 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeffrey Kane Johnson
The Colliding Reciprocal Dance Problem: A Mitigation Strategy with Application to Automotive Active Safety Systems
Sep 19, 2019
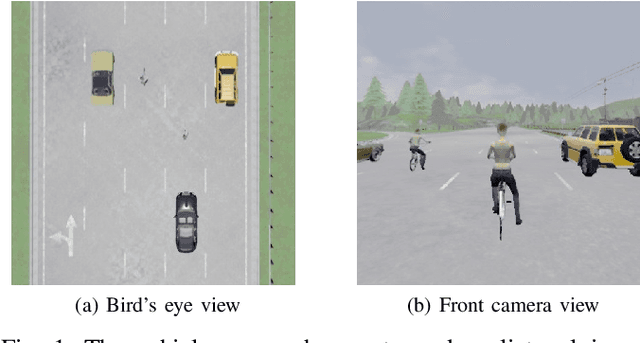
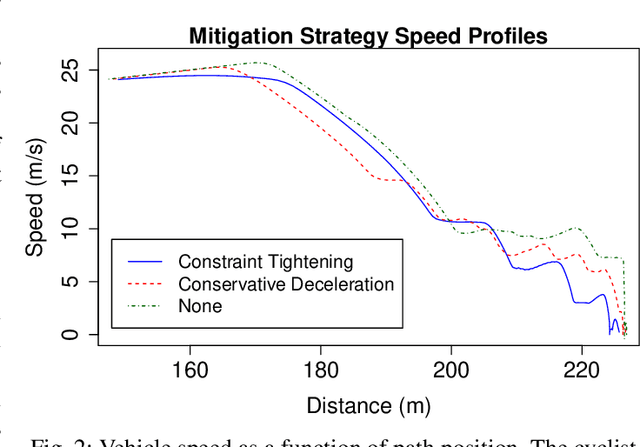
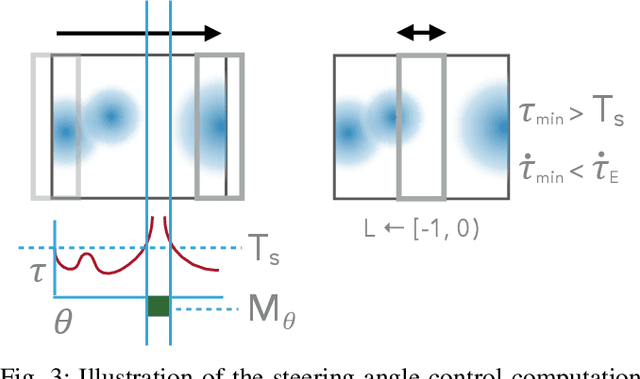
A reciprocal dance occurs when two mobile agents attempt to pass each other but incompatible interaction models result in repeated attempts to take mutually blocking actions. Often, such a situation simply results in deadlock. But in systems with significant inertial constraints, it can result in collision. This abstract presents this colliding variant of the reciprocal dance, how it arises, and a mitigation strategy that can improve safety without sacrificing flexibility. A demonstration of the concept is provided in the context of automotive active safety.
Image Space Potential Fields: Constant Size Environment Representation for Vision-based Subsumption Control Architectures
Sep 26, 2017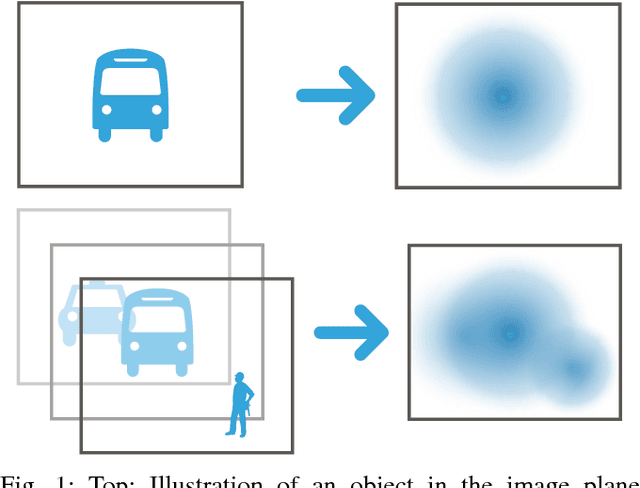
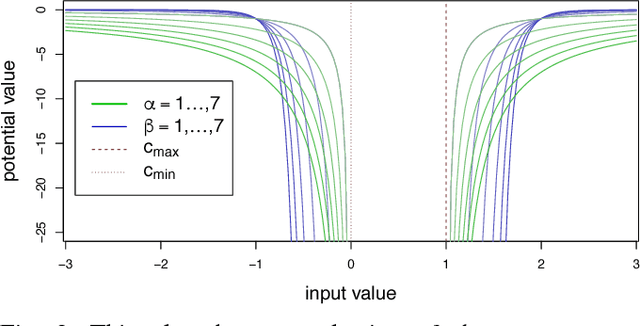
This technical report presents an environment representation for use in vision-based navigation. The representation has two useful properties: 1) it has constant size, which can enable strong run-time guarantees to be made for control algorithms using it, and 2) it is structurally similar to a camera image space, which effectively allows control to operate in the sensor space rather than employing difficult, and often inaccurate, projections into a structurally different control space (e.g. Euclidean). The presented representation is intended to form the basis of a vision-based subsumption control architecture.
Constant Space Complexity Environment Representation for Vision-based Navigation
Sep 12, 2017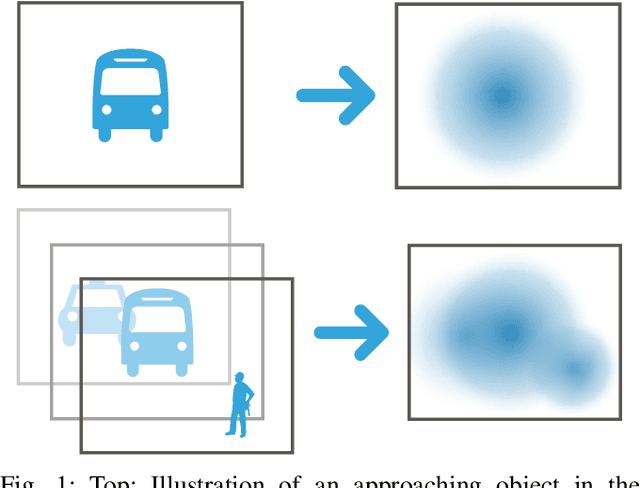
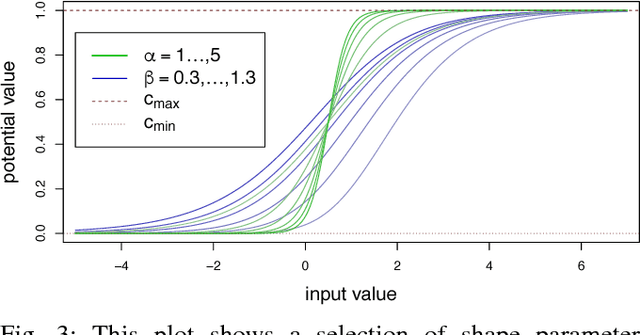
This paper presents a preliminary conceptual investigation into an environment representation that has constant space complexity with respect to the camera image space. This type of representation allows the planning algorithms of a mobile agent to bypass what are often complex and noisy transformations between camera image space and Euclidean space. The approach is to compute per-pixel potential values directly from processed camera data, which results in a discrete potential field that has constant space complexity with respect to the image plane. This can enable planning and control algorithms, whose complexity often depends on the size of the environment representation, to be defined with constant run-time. This type of approach can be particularly useful for platforms with strict resource constraints, such as embedded and real-time systems.