 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiachun Li
On the Optimal Regret of Locally Private Linear Contextual Bandit
Apr 15, 2024
Contextual bandit with linear reward functions is among one of the most extensively studied models in bandit and online learning research. Recently, there has been increasing interest in designing \emph{locally private} linear contextual bandit algorithms, where sensitive information contained in contexts and rewards is protected against leakage to the general public. While the classical linear contextual bandit algorithm admits cumulative regret upper bounds of $\tilde O(\sqrt{T})$ via multiple alternative methods, it has remained open whether such regret bounds are attainable in the presence of local privacy constraints, with the state-of-the-art result being $\tilde O(T^{3/4})$. In this paper, we show that it is indeed possible to achieve an $\tilde O(\sqrt{T})$ regret upper bound for locally private linear contextual bandit. Our solution relies on several new algorithmic and analytical ideas, such as the analysis of mean absolute deviation errors and layered principal component regression in order to achieve small mean absolute deviation errors.
Focus on Your Question! Interpreting and Mitigating Toxic CoT Problems in Commonsense Reasoning
Feb 28, 2024Large language models exhibit high-level commonsense reasoning abilities, especially with enhancement methods like Chain-of-Thought (CoT). However, we find these CoT-like methods lead to a considerable number of originally correct answers turning wrong, which we define as the Toxic CoT problem. To interpret and mitigate this problem, we first utilize attribution tracing and causal tracing methods to probe the internal working mechanism of the LLM during CoT reasoning. Through comparisons, we prove that the model exhibits information loss from the question over the shallow attention layers when generating rationales or answers. Based on the probing findings, we design a novel method called RIDERS (Residual decodIng and sERial-position Swap), which compensates for the information deficit in the model from both decoding and serial-position perspectives. Through extensive experiments on multiple commonsense reasoning benchmarks, we validate that this method not only significantly eliminates Toxic CoT problems (decreased by 23.6%), but also effectively improves the model's overall commonsense reasoning performance (increased by 5.5%).
Privacy Preserving Adaptive Experiment Design
Feb 05, 2024Adaptive experiment is widely adopted to estimate conditional average treatment effect (CATE) in clinical trials and many other scenarios. While the primary goal in experiment is to maximize estimation accuracy, due to the imperative of social welfare, it's also crucial to provide treatment with superior outcomes to patients, which is measured by regret in contextual bandit framework. These two objectives often lead to contrast optimal allocation mechanism. Furthermore, privacy concerns arise in clinical scenarios containing sensitive data like patients health records. Therefore, it's essential for the treatment allocation mechanism to incorporate robust privacy protection measures. In this paper, we investigate the tradeoff between loss of social welfare and statistical power in contextual bandit experiment. We propose a matched upper and lower bound for the multi-objective optimization problem, and then adopt the concept of Pareto optimality to mathematically characterize the optimality condition. Furthermore, we propose differentially private algorithms which still matches the lower bound, showing that privacy is "almost free". Additionally, we derive the asymptotic normality of the estimator, which is essential in statistical inference and hypothesis testing.
Fight Fire with Fire: Combating Adversarial Patch Attacks using Pattern-randomized Defensive Patches
Nov 10, 2023Object detection has found extensive applications in various tasks, but it is also susceptible to adversarial patch attacks. Existing defense methods often necessitate modifications to the target model or result in unacceptable time overhead. In this paper, we adopt a counterattack approach, following the principle of "fight fire with fire," and propose a novel and general methodology for defending adversarial attacks. We utilize an active defense strategy by injecting two types of defensive patches, canary and woodpecker, into the input to proactively probe or weaken potential adversarial patches without altering the target model. Moreover, inspired by randomization techniques employed in software security, we employ randomized canary and woodpecker injection patterns to defend against defense-aware attacks. The effectiveness and practicality of the proposed method are demonstrated through comprehensive experiments. The results illustrate that canary and woodpecker achieve high performance, even when confronted with unknown attack methods, while incurring limited time overhead. Furthermore, our method also exhibits sufficient robustness against defense-aware attacks, as evidenced by adaptive attack experiments.
We Can Always Catch You: Detecting Adversarial Patched Objects WITH or WITHOUT Signature
Jun 10, 2021
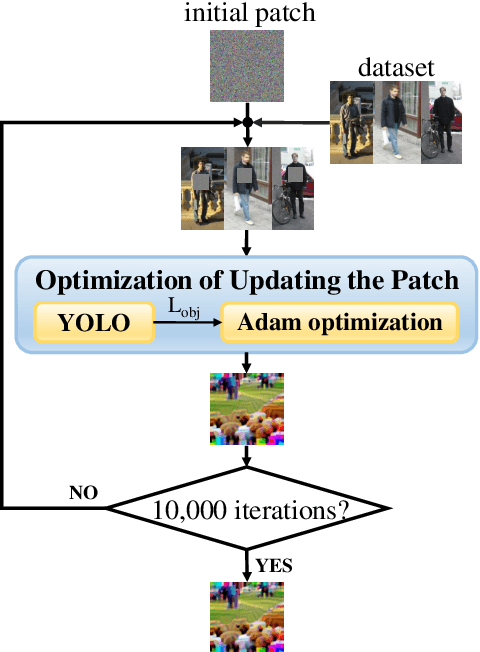
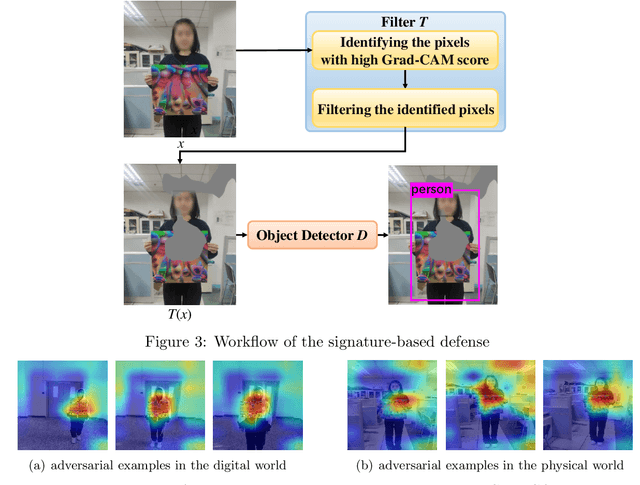

Recently, the object detection based on deep learning has proven to be vulnerable to adversarial patch attacks. The attackers holding a specially crafted patch can hide themselves from the state-of-the-art person detectors, e.g., YOLO, even in the physical world. This kind of attack can bring serious security threats, such as escaping from surveillance cameras. In this paper, we deeply explore the detection problems about the adversarial patch attacks to the object detection. First, we identify a leverageable signature of existing adversarial patches from the point of the visualization explanation. A fast signature-based defense method is proposed and demonstrated to be effective. Second, we design an improved patch generation algorithm to reveal the risk that the signature-based way may be bypassed by the techniques emerging in the future. The newly generated adversarial patches can successfully evade the proposed signature-based defense. Finally, we present a novel signature-independent detection method based on the internal content semantics consistency rather than any attack-specific prior knowledge. The fundamental intuition is that the adversarial object can appear locally but disappear globally in an input image. The experiments demonstrate that the signature-independent method can effectively detect the existing and improved attacks. It has also proven to be a general method by detecting unforeseen and even other types of attacks without any attack-specific prior knowledge. The two proposed detection methods can be adopted in different scenarios, and we believe that combining them can offer a comprehensive protection.