 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJia-Nan Wu
Exploiting Local Structures with the Kronecker Layer in Convolutional Networks
Feb 04, 2016

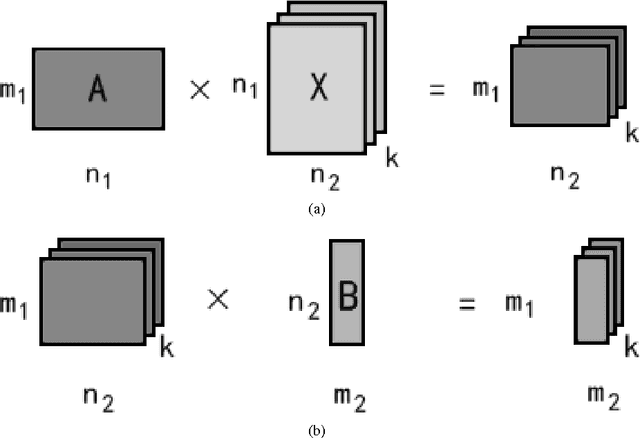

In this paper, we propose and study a technique to reduce the number of parameters and computation time in convolutional neural networks. We use Kronecker product to exploit the local structures within convolution and fully-connected layers, by replacing the large weight matrices by combinations of multiple Kronecker products of smaller matrices. Just as the Kronecker product is a generalization of the outer product from vectors to matrices, our method is a generalization of the low rank approximation method for convolution neural networks. We also introduce combinations of different shapes of Kronecker product to increase modeling capacity. Experiments on SVHN, scene text recognition and ImageNet dataset demonstrate that we can achieve $3.3 \times$ speedup or $3.6 \times$ parameter reduction with less than 1\% drop in accuracy, showing the effectiveness and efficiency of our method. Moreover, the computation efficiency of Kronecker layer makes using larger feature map possible, which in turn enables us to outperform the previous state-of-the-art on both SVHN(digit recognition) and CASIA-HWDB (handwritten Chinese character recognition) datasets.
Compression of Fully-Connected Layer in Neural Network by Kronecker Product
Jul 22, 2015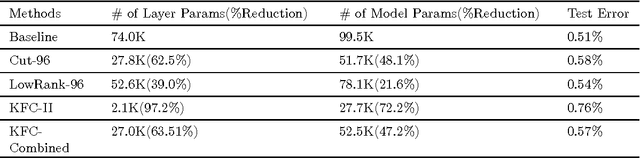
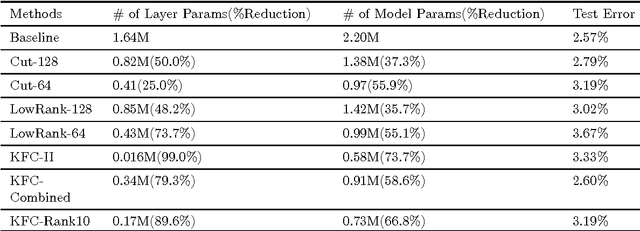
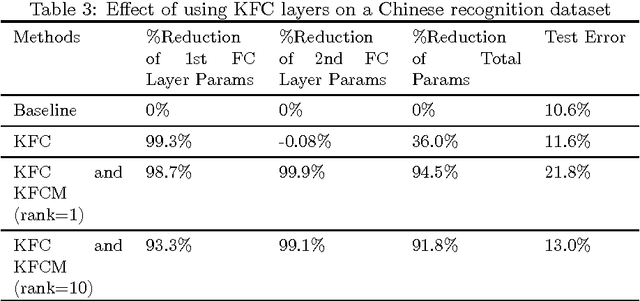
In this paper we propose and study a technique to reduce the number of parameters and computation time in fully-connected layers of neural networks using Kronecker product, at a mild cost of the prediction quality. The technique proceeds by replacing Fully-Connected layers with so-called Kronecker Fully-Connected layers, where the weight matrices of the FC layers are approximated by linear combinations of multiple Kronecker products of smaller matrices. In particular, given a model trained on SVHN dataset, we are able to construct a new KFC model with 73\% reduction in total number of parameters, while the error only rises mildly. In contrast, using low-rank method can only achieve 35\% reduction in total number of parameters given similar quality degradation allowance. If we only compare the KFC layer with its counterpart fully-connected layer, the reduction in the number of parameters exceeds 99\%. The amount of computation is also reduced as we replace matrix product of the large matrices in FC layers with matrix products of a few smaller matrices in KFC layers. Further experiments on MNIST, SVHN and some Chinese Character recognition models also demonstrate effectiveness of our technique.