 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeongho Kim
StableVITON: Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
Dec 04, 2023
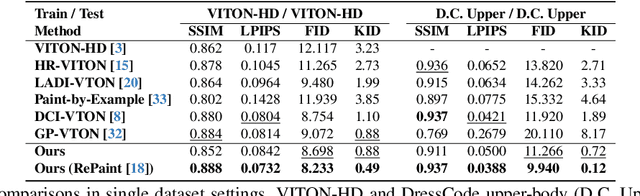

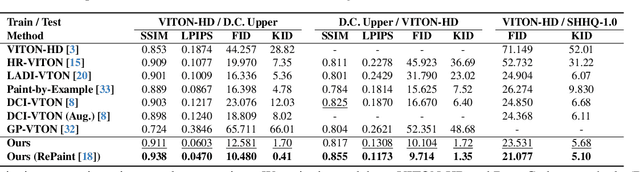
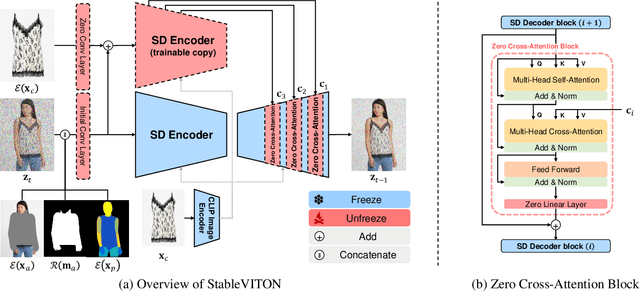
Given a clothing image and a person image, an image-based virtual try-on aims to generate a customized image that appears natural and accurately reflects the characteristics of the clothing image. In this work, we aim to expand the applicability of the pre-trained diffusion model so that it can be utilized independently for the virtual try-on task.The main challenge is to preserve the clothing details while effectively utilizing the robust generative capability of the pre-trained model. In order to tackle these issues, we propose StableVITON, learning the semantic correspondence between the clothing and the human body within the latent space of the pre-trained diffusion model in an end-to-end manner. Our proposed zero cross-attention blocks not only preserve the clothing details by learning the semantic correspondence but also generate high-fidelity images by utilizing the inherent knowledge of the pre-trained model in the warping process. Through our proposed novel attention total variation loss and applying augmentation, we achieve the sharp attention map, resulting in a more precise representation of clothing details. StableVITON outperforms the baselines in qualitative and quantitative evaluation, showing promising quality in arbitrary person images. Our code is available at https://github.com/rlawjdghek/StableVITON.
Hamilton-Jacobi Deep Q-Learning for Deterministic Continuous-Time Systems with Lipschitz Continuous Controls
Oct 27, 2020



In this paper, we propose Q-learning algorithms for continuous-time deterministic optimal control problems with Lipschitz continuous controls. Our method is based on a new class of Hamilton-Jacobi-Bellman (HJB) equations derived from applying the dynamic programming principle to continuous-time Q-functions. A novel semi-discrete version of the HJB equation is proposed to design a Q-learning algorithm that uses data collected in discrete time without discretizing or approximating the system dynamics. We identify the condition under which the Q-function estimated by this algorithm converges to the optimal Q-function. For practical implementation, we propose the Hamilton-Jacobi DQN, which extends the idea of deep Q-networks (DQN) to our continuous control setting. This approach does not require actor networks or numerical solutions to optimization problems for greedy actions since the HJB equation provides a simple characterization of optimal controls via ordinary differential equations. We empirically demonstrate the performance of our method through benchmark tasks and high-dimensional linear-quadratic problems.
Hamilton-Jacobi-Bellman Equations for Q-Learning in Continuous Time
Dec 23, 2019


In this paper, we introduce Hamilton-Jacobi-Bellman (HJB) equations for Q-functions in continuous time optimal control problems with Lipschitz continuous controls. The standard Q-function used in reinforcement learning is shown to be the unique viscosity solution of the HJB equation. A necessary and sufficient condition for optimality is provided using the viscosity solution framework. By using the HJB equation, we develop a Q-learning method for continuous-time dynamical systems. A DQN-like algorithm is also proposed for high-dimensional state and control spaces. The performance of the proposed Q-learning algorithm is demonstrated using 1-, 10- and 20-dimensional dynamical systems.