 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJia-Fong Yeh
Tracking-Assisted Object Detection with Event Cameras
Mar 27, 2024
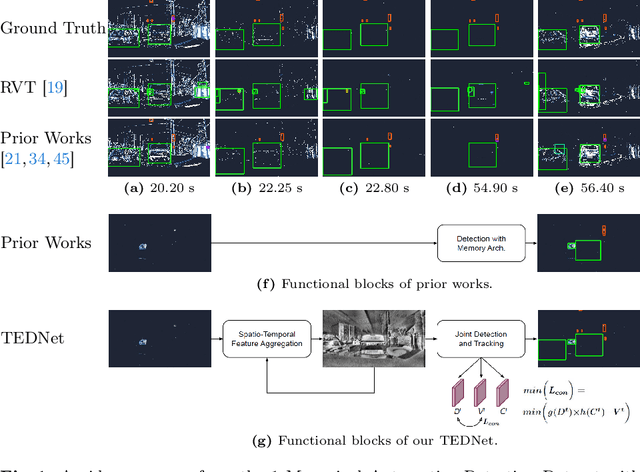



Event-based object detection has recently garnered attention in the computer vision community due to the exceptional properties of event cameras, such as high dynamic range and no motion blur. However, feature asynchronism and sparsity cause invisible objects due to no relative motion to the camera, posing a significant challenge in the task. Prior works have studied various memory mechanisms to preserve as many features as possible at the current time, guided by temporal clues. While these implicit-learned memories retain some short-term information, they still struggle to preserve long-term features effectively. In this paper, we consider those invisible objects as pseudo-occluded objects and aim to reveal their features. Firstly, we introduce visibility attribute of objects and contribute an auto-labeling algorithm to append additional visibility labels on an existing event camera dataset. Secondly, we exploit tracking strategies for pseudo-occluded objects to maintain their permanence and retain their bounding boxes, even when features have not been available for a very long time. These strategies can be treated as an explicit-learned memory guided by the tracking objective to record the displacements of objects across frames. Lastly, we propose a spatio-temporal feature aggregation module to enrich the latent features and a consistency loss to increase the robustness of the overall pipeline. We conduct comprehensive experiments to verify our method's effectiveness where still objects are retained but real occluded objects are discarded. The results demonstrate that (1) the additional visibility labels can assist in supervised training, and (2) our method outperforms state-of-the-art approaches with a significant improvement of 7.9% absolute mAP.
AED: Adaptable Error Detection for Few-shot Imitation Policy
Feb 06, 2024We study how to report few-shot imitation (FSI) policies' behavior errors in novel environments, a novel task named adaptable error detection (AED). The potential to cause serious damage to surrounding areas limits the application of FSI policies in real-world scenarios. Thus, a robust system is necessary to notify operators when FSI policies are inconsistent with the intent of demonstrations. We develop a cross-domain benchmark for the challenging AED task, consisting of 329 base and 158 novel environments. This task introduces three challenges, including (1) detecting behavior errors in novel environments, (2) behavior errors occurring without revealing notable changes, and (3) lacking complete temporal information of the rollout due to the necessity of online detection. To address these challenges, we propose Pattern Observer (PrObe) to parse discernible patterns in the policy feature representations of normal or error states, whose effectiveness is verified in the proposed benchmark. Through our comprehensive evaluation, PrObe consistently surpasses strong baselines and demonstrates a robust capability to identify errors arising from a wide range of FSI policies. Moreover, we conduct comprehensive ablations and experiments (error correction, demonstration quality, etc.) to validate the practicality of our proposed task and methodology.
MuRAL: Multi-Scale Region-based Active Learning for Object Detection
Mar 29, 2023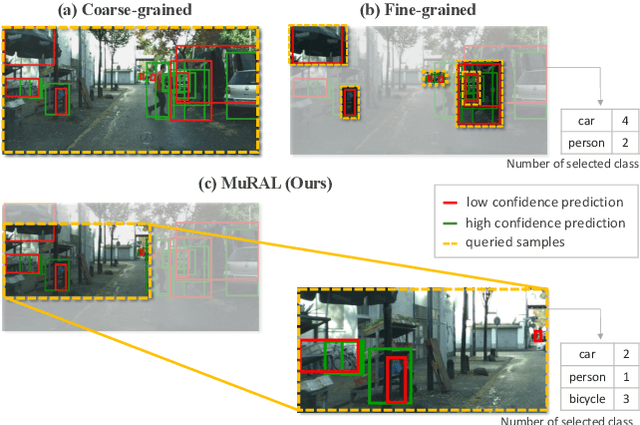
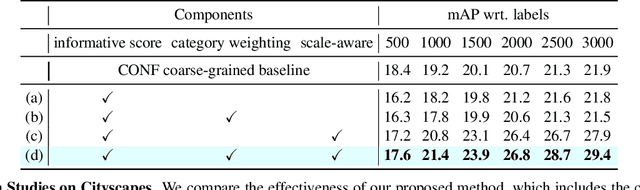
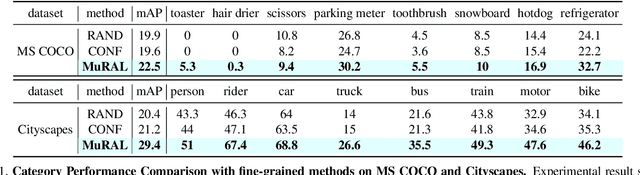

Obtaining large-scale labeled object detection dataset can be costly and time-consuming, as it involves annotating images with bounding boxes and class labels. Thus, some specialized active learning methods have been proposed to reduce the cost by selecting either coarse-grained samples or fine-grained instances from unlabeled data for labeling. However, the former approaches suffer from redundant labeling, while the latter methods generally lead to training instability and sampling bias. To address these challenges, we propose a novel approach called Multi-scale Region-based Active Learning (MuRAL) for object detection. MuRAL identifies informative regions of various scales to reduce annotation costs for well-learned objects and improve training performance. The informative region score is designed to consider both the predicted confidence of instances and the distribution of each object category, enabling our method to focus more on difficult-to-detect classes. Moreover, MuRAL employs a scale-aware selection strategy that ensures diverse regions are selected from different scales for labeling and downstream finetuning, which enhances training stability. Our proposed method surpasses all existing coarse-grained and fine-grained baselines on Cityscapes and MS COCO datasets, and demonstrates significant improvement in difficult category performance.
BIRD-PCC: Bi-directional Range Image-based Deep LiDAR Point Cloud Compression
Mar 09, 2023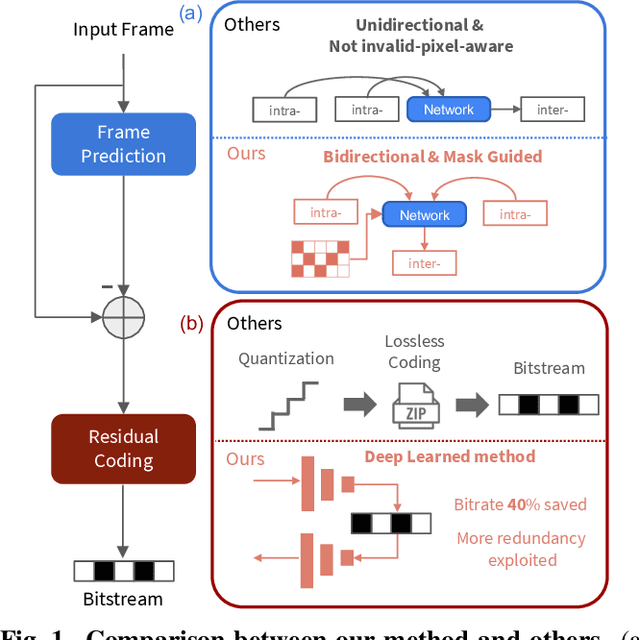
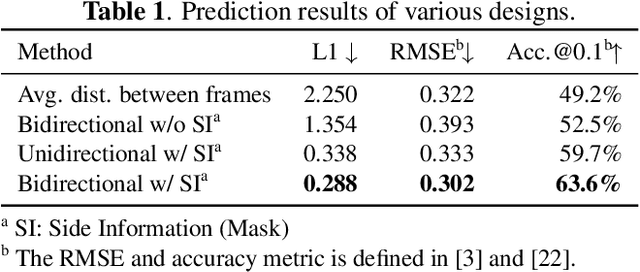

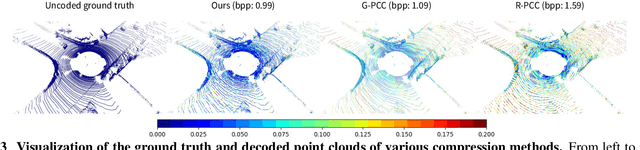
The large amount of data collected by LiDAR sensors brings the issue of LiDAR point cloud compression (PCC). Previous works on LiDAR PCC have used range image representations and followed the predictive coding paradigm to create a basic prototype of a coding framework. However, their prediction methods give an inaccurate result due to the negligence of invalid pixels in range images and the omission of future frames in the time step. Moreover, their handcrafted design of residual coding methods could not fully exploit spatial redundancy. To remedy this, we propose a coding framework BIRD-PCC. Our prediction module is aware of the coordinates of invalid pixels in range images and takes a bidirectional scheme. Also, we introduce a deep-learned residual coding module that can further exploit spatial redundancy within a residual frame. Experiments conducted on SemanticKITTI and KITTI-360 datasets show that BIRD-PCC outperforms other methods in most bitrate conditions and generalizes well to unseen environments.
Free-form 3D Scene Inpainting with Dual-stream GAN
Dec 16, 2022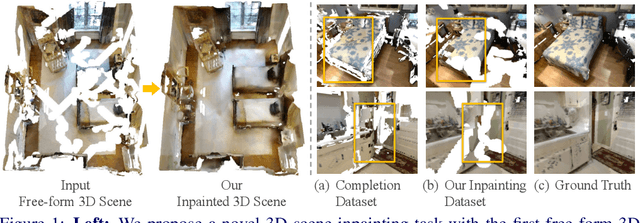
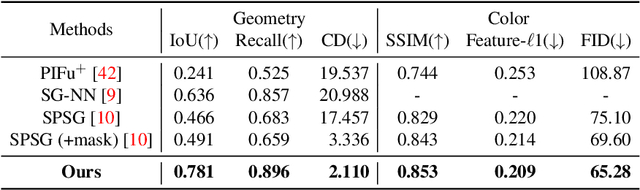
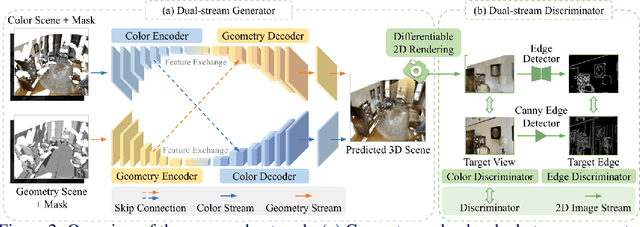
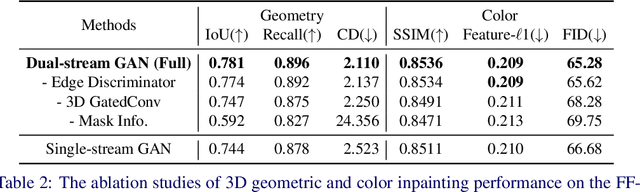
Nowadays, the need for user editing in a 3D scene has rapidly increased due to the development of AR and VR technology. However, the existing 3D scene completion task (and datasets) cannot suit the need because the missing regions in scenes are generated by the sensor limitation or object occlusion. Thus, we present a novel task named free-form 3D scene inpainting. Unlike scenes in previous 3D completion datasets preserving most of the main structures and hints of detailed shapes around missing regions, the proposed inpainting dataset, FF-Matterport, contains large and diverse missing regions formed by our free-form 3D mask generation algorithm that can mimic human drawing trajectories in 3D space. Moreover, prior 3D completion methods cannot perform well on this challenging yet practical task, simply interpolating nearby geometry and color context. Thus, a tailored dual-stream GAN method is proposed. First, our dual-stream generator, fusing both geometry and color information, produces distinct semantic boundaries and solves the interpolation issue. To further enhance the details, our lightweight dual-stream discriminator regularizes the geometry and color edges of the predicted scenes to be realistic and sharp. We conducted experiments with the proposed FF-Matterport dataset. Qualitative and quantitative results validate the superiority of our approach over existing scene completion methods and the efficacy of all proposed components.
Learning Fine-Grained Visual Understanding for Video Question Answering via Decoupling Spatial-Temporal Modeling
Oct 08, 2022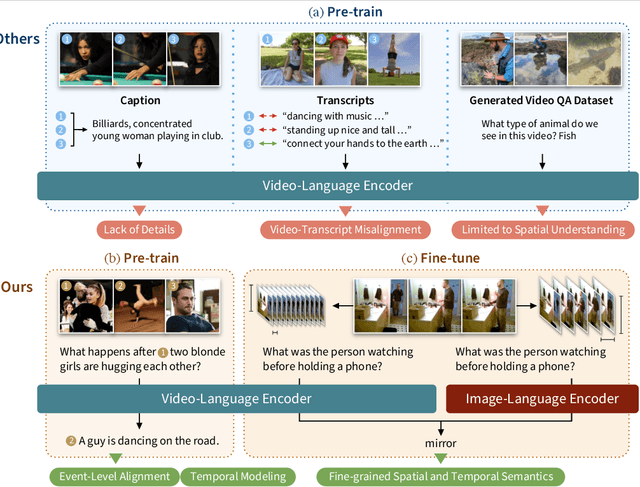
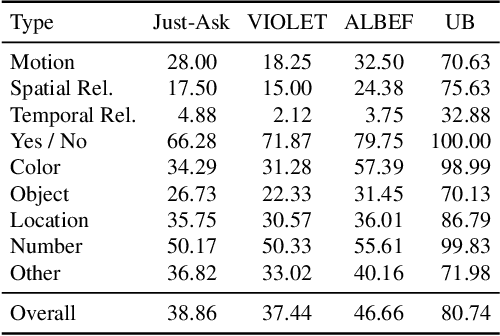
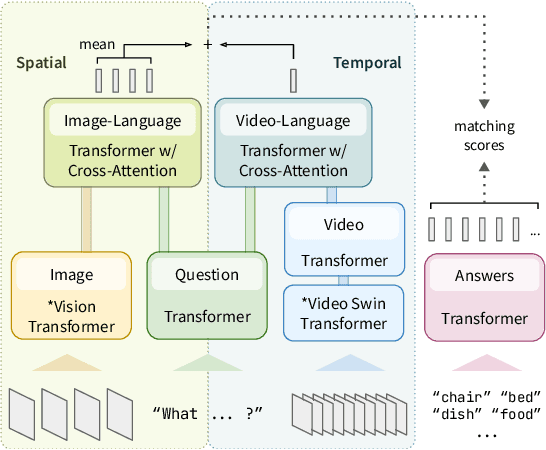
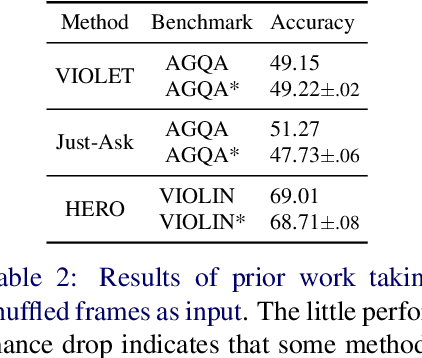
While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling of video-language models is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline, Decoupled Spatial-Temporal Encoders, integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independently of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive experiments demonstrate that our model outperforms previous work pre-trained on orders of magnitude larger datasets.
Orbeez-SLAM: A Real-time Monocular Visual SLAM with ORB Features and NeRF-realized Mapping
Sep 27, 2022



A spatial AI that can perform complex tasks through visual signals and cooperate with humans is highly anticipated. To achieve this, we need a visual SLAM that easily adapts to new scenes without pre-training and generates dense maps for downstream tasks in real-time. None of the previous learning-based and non-learning-based visual SLAMs satisfy all needs due to the intrinsic limitations of their components. In this work, we develop a visual SLAM named Orbeez-SLAM, which successfully collaborates with implicit neural representation (NeRF) and visual odometry to achieve our goals. Moreover, Orbeez-SLAM can work with the monocular camera since it only needs RGB inputs, making it widely applicable to the real world. We validate its effectiveness on various challenging benchmarks. Results show that our SLAM is up to 800x faster than the strong baseline with superior rendering outcomes.
Stage Conscious Attention Network (SCAN) : A Demonstration-Conditioned Policy for Few-Shot Imitation
Dec 04, 2021



In few-shot imitation learning (FSIL), using behavioral cloning (BC) to solve unseen tasks with few expert demonstrations becomes a popular research direction. The following capabilities are essential in robotics applications: (1) Behaving in compound tasks that contain multiple stages. (2) Retrieving knowledge from few length-variant and misalignment demonstrations. (3) Learning from a different expert. No previous work can achieve these abilities at the same time. In this work, we conduct FSIL problem under the union of above settings and introduce a novel stage conscious attention network (SCAN) to retrieve knowledge from few demonstrations simultaneously. SCAN uses an attention module to identify each stage in length-variant demonstrations. Moreover, it is designed under demonstration-conditioned policy that learns the relationship between experts and agents. Experiment results show that SCAN can learn from different experts without fine-tuning and outperform baselines in complicated compound tasks with explainable visualization.
Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection
Feb 24, 2021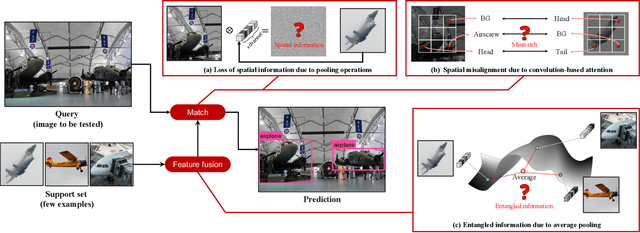


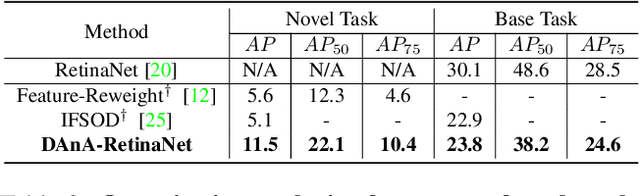
While recent progress has significantly boosted few-shot classification (FSC) performance, few-shot object detection (FSOD) remains challenging for modern learning systems. Existing FSOD systems follow FSC approaches, neglect the problem of spatial misalignment and the risk of information entanglement, and result in low performance. Observing this, we propose a novel Dual-Awareness-Attention (DAnA), which captures the pairwise spatial relationship cross the support and query images. The generated query-position-aware support features are robust to spatial misalignment and used to guide the detection network precisely. Our DAnA component is adaptable to various existing object detection networks and boosts FSOD performance by paying attention to specific semantics conditioned on the query. Experimental results demonstrate that DAnA significantly boosts (48% and 125% relatively) object detection performance on the COCO benchmark. By equipping DAnA, conventional object detection models, Faster-RCNN and RetinaNet, which are not designed explicitly for few-shot learning, reach state-of-the-art performance.
Large Margin Mechanism and Pseudo Query Set on Cross-Domain Few-Shot Learning
May 19, 2020


In recent years, few-shot learning problems have received a lot of attention. While methods in most previous works were trained and tested on datasets in one single domain, cross-domain few-shot learning is a brand-new branch of few-shot learning problems, where models handle datasets in different domains between training and testing phases. In this paper, to solve the problem that the model is pre-trained (meta-trained) on a single dataset while fine-tuned on datasets in four different domains, including common objects, satellite images, and medical images, we propose a novel large margin fine-tuning method (LMM-PQS), which generates pseudo query images from support images and fine-tunes the feature extraction modules with a large margin mechanism inspired by methods in face recognition. According to the experiment results, LMM-PQS surpasses the baseline models by a significant margin and demonstrates that our approach is robust and can easily adapt pre-trained models to new domains with few data.