 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJialu Huang
Unsupervised Image-to-Image Translation via Pre-trained StyleGAN2 Network
Oct 27, 2020




Image-to-Image (I2I) translation is a heated topic in academia, and it also has been applied in real-world industry for tasks like image synthesis, super-resolution, and colorization. However, traditional I2I translation methods train data in two or more domains together. This requires lots of computation resources. Moreover, the results are of lower quality, and they contain many more artifacts. The training process could be unstable when the data in different domains are not balanced, and modal collapse is more likely to happen. We proposed a new I2I translation method that generates a new model in the target domain via a series of model transformations on a pre-trained StyleGAN2 model in the source domain. After that, we proposed an inversion method to achieve the conversion between an image and its latent vector. By feeding the latent vector into the generated model, we can perform I2I translation between the source domain and target domain. Both qualitative and quantitative evaluations were conducted to prove that the proposed method can achieve outstanding performance in terms of image quality, diversity and semantic similarity to the input and reference images compared to state-of-the-art works.
Multi-Density Sketch-to-Image Translation Network
Jun 18, 2020



Sketch-to-image (S2I) translation plays an important role in image synthesis and manipulation tasks, such as photo editing and colorization. Some specific S2I translation including sketch-to-photo and sketch-to-painting can be used as powerful tools in the art design industry. However, previous methods only support S2I translation with a single level of density, which gives less flexibility to users for controlling the input sketches. In this work, we propose the first multi-level density sketch-to-image translation framework, which allows the input sketch to cover a wide range from rough object outlines to micro structures. Moreover, to tackle the problem of noncontinuous representation of multi-level density input sketches, we project the density level into a continuous latent space, which can then be linearly controlled by a parameter. This allows users to conveniently control the densities of input sketches and generation of images. Moreover, our method has been successfully verified on various datasets for different applications including face editing, multi-modal sketch-to-photo translation, and anime colorization, providing coarse-to-fine levels of controls to these applications.
Semantic Example Guided Image-to-Image Translation
Oct 04, 2019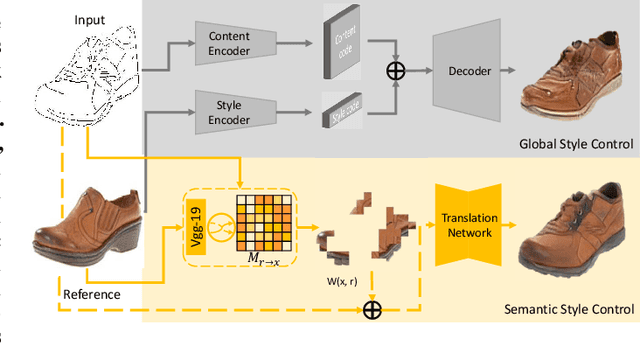


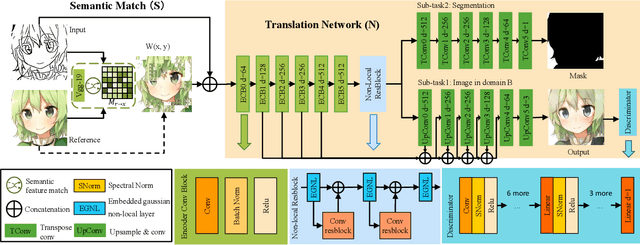
Many image-to-image (I2I) translation problems are in nature of high diversity that a single input may have various counterparts. Prior works proposed the multi-modal network that can build a many-to-many mapping between two visual domains. However, most of them are guided by sampled noises. Some others encode the reference images into a latent vector, by which the semantic information of the reference image will be washed away. In this work, we aim to provide a solution to control the output based on references semantically. Given a reference image and an input in another domain, a semantic matching is first performed between the two visual contents and generates the auxiliary image, which is explicitly encouraged to preserve semantic characteristics of the reference. A deep network then is used for I2I translation and the final outputs are expected to be semantically similar to both the input and the reference; however, no such paired data can satisfy that dual-similarity in a supervised fashion, so we build up a self-supervised framework to serve the training purpose. We improve the quality and diversity of the outputs by employing non-local blocks and a multi-task architecture. We assess the proposed method through extensive qualitative and quantitative evaluations and also presented comparisons with several state-of-art models.