 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaxin Xu
Inverse Molecular Design with Multi-Conditional Diffusion Guidance
Jan 24, 2024
Inverse molecular design with diffusion models holds great potential for advancements in material and drug discovery. Despite success in unconditional molecule generation, integrating multiple properties such as synthetic score and gas permeability as condition constraints into diffusion models remains unexplored. We introduce multi-conditional diffusion guidance. The proposed Transformer-based denoising model has a condition encoder that learns the representations of numerical and categorical conditions. The denoising model, consisting of a structure encoder-decoder, is trained for denoising under the representation of conditions. The diffusion process becomes graph-dependent to accurately estimate graph-related noise in molecules, unlike the previous models that focus solely on the marginal distributions of atoms or bonds. We extensively validate our model for multi-conditional polymer and small molecule generation. Results demonstrate our superiority across metrics from distribution learning to condition control for molecular properties. An inverse polymer design task for gas separation with feedback from domain experts further demonstrates its practical utility.
Data-Centric Learning from Unlabeled Graphs with Diffusion Model
Mar 17, 2023
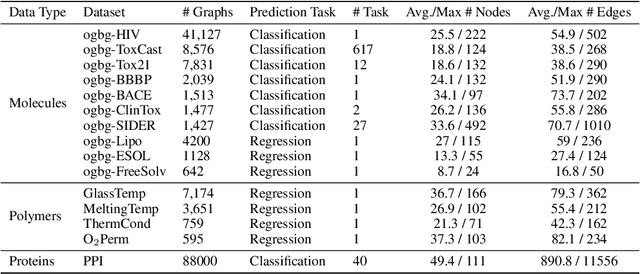
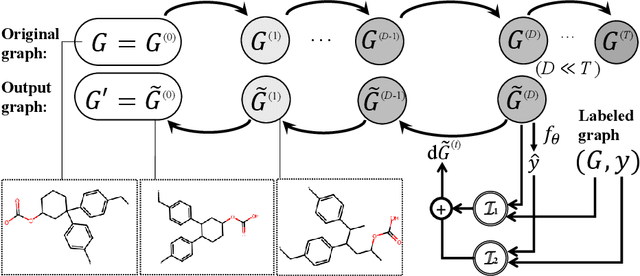
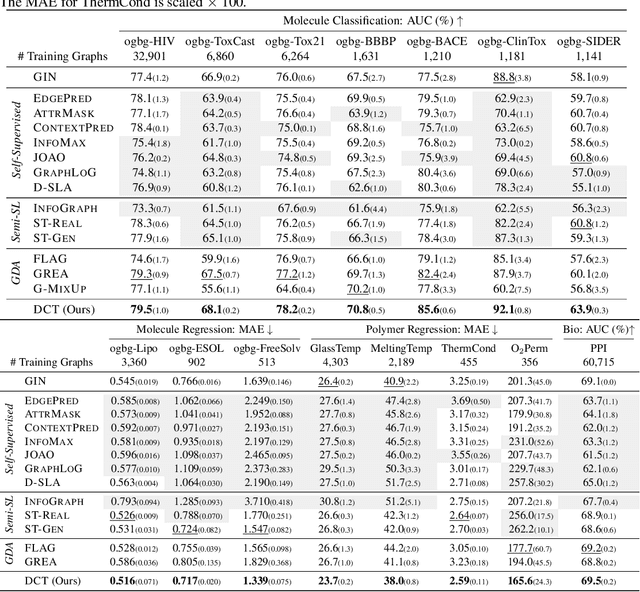
Graph property prediction tasks are important and numerous. While each task offers a small size of labeled examples, unlabeled graphs have been collected from various sources and at a large scale. A conventional approach is training a model with the unlabeled graphs on self-supervised tasks and then fine-tuning the model on the prediction tasks. However, the self-supervised task knowledge could not be aligned or sometimes conflicted with what the predictions needed. In this paper, we propose to extract the knowledge underlying the large set of unlabeled graphs as a specific set of useful data points to augment each property prediction model. We use a diffusion model to fully utilize the unlabeled graphs and design two new objectives to guide the model's denoising process with each task's labeled data to generate task-specific graph examples and their labels. Experiments demonstrate that our data-centric approach performs significantly better than fourteen existing various methods on fifteen tasks. The performance improvement brought by unlabeled data is visible as the generated labeled examples unlike self-supervised learning.
Graph Rationalization with Environment-based Augmentations
Jun 06, 2022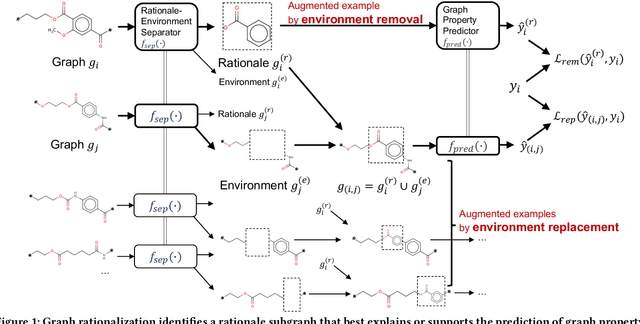
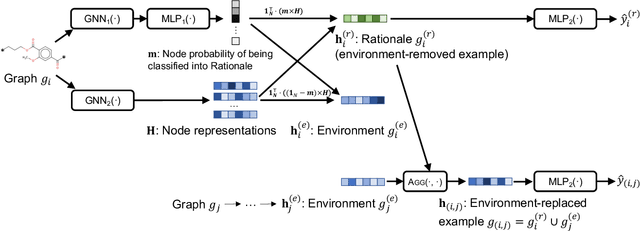
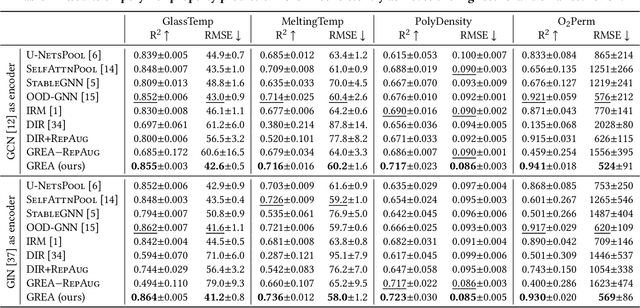
Rationale is defined as a subset of input features that best explains or supports the prediction by machine learning models. Rationale identification has improved the generalizability and interpretability of neural networks on vision and language data. In graph applications such as molecule and polymer property prediction, identifying representative subgraph structures named as graph rationales plays an essential role in the performance of graph neural networks. Existing graph pooling and/or distribution intervention methods suffer from lack of examples to learn to identify optimal graph rationales. In this work, we introduce a new augmentation operation called environment replacement that automatically creates virtual data examples to improve rationale identification. We propose an efficient framework that performs rationale-environment separation and representation learning on the real and augmented examples in latent spaces to avoid the high complexity of explicit graph decoding and encoding. Comparing against recent techniques, experiments on seven molecular and four polymer real datasets demonstrate the effectiveness and efficiency of the proposed augmentation-based graph rationalization framework.
Literature Review: Human Segmentation with Static Camera
Oct 28, 2019

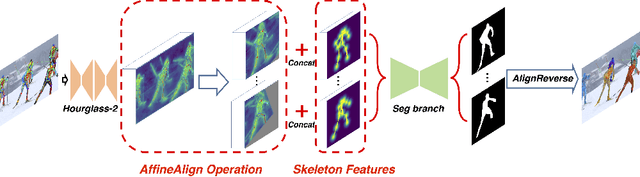
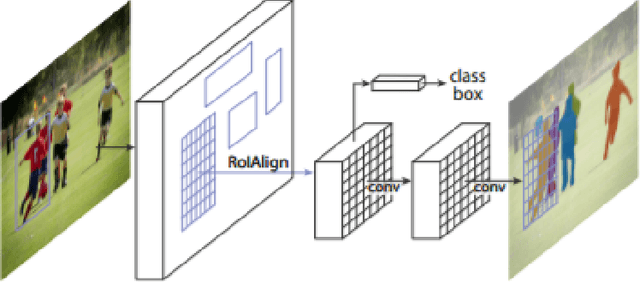
Our research topic is Human segmentation with static camera. This topic can be divided into three sub-tasks, which are object detection, instance identification and segmentation. These sub-tasks are three closely related subjects. The development of each subject has great impact on the other two fields. In this literature review, we will first introduce the background of human segmentation and then talk about issues related to the above three fields as well as how they interact with each other.
House Price Prediction Using LSTM
Sep 25, 2017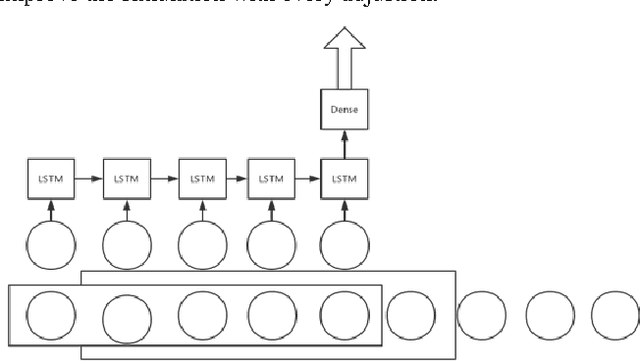
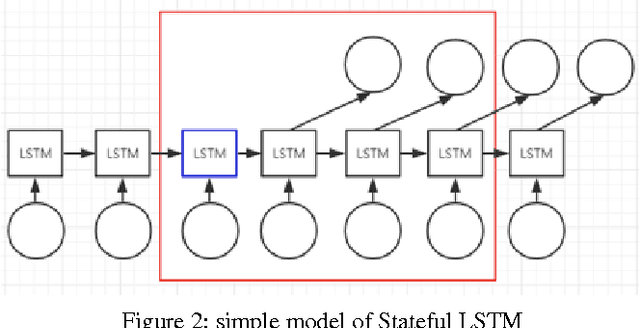
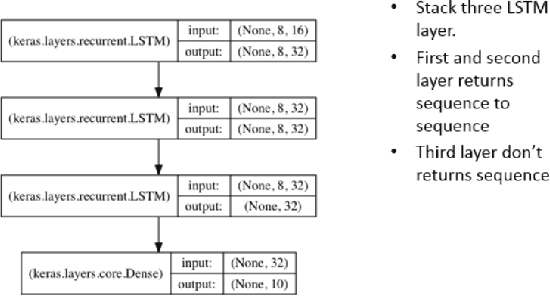
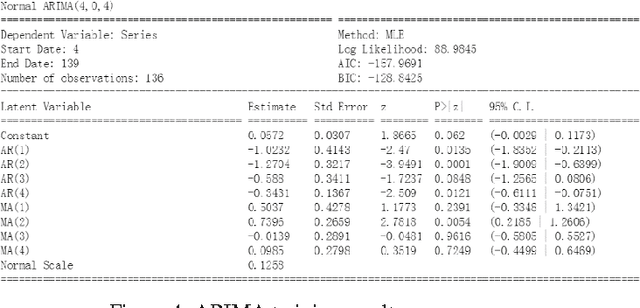
In this paper, we use the house price data ranging from January 2004 to October 2016 to predict the average house price of November and December in 2016 for each district in Beijing, Shanghai, Guangzhou and Shenzhen. We apply Autoregressive Integrated Moving Average model to generate the baseline while LSTM networks to build prediction model. These algorithms are compared in terms of Mean Squared Error. The result shows that the LSTM model has excellent properties with respect to predict time series. Also, stateful LSTM networks and stack LSTM networks are employed to further study the improvement of accuracy of the house prediction model.