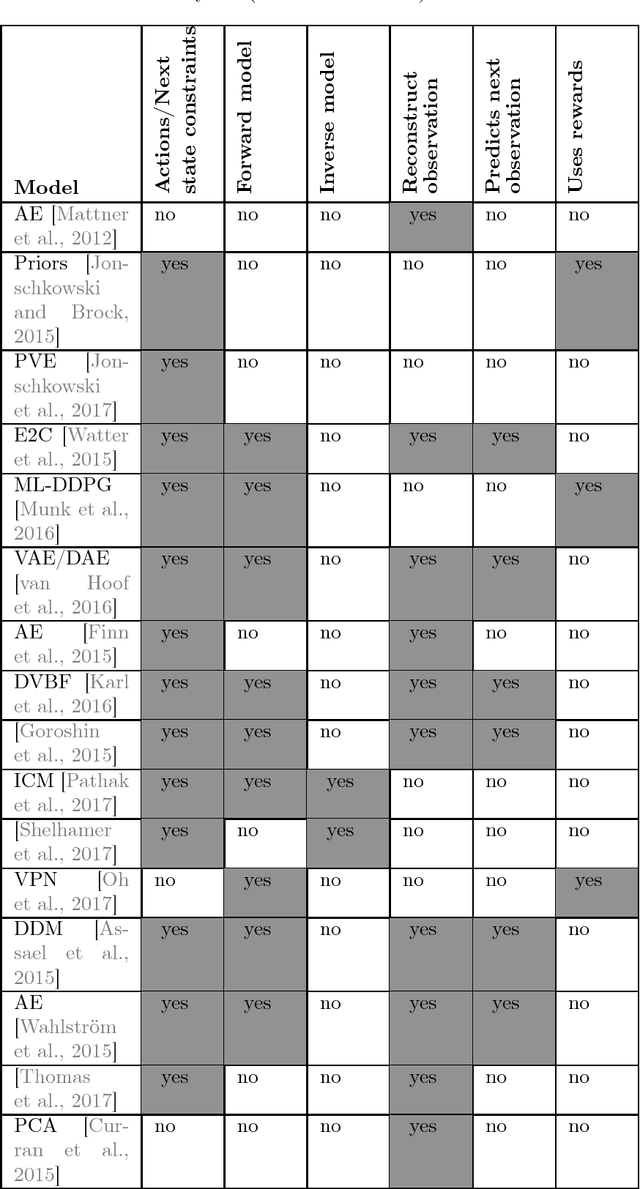
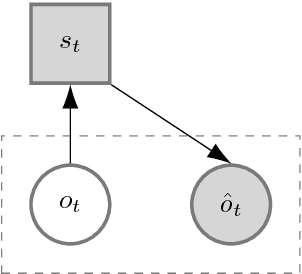
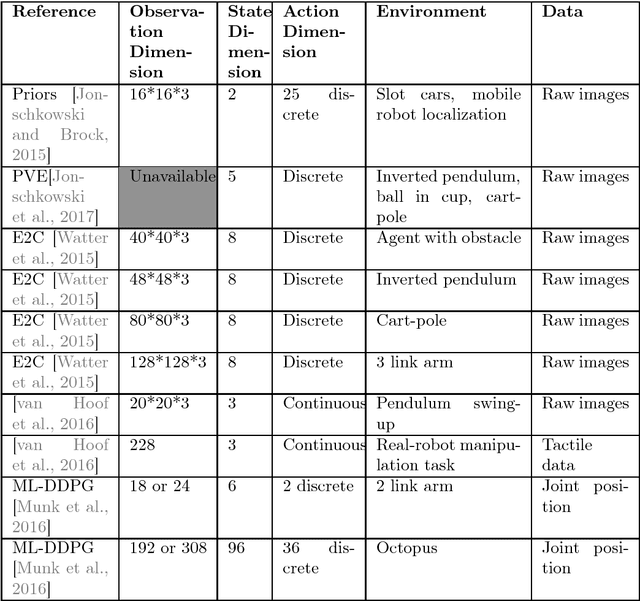
Representation learning algorithms are designed to learn abstract features that characterize data. State representation learning (SRL) focuses on a particular kind of representation learning where learned features are in low dimension, evolve through time, and are influenced by actions of an agent. The representation is learned to capture the variation in the environment generated by the agent's actions; this kind of representation is particularly suitable for robotics and control scenarios. In particular, the low dimension characteristic of the representation helps to overcome the curse of dimensionality, provides easier interpretation and utilization by humans and can help improve performance and speed in policy learning algorithms such as reinforcement learning. This survey aims at covering the state-of-the-art on state representation learning in the most recent years. It reviews different SRL methods that involve interaction with the environment, their implementations and their applications in robotics control tasks (simulated or real). In particular, it highlights how generic learning objectives are differently exploited in the reviewed algorithms. Finally, it discusses evaluation methods to assess the representation learned and summarizes current and future lines of research.