 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaming Zhou
CKGConv: General Graph Convolution with Continuous Kernels
Apr 21, 2024
The existing definitions of graph convolution, either from spatial or spectral perspectives, are inflexible and not unified. Defining a general convolution operator in the graph domain is challenging due to the lack of canonical coordinates, the presence of irregular structures, and the properties of graph symmetries. In this work, we propose a novel graph convolution framework by parameterizing the kernels as continuous functions of pseudo-coordinates derived via graph positional encoding. We name this Continuous Kernel Graph Convolution (CKGConv). Theoretically, we demonstrate that CKGConv is flexible and expressive. CKGConv encompasses many existing graph convolutions, and exhibits the same expressiveness as graph transformers in terms of distinguishing non-isomorphic graphs. Empirically, we show that CKGConv-based Networks outperform existing graph convolutional networks and perform comparably to the best graph transformers across a variety of graph datasets.
Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition
Mar 03, 2024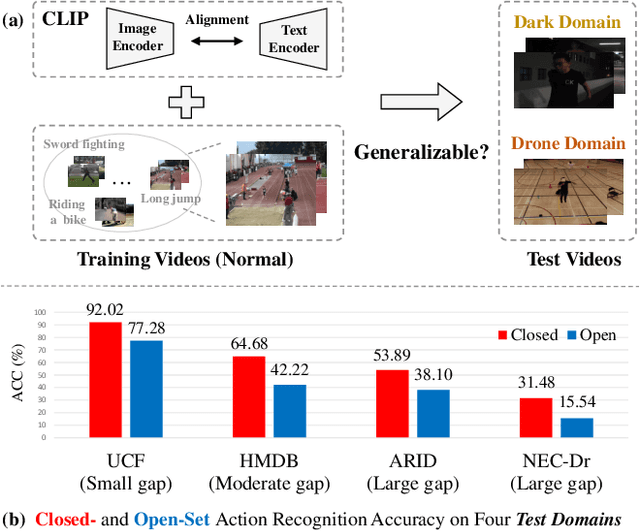
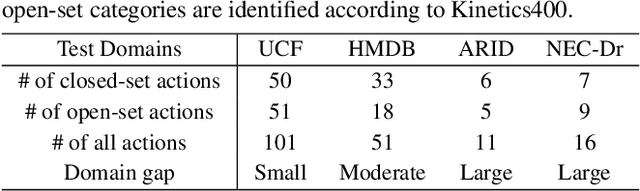
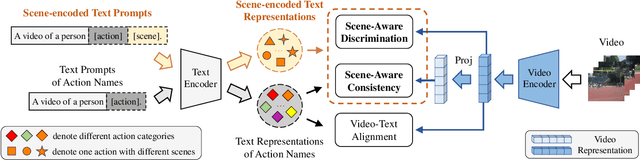
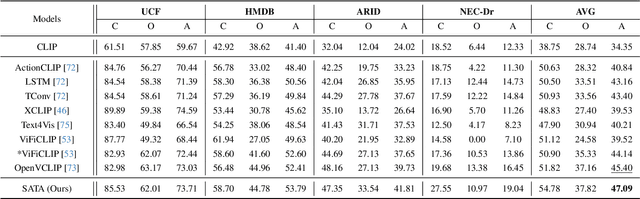
Contrastive Language-Image Pretraining (CLIP) has shown remarkable open-vocabulary abilities across various image understanding tasks. Building upon this impressive success, recent pioneer works have proposed to adapt the powerful CLIP to video data, leading to efficient and effective video learners for open-vocabulary action recognition. Inspired by the fact that humans perform actions in diverse environments, our work delves into an intriguing question: Can CLIP-based video learners effectively generalize to video domains they have not encountered during training? To answer this, we establish a CROSS-domain Open-Vocabulary Action recognition benchmark named XOV-Action, and conduct a comprehensive evaluation of five state-of-the-art CLIP-based video learners under various types of domain gaps. Our evaluation demonstrates that previous methods exhibit limited action recognition performance in unseen video domains, revealing potential challenges of the cross-domain open-vocabulary action recognition task. To address this task, our work focuses on a critical challenge, namely scene bias, and we accordingly contribute a novel scene-aware video-text alignment method. Our key idea is to distinguish video representations apart from scene-encoded text representations, aiming to learn scene-agnostic video representations for recognizing actions across domains. Extensive experimental results demonstrate the effectiveness of our method. The benchmark and code will be available at https://github.com/KunyuLin/XOV-Action/.
ActionHub: A Large-scale Action Video Description Dataset for Zero-shot Action Recognition
Jan 22, 2024Zero-shot action recognition (ZSAR) aims to learn an alignment model between videos and class descriptions of seen actions that is transferable to unseen actions. The text queries (class descriptions) used in existing ZSAR works, however, are often short action names that fail to capture the rich semantics in the videos, leading to misalignment. With the intuition that video content descriptions (e.g., video captions) can provide rich contextual information of visual concepts in videos, we propose to utilize human annotated video descriptions to enrich the semantics of the class descriptions of each action. However, all existing action video description datasets are limited in terms of the number of actions, the semantics of video descriptions, etc. To this end, we collect a large-scale action video descriptions dataset named ActionHub, which covers a total of 1,211 common actions and provides 3.6 million action video descriptions. With the proposed ActionHub dataset, we further propose a novel Cross-modality and Cross-action Modeling (CoCo) framework for ZSAR, which consists of a Dual Cross-modality Alignment module and a Cross-action Invariance Mining module. Specifically, the Dual Cross-modality Alignment module utilizes both action labels and video descriptions from ActionHub to obtain rich class semantic features for feature alignment. The Cross-action Invariance Mining module exploits a cycle-reconstruction process between the class semantic feature spaces of seen actions and unseen actions, aiming to guide the model to learn cross-action invariant representations. Extensive experimental results demonstrate that our CoCo framework significantly outperforms the state-of-the-art on three popular ZSAR benchmarks (i.e., Kinetics-ZSAR, UCF101 and HMDB51) under two different learning protocols in ZSAR. We will release our code, models, and the proposed ActionHub dataset.
kNN-CTC: Enhancing ASR via Retrieval of CTC Pseudo Labels
Dec 21, 2023The success of retrieval-augmented language models in various natural language processing (NLP) tasks has been constrained in automatic speech recognition (ASR) applications due to challenges in constructing fine-grained audio-text datastores. This paper presents kNN-CTC, a novel approach that overcomes these challenges by leveraging Connectionist Temporal Classification (CTC) pseudo labels to establish frame-level audio-text key-value pairs, circumventing the need for precise ground truth alignments. We further introduce a skip-blank strategy, which strategically ignores CTC blank frames, to reduce datastore size. kNN-CTC incorporates a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems, achieving significant improvements in performance. By incorporating a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems and leveraging a fine-grained, pruned datastore, kNN-CTC consistently achieves substantial improvements in performance under various experimental settings. Our code is available at https://github.com/NKU-HLT/KNN-CTC.
GeoDeformer: Geometric Deformable Transformer for Action Recognition
Nov 29, 2023Vision transformers have recently emerged as an effective alternative to convolutional networks for action recognition. However, vision transformers still struggle with geometric variations prevalent in video data. This paper proposes a novel approach, GeoDeformer, designed to capture the variations inherent in action video by integrating geometric comprehension directly into the ViT architecture. Specifically, at the core of GeoDeformer is the Geometric Deformation Predictor, a module designed to identify and quantify potential spatial and temporal geometric deformations within the given video. Spatial deformations adjust the geometry within individual frames, while temporal deformations capture the cross-frame geometric dynamics, reflecting motion and temporal progression. To demonstrate the effectiveness of our approach, we incorporate it into the established MViTv2 framework, replacing the standard self-attention blocks with GeoDeformer blocks. Our experiments at UCF101, HMDB51, and Mini-K200 achieve significant increases in both Top-1 and Top-5 accuracy, establishing new state-of-the-art results with only a marginal increase in computational cost. Additionally, visualizations affirm that GeoDeformer effectively manifests explicit geometric deformations and minimizes geometric variations. Codes and checkpoints will be released.
AdaFocus: Towards End-to-end Weakly Supervised Learning for Long-Video Action Understanding
Nov 28, 2023Developing end-to-end models for long-video action understanding tasks presents significant computational and memory challenges. Existing works generally build models on long-video features extracted by off-the-shelf action recognition models, which are trained on short-video datasets in different domains, making the extracted features suffer domain discrepancy. To avoid this, action recognition models can be end-to-end trained on clips, which are trimmed from long videos and labeled using action interval annotations. Such fully supervised annotations are expensive to collect. Thus, a weakly supervised method is needed for long-video action understanding at scale. Under the weak supervision setting, action labels are provided for the whole video without precise start and end times of the action clip. To this end, we propose an AdaFocus framework. AdaFocus estimates the spike-actionness and temporal positions of actions, enabling it to adaptively focus on action clips that facilitate better training without the need for precise annotations. Experiments on three long-video datasets show its effectiveness. Remarkably, on two of datasets, models trained with AdaFocus under weak supervision outperform those trained under full supervision. Furthermore, we form a weakly supervised feature extraction pipeline with our AdaFocus, which enables significant improvements on three long-video action understanding tasks.
Diversifying Spatial-Temporal Perception for Video Domain Generalization
Oct 27, 2023Video domain generalization aims to learn generalizable video classification models for unseen target domains by training in a source domain. A critical challenge of video domain generalization is to defend against the heavy reliance on domain-specific cues extracted from the source domain when recognizing target videos. To this end, we propose to perceive diverse spatial-temporal cues in videos, aiming to discover potential domain-invariant cues in addition to domain-specific cues. We contribute a novel model named Spatial-Temporal Diversification Network (STDN), which improves the diversity from both space and time dimensions of video data. First, our STDN proposes to discover various types of spatial cues within individual frames by spatial grouping. Then, our STDN proposes to explicitly model spatial-temporal dependencies between video contents at multiple space-time scales by spatial-temporal relation modeling. Extensive experiments on three benchmarks of different types demonstrate the effectiveness and versatility of our approach.
PostRainBench: A comprehensive benchmark and a new model for precipitation forecasting
Oct 05, 2023Accurate precipitation forecasting is a vital challenge of both scientific and societal importance. Data-driven approaches have emerged as a widely used solution for addressing this challenge. However, solely relying on data-driven approaches has limitations in modeling the underlying physics, making accurate predictions difficult. Coupling AI-based post-processing techniques with traditional Numerical Weather Prediction (NWP) methods offers a more effective solution for improving forecasting accuracy. Despite previous post-processing efforts, accurately predicting heavy rainfall remains challenging due to the imbalanced precipitation data across locations and complex relationships between multiple meteorological variables. To address these limitations, we introduce the PostRainBench, a comprehensive multi-variable NWP post-processing benchmark consisting of three datasets for NWP post-processing-based precipitation forecasting. We propose CAMT, a simple yet effective Channel Attention Enhanced Multi-task Learning framework with a specially designed weighted loss function. Its flexible design allows for easy plug-and-play integration with various backbones. Extensive experimental results on the proposed benchmark show that our method outperforms state-of-the-art methods by 6.3%, 4.7%, and 26.8% in rain CSI on the three datasets respectively. Most notably, our model is the first deep learning-based method to outperform traditional Numerical Weather Prediction (NWP) approaches in extreme precipitation conditions. It shows improvements of 15.6%, 17.4%, and 31.8% over NWP predictions in heavy rain CSI on respective datasets. These results highlight the potential impact of our model in reducing the severe consequences of extreme weather events.
MADI: Inter-domain Matching and Intra-domain Discrimination for Cross-domain Speech Recognition
Feb 22, 2023

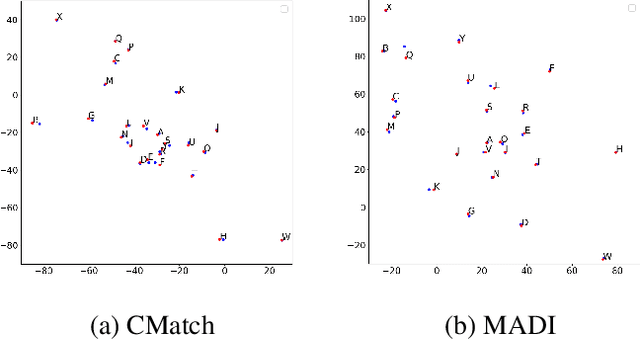
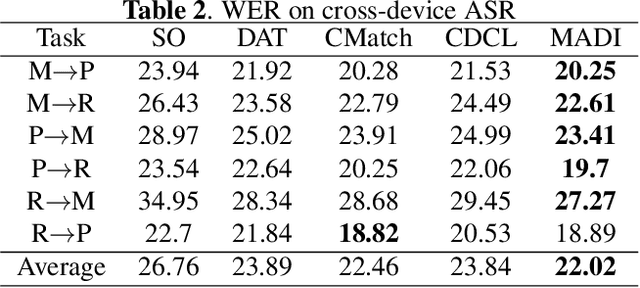
End-to-end automatic speech recognition (ASR) usually suffers from performance degradation when applied to a new domain due to domain shift. Unsupervised domain adaptation (UDA) aims to improve the performance on the unlabeled target domain by transferring knowledge from the source to the target domain. To improve transferability, existing UDA approaches mainly focus on matching the distributions of the source and target domains globally and/or locally, while ignoring the model discriminability. In this paper, we propose a novel UDA approach for ASR via inter-domain MAtching and intra-domain DIscrimination (MADI), which improves the model transferability by fine-grained inter-domain matching and discriminability by intra-domain contrastive discrimination simultaneously. Evaluations on the Libri-Adapt dataset demonstrate the effectiveness of our approach. MADI reduces the relative word error rate (WER) on cross-device and cross-environment ASR by 17.7% and 22.8%, respectively.