 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiahui Wang
LGSDF: Continual Global Learning of Signed Distance Fields Aided by Local Updating
Apr 08, 2024
Implicit reconstruction of ESDF (Euclidean Signed Distance Field) involves training a neural network to regress the signed distance from any point to the nearest obstacle, which has the advantages of lightweight storage and continuous querying. However, existing algorithms usually rely on conflicting raw observations as training data, resulting in poor map performance. In this paper, we propose LGSDF, an ESDF continual Global learning algorithm aided by Local updating. At the front end, axis-aligned grids are dynamically updated by pre-processed sensor observations, where incremental fusion alleviates estimation error caused by limited viewing directions. At the back end, a randomly initialized implicit ESDF neural network performs continual self-supervised learning guided by these grids to generate smooth and continuous maps. The results on multiple scenes show that LGSDF can construct more accurate ESDF maps and meshes compared with SOTA (State Of The Art) explicit and implicit mapping algorithms. The source code of LGSDF is publicly available at https://github.com/BIT-DYN/LGSDF.
OpenGraph: Open-Vocabulary Hierarchical 3D Graph Representation in Large-Scale Outdoor Environments
Mar 28, 2024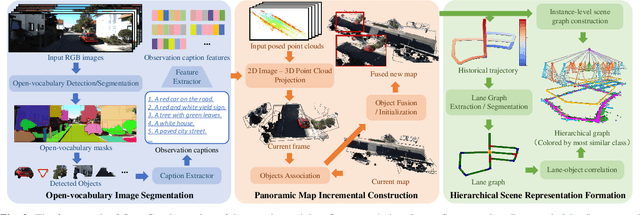
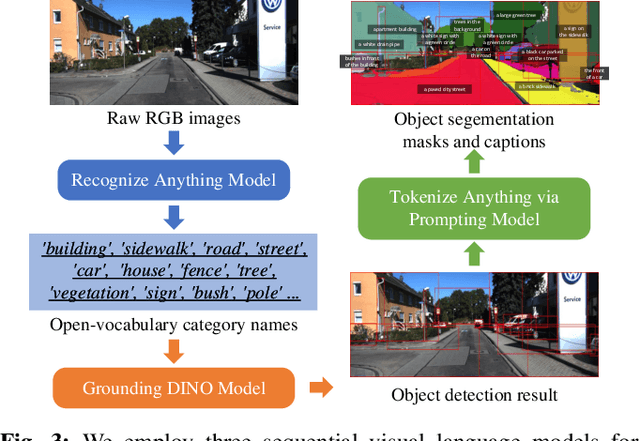

Environment representations endowed with sophisticated semantics are pivotal for facilitating seamless interaction between robots and humans, enabling them to effectively carry out various tasks. Open-vocabulary maps, powered by Visual-Language models (VLMs), possess inherent advantages, including zero-shot learning and support for open-set classes. However, existing open-vocabulary maps are primarily designed for small-scale environments, such as desktops or rooms, and are typically geared towards limited-area tasks involving robotic indoor navigation or in-place manipulation. They face challenges in direct generalization to outdoor environments characterized by numerous objects and complex tasks, owing to limitations in both understanding level and map structure. In this work, we propose OpenGraph, the first open-vocabulary hierarchical graph representation designed for large-scale outdoor environments. OpenGraph initially extracts instances and their captions from visual images, enhancing textual reasoning by encoding them. Subsequently, it achieves 3D incremental object-centric mapping with feature embedding by projecting images onto LiDAR point clouds. Finally, the environment is segmented based on lane graph connectivity to construct a hierarchical graph. Validation results from public dataset SemanticKITTI demonstrate that OpenGraph achieves the highest segmentation and query accuracy. The source code of OpenGraph is publicly available at https://github.com/BIT-DYN/OpenGraph.
Context-Semantic Quality Awareness Network for Fine-Grained Visual Categorization
Mar 15, 2024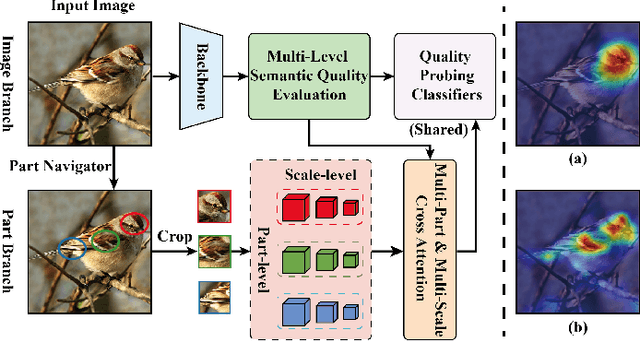
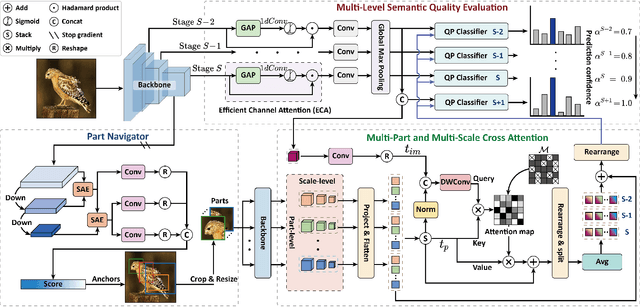
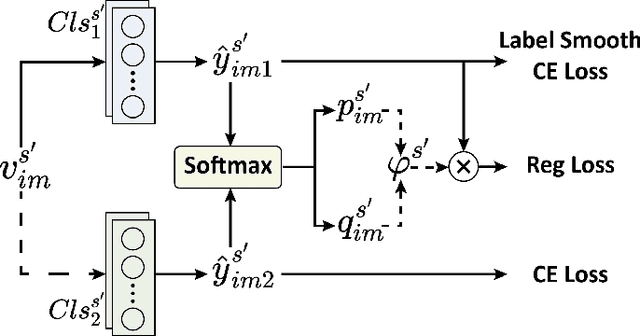
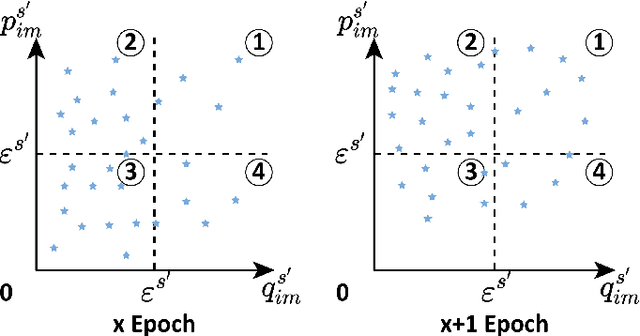
Exploring and mining subtle yet distinctive features between sub-categories with similar appearances is crucial for fine-grained visual categorization (FGVC). However, less effort has been devoted to assessing the quality of extracted visual representations. Intuitively, the network may struggle to capture discriminative features from low-quality samples, which leads to a significant decline in FGVC performance. To tackle this challenge, we propose a weakly supervised Context-Semantic Quality Awareness Network (CSQA-Net) for FGVC. In this network, to model the spatial contextual relationship between rich part descriptors and global semantics for capturing more discriminative details within the object, we design a novel multi-part and multi-scale cross-attention (MPMSCA) module. Before feeding to the MPMSCA module, the part navigator is developed to address the scale confusion problems and accurately identify the local distinctive regions. Furthermore, we propose a generic multi-level semantic quality evaluation module (MLSQE) to progressively supervise and enhance hierarchical semantics from different levels of the backbone network. Finally, context-aware features from MPMSCA and semantically enhanced features from MLSQE are fed into the corresponding quality probing classifiers to evaluate their quality in real-time, thus boosting the discriminability of feature representations. Comprehensive experiments on four popular and highly competitive FGVC datasets demonstrate the superiority of the proposed CSQA-Net in comparison with the state-of-the-art methods.
Design and trajectory tracking control of CuRobot: A Cubic Reversible Robot
Nov 28, 2023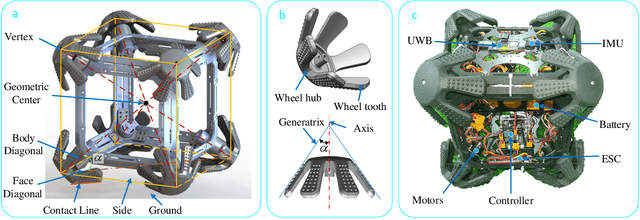
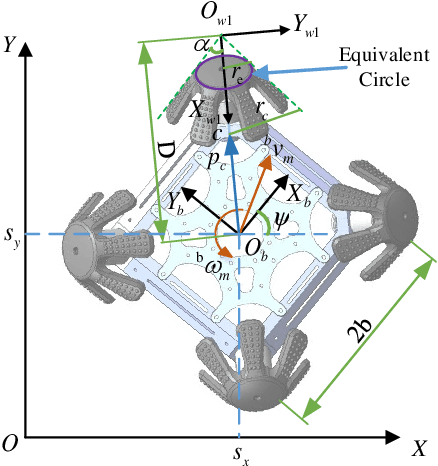
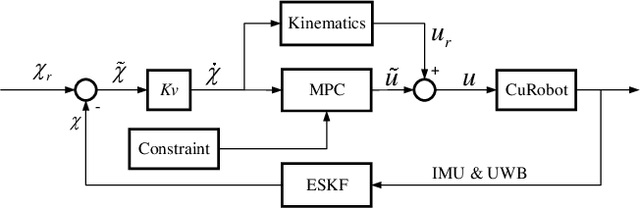
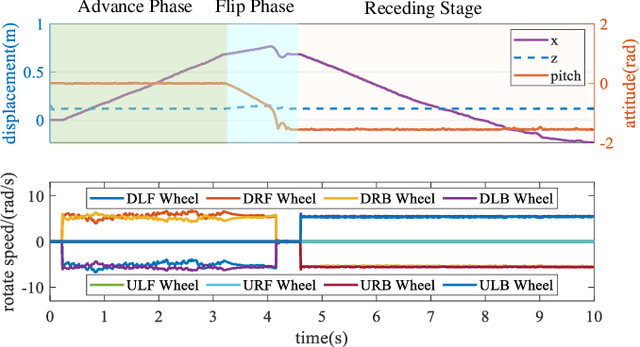
In field environments, numerous robots necessitate manual intervention for restoration of functionality post a turnover, resulting in diminished operational efficiency. This study presents an innovative design solution for a reversible omnidirectional mobile robot denoted as CuRobot, featuring a cube structure, thereby facilitating uninterrupted omnidirectional movement even in the event of flipping. The incorporation of eight conical wheels at the cube vertices ensures consistent omnidirectional motion no matter which face of the cube contacts the ground. Additionally, a kinematic model is formulated for CuRobot, accompanied by the development of a trajectory tracking controller utilizing model predictive control. Through simulation experiments, the correlation between trajectory tracking accuracy and the robot's motion direction is examined. Furthermore, the robot's proficiency in omnidirectional mobility and sustained movement post-flipping is substantiated via both simulation and prototype experiments. This design reduces the inefficiencies associated with manual intervention, thereby increasing the operational robustness of robots in field environments.
Robust Transductive Few-shot Learning via Joint Message Passing and Prototype-based Soft-label Propagation
Nov 28, 2023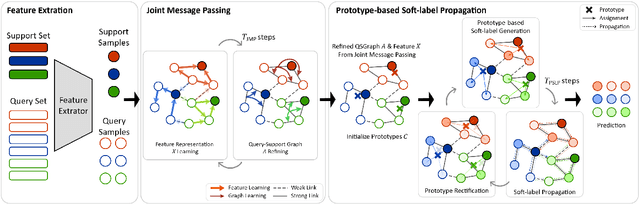
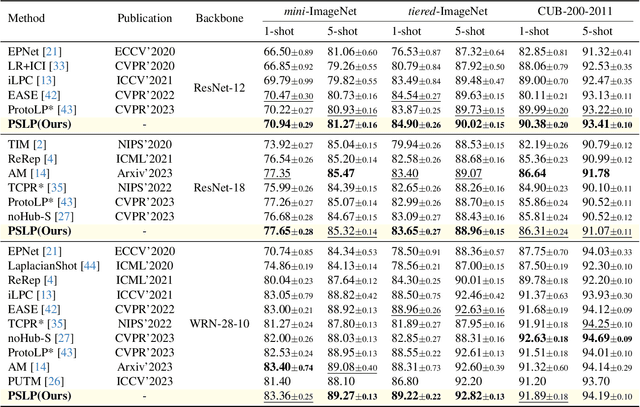
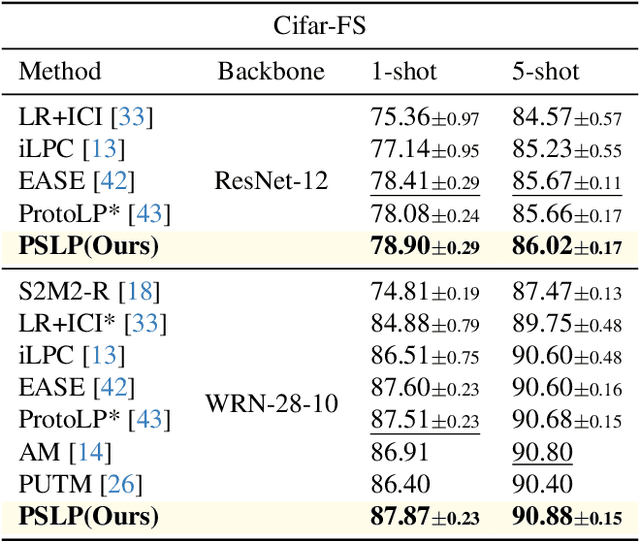
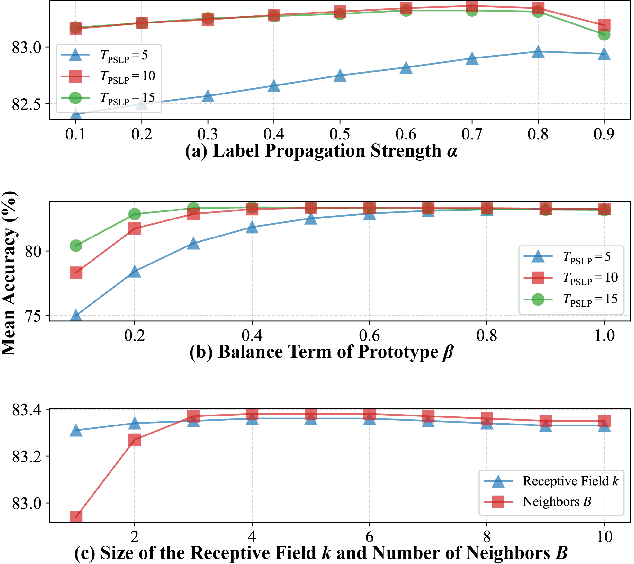
Few-shot learning (FSL) aims to develop a learning model with the ability to generalize to new classes using a few support samples. For transductive FSL tasks, prototype learning and label propagation methods are commonly employed. Prototype methods generally first learn the representative prototypes from the support set and then determine the labels of queries based on the metric between query samples and prototypes. Label propagation methods try to propagate the labels of support samples on the constructed graph encoding the relationships between both support and query samples. This paper aims to integrate these two principles together and develop an efficient and robust transductive FSL approach, termed Prototype-based Soft-label Propagation (PSLP). Specifically, we first estimate the soft-label presentation for each query sample by leveraging prototypes. Then, we conduct soft-label propagation on our learned query-support graph. Both steps are conducted progressively to boost their respective performance. Moreover, to learn effective prototypes for soft-label estimation as well as the desirable query-support graph for soft-label propagation, we design a new joint message passing scheme to learn sample presentation and relational graph jointly. Our PSLP method is parameter-free and can be implemented very efficiently. On four popular datasets, our method achieves competitive results on both balanced and imbalanced settings compared to the state-of-the-art methods. The code will be released upon acceptance.
Density Distribution-based Learning Framework for Addressing Online Continual Learning Challenges
Nov 22, 2023In this paper, we address the challenges of online Continual Learning (CL) by introducing a density distribution-based learning framework. CL, especially the Class Incremental Learning, enables adaptation to new test distributions while continuously learning from a single-pass training data stream, which is more in line with the practical application requirements of real-world scenarios. However, existing CL methods often suffer from catastrophic forgetting and higher computing costs due to complex algorithm designs, limiting their practical use. Our proposed framework overcomes these limitations by achieving superior average accuracy and time-space efficiency, bridging the performance gap between CL and classical machine learning. Specifically, we adopt an independent Generative Kernel Density Estimation (GKDE) model for each CL task. During the testing stage, the GKDEs utilize a self-reported max probability density value to determine which one is responsible for predicting incoming test instances. A GKDE-based learning objective can ensure that samples with the same label are grouped together, while dissimilar instances are pushed farther apart. Extensive experiments conducted on multiple CL datasets validate the effectiveness of our proposed framework. Our method outperforms popular CL approaches by a significant margin, while maintaining competitive time-space efficiency, making our framework suitable for real-world applications. Code will be available at https://github.com/xxxx/xxxx.
Poison Dart Frog: A Clean-Label Attack with Low Poisoning Rate and High Attack Success Rate in the Absence of Training Data
Aug 21, 2023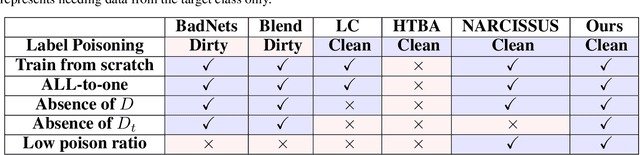

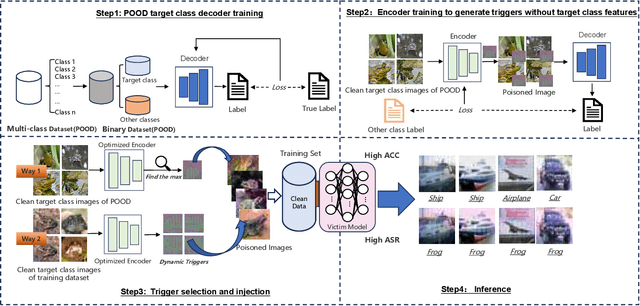

To successfully launch backdoor attacks, injected data needs to be correctly labeled; otherwise, they can be easily detected by even basic data filters. Hence, the concept of clean-label attacks was introduced, which is more dangerous as it doesn't require changing the labels of injected data. To the best of our knowledge, the existing clean-label backdoor attacks largely relies on an understanding of the entire training set or a portion of it. However, in practice, it is very difficult for attackers to have it because of training datasets often collected from multiple independent sources. Unlike all current clean-label attacks, we propose a novel clean label method called 'Poison Dart Frog'. Poison Dart Frog does not require access to any training data; it only necessitates knowledge of the target class for the attack, such as 'frog'. On CIFAR10, Tiny-ImageNet, and TSRD, with a mere 0.1\%, 0.025\%, and 0.4\% poisoning rate of the training set size, respectively, Poison Dart Frog achieves a high Attack Success Rate compared to LC, HTBA, BadNets, and Blend. Furthermore, compared to the state-of-the-art attack, NARCISSUS, Poison Dart Frog achieves similar attack success rates without any training data. Finally, we demonstrate that four typical backdoor defense algorithms struggle to counter Poison Dart Frog.
Few-Shot Point Cloud Semantic Segmentation via Contrastive Self-Supervision and Multi-Resolution Attention
Feb 21, 2023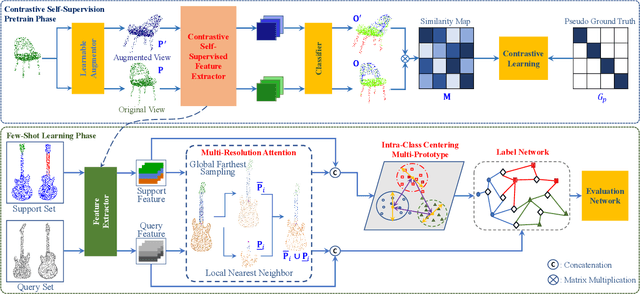

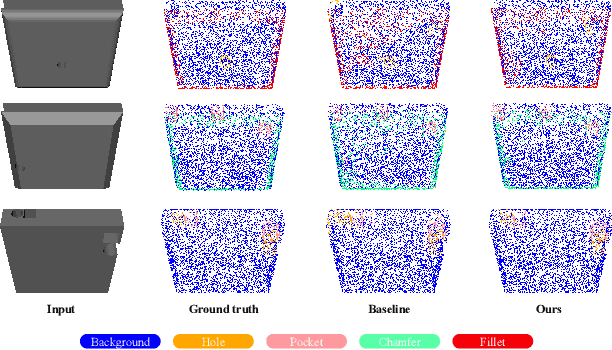
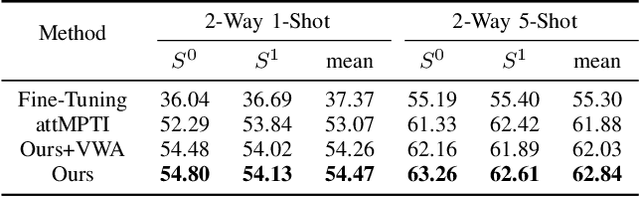
This paper presents an effective few-shot point cloud semantic segmentation approach for real-world applications. Existing few-shot segmentation methods on point cloud heavily rely on the fully-supervised pretrain with large annotated datasets, which causes the learned feature extraction bias to those pretrained classes. However, as the purpose of few-shot learning is to handle unknown/unseen classes, such class-specific feature extraction in pretrain is not ideal to generalize into new classes for few-shot learning. Moreover, point cloud datasets hardly have a large number of classes due to the annotation difficulty. To address these issues, we propose a contrastive self-supervision framework for few-shot learning pretrain, which aims to eliminate the feature extraction bias through class-agnostic contrastive supervision. Specifically, we implement a novel contrastive learning approach with a learnable augmentor for a 3D point cloud to achieve point-wise differentiation, so that to enhance the pretrain with managed overfitting through the self-supervision. Furthermore, we develop a multi-resolution attention module using both the nearest and farthest points to extract the local and global point information more effectively, and a center-concentrated multi-prototype is adopted to mitigate the intra-class sparsity. Comprehensive experiments are conducted to evaluate the proposed approach, which shows our approach achieves state-of-the-art performance. Moreover, a case study on practical CAM/CAD segmentation is presented to demonstrate the effectiveness of our approach for real-world applications.
CAM/CAD Point Cloud Part Segmentation via Few-Shot Learning
Jul 16, 2022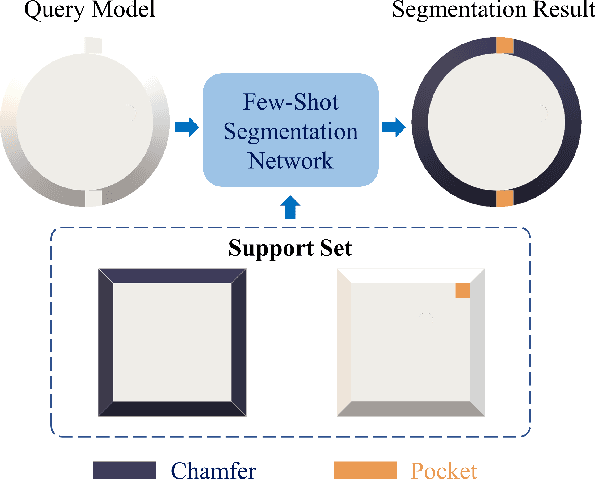
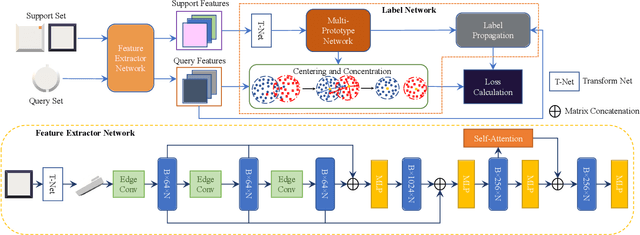
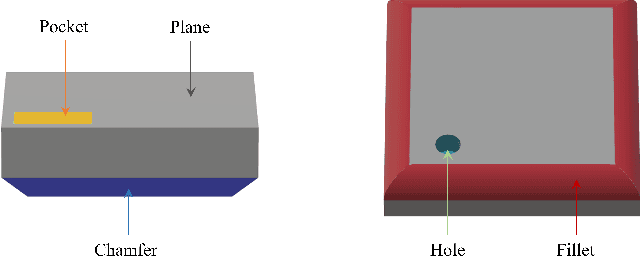
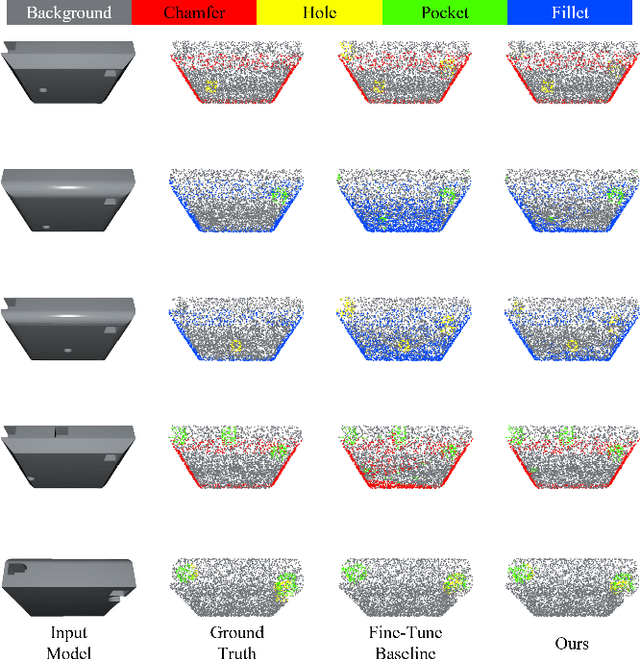
3D part segmentation is an essential step in advanced CAM/CAD workflow. Precise 3D segmentation contributes to lower defective rate of work-pieces produced by the manufacturing equipment (such as computer controlled CNCs), thereby improving work efficiency and attaining the attendant economic benefits. A large class of existing works on 3D model segmentation are mostly based on fully-supervised learning, which trains the AI models with large, annotated datasets. However, the disadvantage is that the resulting models from the fully-supervised learning methodology are highly reliant on the completeness of the available dataset, and its generalization ability is relatively poor to new unknown segmentation types (i.e. further additional novel classes). In this work, we propose and develop a noteworthy few-shot learning-based approach for effective part segmentation in CAM/CAD; and this is designed to significantly enhance its generalization ability and flexibly adapt to new segmentation tasks by using only relatively rather few samples. As a result, it not only reduces the requirements for the usually unattainable and exhaustive completeness of supervision datasets, but also improves the flexibility for real-world applications. As further improvement and innovation, we additionally adopt the transform net and the center loss block in the network. These characteristics serve to improve the comprehension for 3D features of the various possible instances of the whole work-piece and ensure the close distribution of the same class in feature space.
Masked Self-Supervision for Remaining Useful Lifetime Prediction in Machine Tools
Jul 04, 2022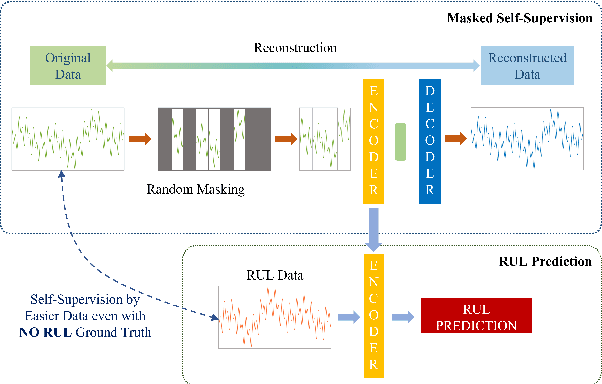
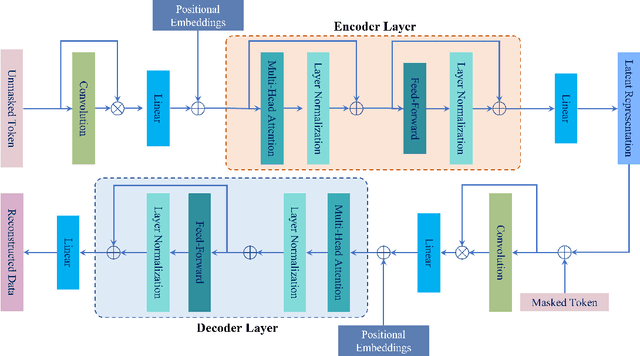


Prediction of Remaining Useful Lifetime(RUL) in the modern manufacturing and automation workplace for machines and tools is essential in Industry 4.0. This is clearly evident as continuous tool wear, or worse, sudden machine breakdown will lead to various manufacturing failures which would clearly cause economic loss. With the availability of deep learning approaches, the great potential and prospect of utilizing these for RUL prediction have resulted in several models which are designed driven by operation data of manufacturing machines. Current efforts in these which are based on fully-supervised models heavily rely on the data labeled with their RULs. However, the required RUL prediction data (i.e. the annotated and labeled data from faulty and/or degraded machines) can only be obtained after the machine breakdown occurs. The scarcity of broken machines in the modern manufacturing and automation workplace in real-world situations increases the difficulty of getting sufficient annotated and labeled data. In contrast, the data from healthy machines is much easier to be collected. Noting this challenge and the potential for improved effectiveness and applicability, we thus propose (and also fully develop) a method based on the idea of masked autoencoders which will utilize unlabeled data to do self-supervision. In thus the work here, a noteworthy masked self-supervised learning approach is developed and utilized. This is designed to seek to build a deep learning model for RUL prediction by utilizing unlabeled data. The experiments to verify the effectiveness of this development are implemented on the C-MAPSS datasets (which are collected from the data from the NASA turbofan engine). The results rather clearly show that our development and approach here perform better, in both accuracy and effectiveness, for RUL prediction when compared with approaches utilizing a fully-supervised model.