 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeonghwan Kim
Finer: Investigating and Enhancing Fine-Grained Visual Concept Recognition in Large Vision Language Models
Feb 26, 2024
Recent advances in instruction-tuned Large Vision-Language Models (LVLMs) have imbued the models with the ability to generate high-level, image-grounded explanations with ease. While such capability is largely attributed to the rich world knowledge contained within the Large Language Models (LLMs), our work reveals their shortcomings in fine-grained visual categorization (FGVC) across six different benchmark settings. Most recent state-of-the-art LVLMs like LLaVa-1.5, InstructBLIP and GPT-4V not only severely deteriorate in terms of classification performance, e.g., average drop of 65.58 in EM for Stanford Dogs for LLaVA-1.5, but also struggle to generate an accurate explanation with detailed attributes based on the concept that appears within an input image despite their capability to generate holistic image-level descriptions. In-depth analyses show that instruction-tuned LVLMs exhibit modality gap, showing discrepancy when given textual and visual inputs that correspond to the same concept, preventing the image modality from leveraging the rich parametric knowledge within the LLMs. In an effort to further the community's endeavor in this direction, we propose a multiple granularity attribute-centric evaluation benchmark, Finer, which aims to establish a ground to evaluate LVLMs' fine-grained visual comprehension ability and provide significantly improved explainability.
ParaHome: Parameterizing Everyday Home Activities Towards 3D Generative Modeling of Human-Object Interactions
Jan 18, 2024To enable machines to learn how humans interact with the physical world in our daily activities, it is crucial to provide rich data that encompasses the 3D motion of humans as well as the motion of objects in a learnable 3D representation. Ideally, this data should be collected in a natural setup, capturing the authentic dynamic 3D signals during human-object interactions. To address this challenge, we introduce the ParaHome system, designed to capture and parameterize dynamic 3D movements of humans and objects within a common home environment. Our system consists of a multi-view setup with 70 synchronized RGB cameras, as well as wearable motion capture devices equipped with an IMU-based body suit and hand motion capture gloves. By leveraging the ParaHome system, we collect a novel large-scale dataset of human-object interaction. Notably, our dataset offers key advancement over existing datasets in three main aspects: (1) capturing 3D body and dexterous hand manipulation motion alongside 3D object movement within a contextual home environment during natural activities; (2) encompassing human interaction with multiple objects in various episodic scenarios with corresponding descriptions in texts; (3) including articulated objects with multiple parts expressed with parameterized articulations. Building upon our dataset, we introduce new research tasks aimed at building a generative model for learning and synthesizing human-object interactions in a real-world room setting.
ACE: Adversarial Correspondence Embedding for Cross Morphology Motion Retargeting from Human to Nonhuman Characters
May 24, 2023
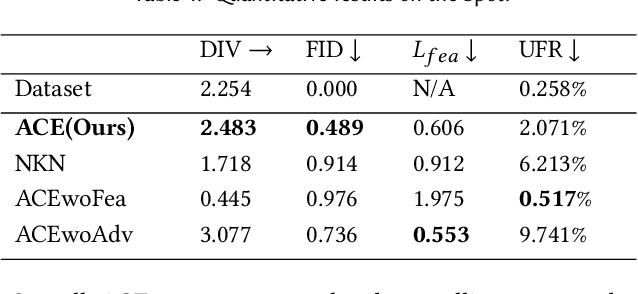
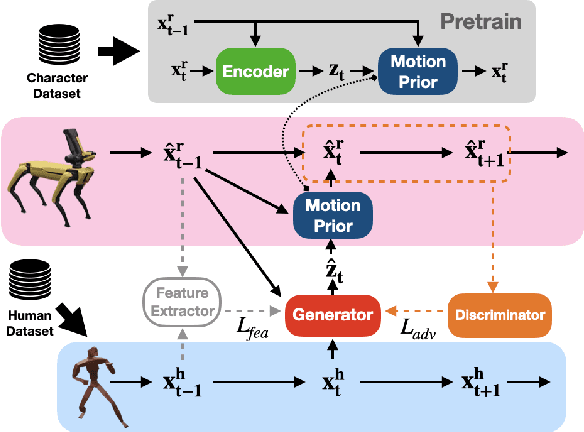

Motion retargeting is a promising approach for generating natural and compelling animations for nonhuman characters. However, it is challenging to translate human movements into semantically equivalent motions for target characters with different morphologies due to the ambiguous nature of the problem. This work presents a novel learning-based motion retargeting framework, Adversarial Correspondence Embedding (ACE), to retarget human motions onto target characters with different body dimensions and structures. Our framework is designed to produce natural and feasible robot motions by leveraging generative-adversarial networks (GANs) while preserving high-level motion semantics by introducing an additional feature loss. In addition, we pretrain a robot motion prior that can be controlled in a latent embedding space and seek to establish a compact correspondence. We demonstrate that the proposed framework can produce retargeted motions for three different characters -- a quadrupedal robot with a manipulator, a crab character, and a wheeled manipulator. We further validate the design choices of our framework by conducting baseline comparisons and a user study. We also showcase sim-to-real transfer of the retargeted motions by transferring them to a real Spot robot.
Discern and Answer: Mitigating the Impact of Misinformation in Retrieval-Augmented Models with Discriminators
May 02, 2023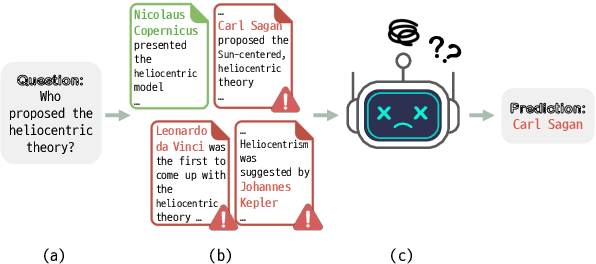
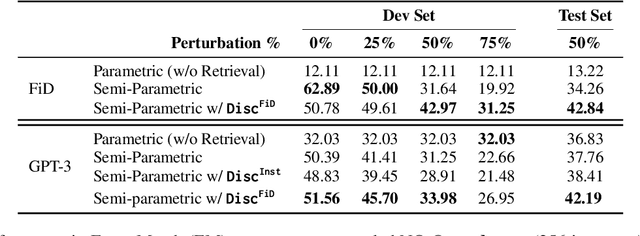
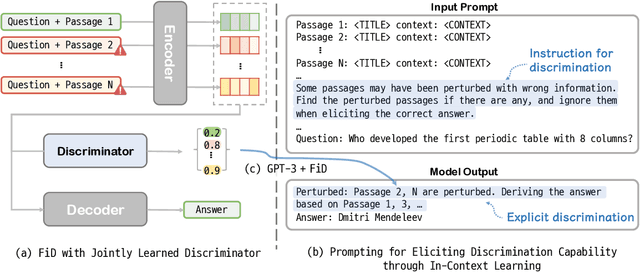

Most existing retrieval-augmented language models (LMs) for question answering assume all retrieved information is factually correct. In this work, we study a more realistic scenario in which retrieved documents may contain misinformation, causing conflicts among them. We observe that the existing models are highly brittle to such information in both fine-tuning and in-context few-shot learning settings. We propose approaches to make retrieval-augmented LMs robust to misinformation by explicitly fine-tuning a discriminator or prompting to elicit discrimination capability in GPT-3. Our empirical results on open-domain question answering show that these approaches significantly improve LMs' robustness to knowledge conflicts. We also provide our findings on interleaving the fine-tuned model's decision with the in-context learning process, paving a new path to leverage the best of both worlds.
Sampling is Matter: Point-guided 3D Human Mesh Reconstruction
Apr 19, 2023



This paper presents a simple yet powerful method for 3D human mesh reconstruction from a single RGB image. Most recently, the non-local interactions of the whole mesh vertices have been effectively estimated in the transformer while the relationship between body parts also has begun to be handled via the graph model. Even though those approaches have shown the remarkable progress in 3D human mesh reconstruction, it is still difficult to directly infer the relationship between features, which are encoded from the 2D input image, and 3D coordinates of each vertex. To resolve this problem, we propose to design a simple feature sampling scheme. The key idea is to sample features in the embedded space by following the guide of points, which are estimated as projection results of 3D mesh vertices (i.e., ground truth). This helps the model to concentrate more on vertex-relevant features in the 2D space, thus leading to the reconstruction of the natural human pose. Furthermore, we apply progressive attention masking to precisely estimate local interactions between vertices even under severe occlusions. Experimental results on benchmark datasets show that the proposed method efficiently improves the performance of 3D human mesh reconstruction. The code and model are publicly available at: https://github.com/DCVL-3D/PointHMR_release.
ARMP: Autoregressive Motion Planning for Quadruped Locomotion and Navigation in Complex Indoor Environments
Mar 28, 2023



Generating natural and physically feasible motions for legged robots has been a challenging problem due to its complex dynamics. In this work, we introduce a novel learning-based framework of autoregressive motion planner (ARMP) for quadruped locomotion and navigation. Our method can generate motion plans with an arbitrary length in an autoregressive fashion, unlike most offline trajectory optimization algorithms for a fixed trajectory length. To this end, we first construct the motion library by solving a dense set of trajectory optimization problems for diverse scenarios and parameter settings. Then we learn the motion manifold from the dataset in a supervised learning fashion. We show that the proposed ARMP can generate physically plausible motions for various tasks and situations. We also showcase that our method can be successfully integrated with the recent robot navigation frameworks as a low-level controller and unleash the full capability of legged robots for complex indoor navigation.
Maximizing Efficiency of Language Model Pre-training for Learning Representation
Oct 13, 2021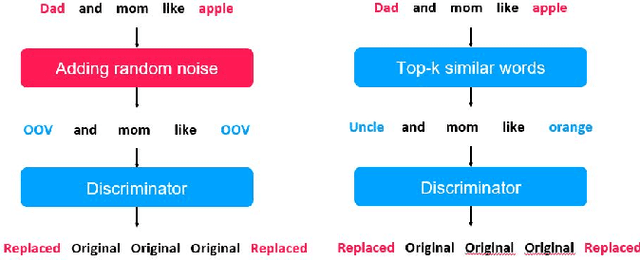
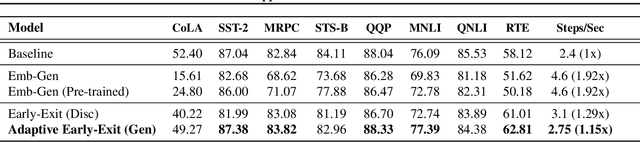
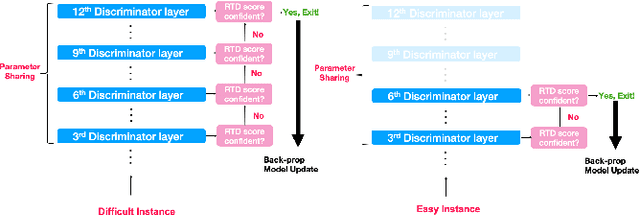

Pre-trained language models in the past years have shown exponential growth in model parameters and compute time. ELECTRA is a novel approach for improving the compute efficiency of pre-trained language models (e.g. BERT) based on masked language modeling (MLM) by addressing the sample inefficiency problem with the replaced token detection (RTD) task. Our work proposes adaptive early exit strategy to maximize the efficiency of the pre-training process by relieving the model's subsequent layers of the need to process latent features by leveraging earlier layer representations. Moreover, we evaluate an initial approach to the problem that has not succeeded in maintaining the accuracy of the model while showing a promising compute efficiency by thoroughly investigating the necessity of the generator module of ELECTRA.
Learning to Generate 3D Shapes with Generative Cellular Automata
Mar 06, 2021



We present a probabilistic 3D generative model, named Generative Cellular Automata, which is able to produce diverse and high quality shapes. We formulate the shape generation process as sampling from the transition kernel of a Markov chain, where the sampling chain eventually evolves to the full shape of the learned distribution. The transition kernel employs the local update rules of cellular automata, effectively reducing the search space in a high-resolution 3D grid space by exploiting the connectivity and sparsity of 3D shapes. Our progressive generation only focuses on the sparse set of occupied voxels and their neighborhood, thus enabling the utilization of an expressive sparse convolutional network. We propose an effective training scheme to obtain the local homogeneous rule of generative cellular automata with sequences that are slightly different from the sampling chain but converge to the full shapes in the training data. Extensive experiments on probabilistic shape completion and shape generation demonstrate that our method achieves competitive performance against recent methods.
A Sequence-Oblivious Generation Method for Context-Aware Hashtag Recommendation
Dec 05, 2020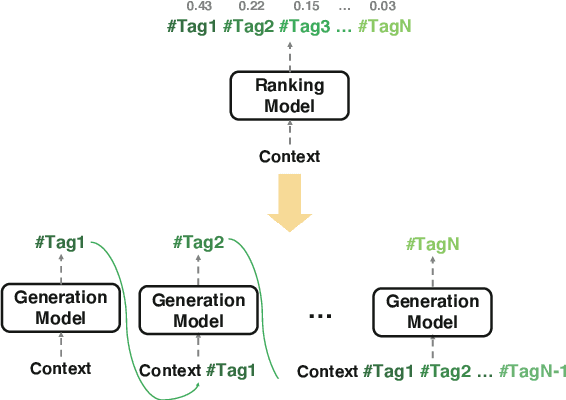
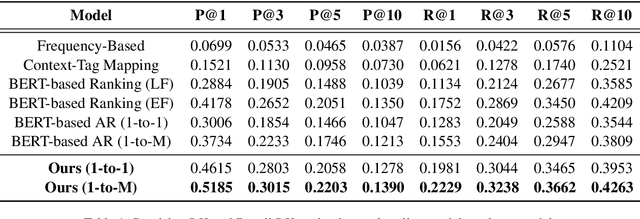
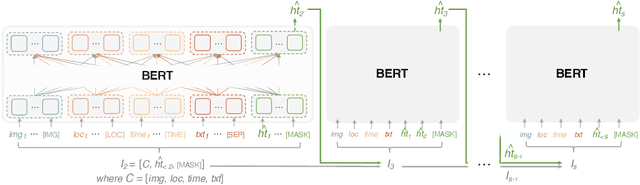
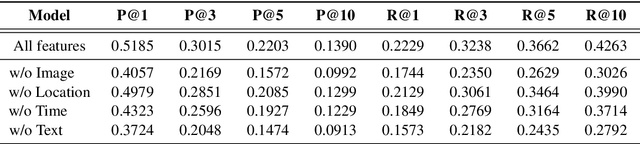
Like search, a recommendation task accepts an input query or cue and provides desirable items, often based on a ranking function. Such a ranking approach rarely considers explicit dependency among the recommended items. In this work, we propose a generative approach to tag recommendation, where semantic tags are selected one at a time conditioned on the previously generated tags to model inter-dependency among the generated tags. We apply this tag recommendation approach to an Instagram data set where an array of context feature types (image, location, time, and text) are available for posts. To exploit the inter-dependency among the distinct types of features, we adopt a simple yet effective architecture using self-attention, making deep interactions possible. Empirical results show that our method is significantly superior to not only the usual ranking schemes but also autoregressive models for tag recommendation. They indicate that it is critical to fuse mutually supporting features at an early stage to induce extensive and comprehensive view on inter-context interaction in generating tags in a recurrent feedback loop.