 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaming Tang
DCRMTA: Unbiased Causal Representation for Multi-touch Attribution
Feb 05, 2024
Multi-touch attribution (MTA) currently plays a pivotal role in achieving a fair estimation of the contributions of each advertising touchpoint to-wards conversion behavior, deeply influencing budget allocation and advertising recommenda-tion. Previous works attempted to eliminate the bias caused by user preferences to achieve the unbiased assumption of the conversion model. The multi-model collaboration method is not ef-ficient, and the complete elimination of user in-fluence also eliminates the causal effect of user features on conversion, resulting in limited per-formance of the conversion model. This paper re-defines the causal effect of user features on con-versions and proposes a novel end-to-end ap-proach, Deep Causal Representation for MTA (DCRMTA). Our model focuses on extracting causa features between conversions and users while eliminating confounding variables. Fur-thermore, extensive experiments demonstrate DCRMTA's superior performance in converting prediction across varying data distributions, while also effectively attributing value across dif-ferent advertising channels.
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Jun 01, 2023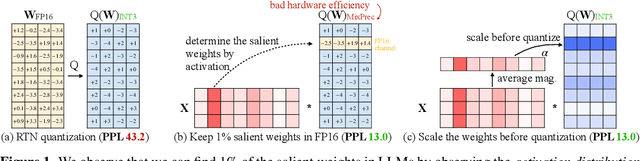
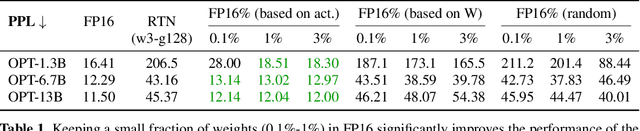
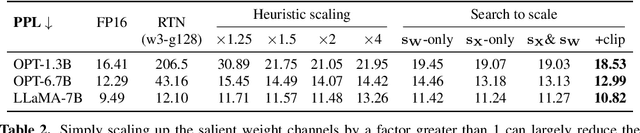
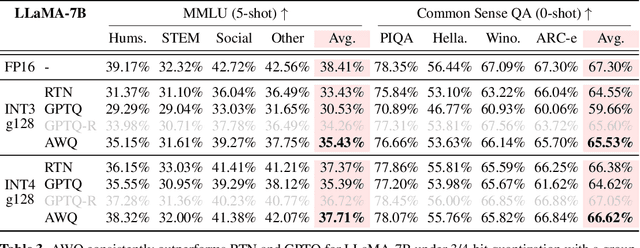
Large language models (LLMs) have shown excellent performance on various tasks, but the astronomical model size raises the hardware barrier for serving (memory size) and slows down token generation (memory bandwidth). In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardware-friendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs' generalization ability on different domains and modalities, without overfitting to the calibration set; it also does not rely on any data layout reordering, maintaining the hardware efficiency. AWQ outperforms existing work on various language modeling, common sense QA, and domain-specific benchmarks. Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multi-modal LMs. We also implement efficient tensor core kernels with reorder-free online dequantization to accelerate AWQ, achieving a 1.45x speedup over GPTQ and is 1.85x faster than the cuBLAS FP16 implementation. Our method provides a turn-key solution to compress LLMs to 3/4 bits for efficient deployment.