 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Liang
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024

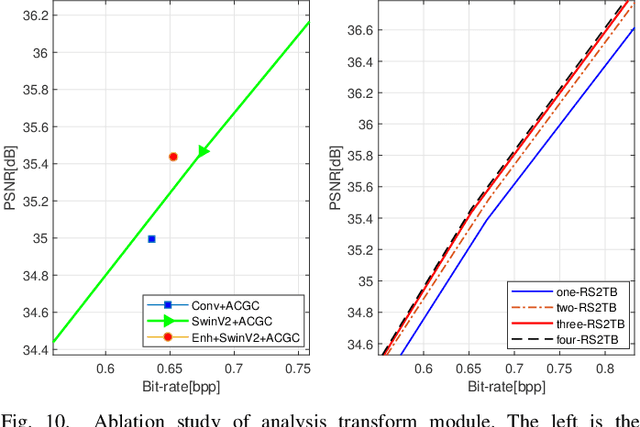


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
A Comprehensive Study of Multimodal Large Language Models for Image Quality Assessment
Mar 16, 2024
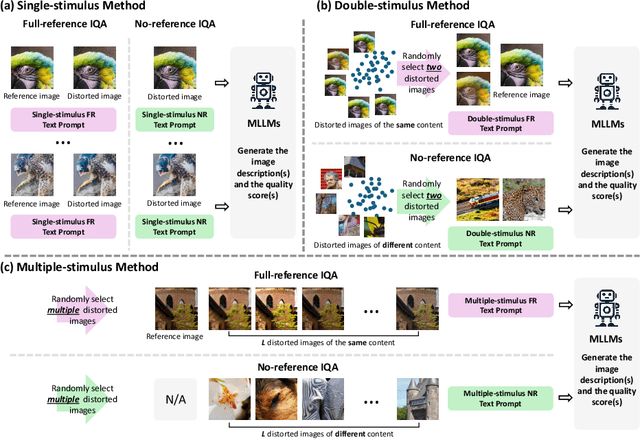
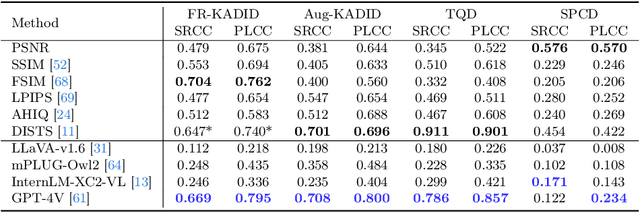

While Multimodal Large Language Models (MLLMs) have experienced significant advancement on visual understanding and reasoning, their potentials to serve as powerful, flexible, interpretable, and text-driven models for Image Quality Assessment (IQA) remains largely unexplored. In this paper, we conduct a comprehensive and systematic study of prompting MLLMs for IQA. Specifically, we first investigate nine prompting systems for MLLMs as the combinations of three standardized testing procedures in psychophysics (i.e., the single-stimulus, double-stimulus, and multiple-stimulus methods) and three popular prompting strategies in natural language processing (i.e., the standard, in-context, and chain-of-thought prompting). We then present a difficult sample selection procedure, taking into account sample diversity and uncertainty, to further challenge MLLMs equipped with the respective optimal prompting systems. We assess three open-source and one close-source MLLMs on several visual attributes of image quality (e.g., structural and textural distortions, color differences, and geometric transformations) in both full-reference and no-reference scenarios. Experimental results show that only the close-source GPT-4V provides a reasonable account for human perception of image quality, but is weak at discriminating fine-grained quality variations (e.g., color differences) and at comparing visual quality of multiple images, tasks humans can perform effortlessly.
Perception-Distortion Balanced Super-Resolution: A Multi-Objective Optimization Perspective
Dec 24, 2023High perceptual quality and low distortion degree are two important goals in image restoration tasks such as super-resolution (SR). Most of the existing SR methods aim to achieve these goals by minimizing the corresponding yet conflicting losses, such as the $\ell_1$ loss and the adversarial loss. Unfortunately, the commonly used gradient-based optimizers, such as Adam, are hard to balance these objectives due to the opposite gradient decent directions of the contradictory losses. In this paper, we formulate the perception-distortion trade-off in SR as a multi-objective optimization problem and develop a new optimizer by integrating the gradient-free evolutionary algorithm (EA) with gradient-based Adam, where EA and Adam focus on the divergence and convergence of the optimization directions respectively. As a result, a population of optimal models with different perception-distortion preferences is obtained. We then design a fusion network to merge these models into a single stronger one for an effective perception-distortion trade-off. Experiments demonstrate that with the same backbone network, the perception-distortion balanced SR model trained by our method can achieve better perceptual quality than its competitors while attaining better reconstruction fidelity. Codes and models can be found at https://github.com/csslc/EA-Adam.
Guided Image Restoration via Simultaneous Feature and Image Guided Fusion
Dec 14, 2023
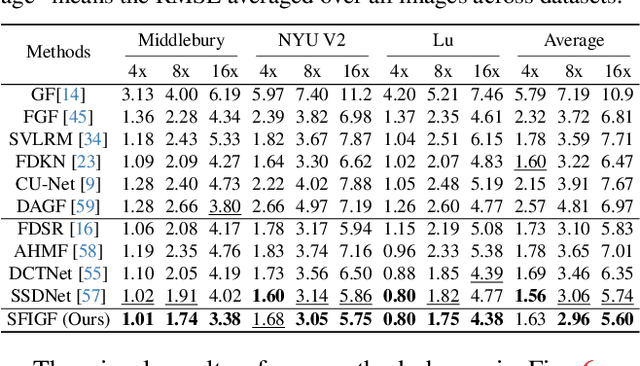
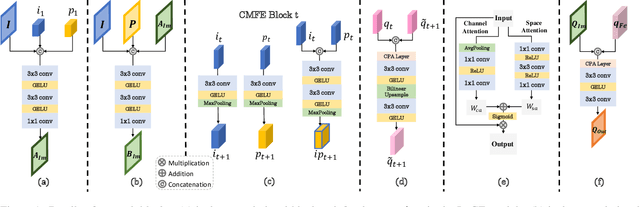
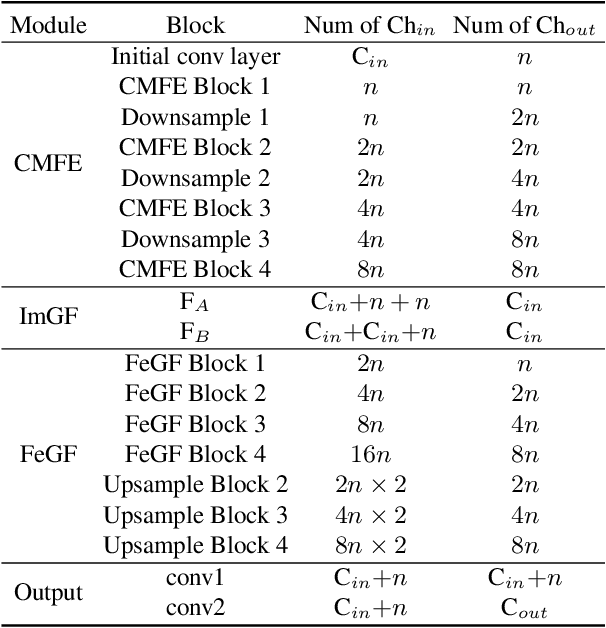
Guided image restoration (GIR), such as guided depth map super-resolution and pan-sharpening, aims to enhance a target image using guidance information from another image of the same scene. Currently, joint image filtering-inspired deep learning-based methods represent the state-of-the-art for GIR tasks. Those methods either deal with GIR in an end-to-end way by elaborately designing filtering-oriented deep neural network (DNN) modules, focusing on the feature-level fusion of inputs; or explicitly making use of the traditional joint filtering mechanism by parameterizing filtering coefficients with DNNs, working on image-level fusion. The former ones are good at recovering contextual information but tend to lose fine-grained details, while the latter ones can better retain textual information but might lead to content distortions. In this work, to inherit the advantages of both methodologies while mitigating their limitations, we proposed a Simultaneous Feature and Image Guided Fusion (SFIGF) network, that simultaneously considers feature and image-level guided fusion following the guided filter (GF) mechanism. In the feature domain, we connect the cross-attention (CA) with GF, and propose a GF-inspired CA module for better feature-level fusion; in the image domain, we fully explore the GF mechanism and design GF-like structure for better image-level fusion. Since guided fusion is implemented in both feature and image domains, the proposed SFIGF is expected to faithfully reconstruct both contextual and textual information from sources and thus lead to better GIR results. We apply SFIGF to 4 typical GIR tasks, and experimental results on these tasks demonstrate its effectiveness and general availability.
MRGazer: Decoding Eye Gaze Points from Functional Magnetic Resonance Imaging in Individual Space
Nov 27, 2023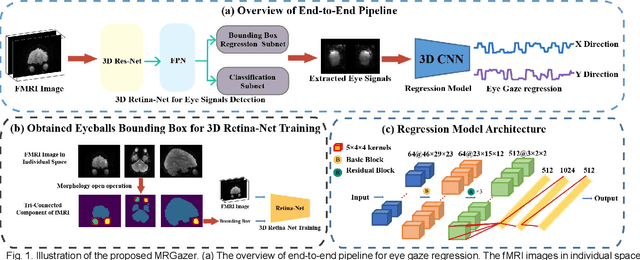

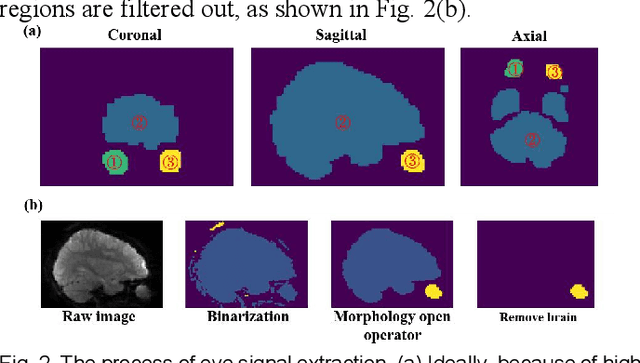
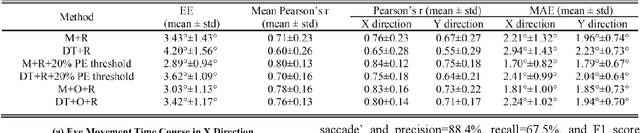
Eye-tracking research has proven valuable in understanding numerous cognitive functions. Recently, Frey et al. provided an exciting deep learning method for learning eye movements from fMRI data. However, it needed to co-register fMRI into standard space to obtain eyeballs masks, and thus required additional templates and was time consuming. To resolve this issue, in this paper, we propose a framework named MRGazer for predicting eye gaze points from fMRI in individual space. The MRGazer consisted of eyeballs extraction module and a residual network-based eye gaze prediction. Compared to the previous method, the proposed framework skips the fMRI co-registration step, simplifies the processing protocol and achieves end-to-end eye gaze regression. The proposed method achieved superior performance in a variety of eye movement tasks than the co-registration-based method, and delivered objective results within a shorter time (~ 0.02 Seconds for each volume) than prior method (~0.3 Seconds for each volume).
Fast and High-Performance Learned Image Compression With Improved Checkerboard Context Model, Deformable Residual Module, and Knowledge Distillation
Sep 05, 2023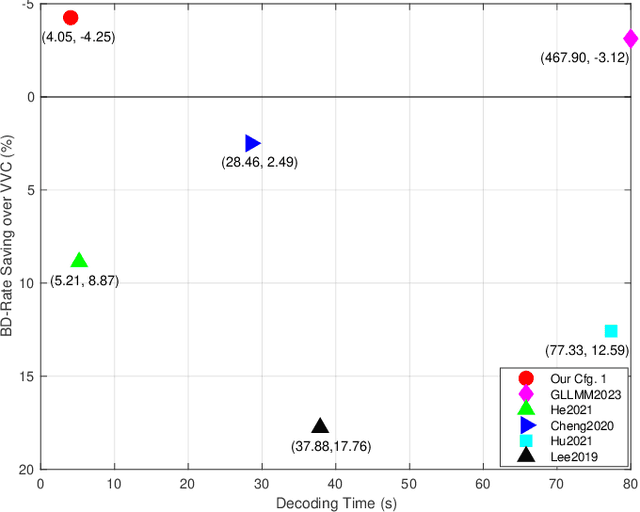
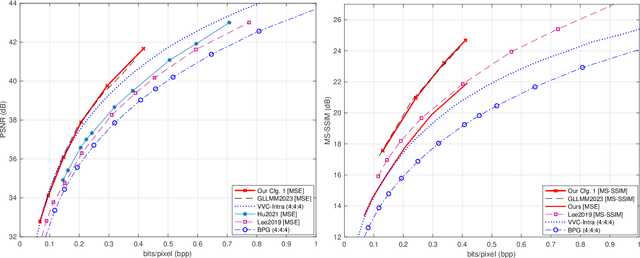
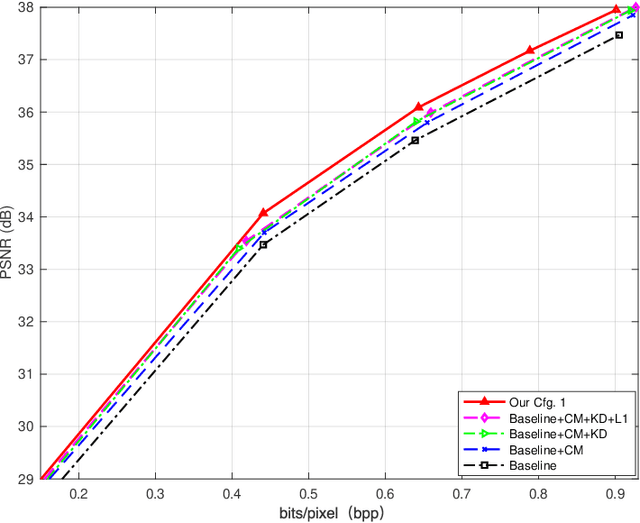
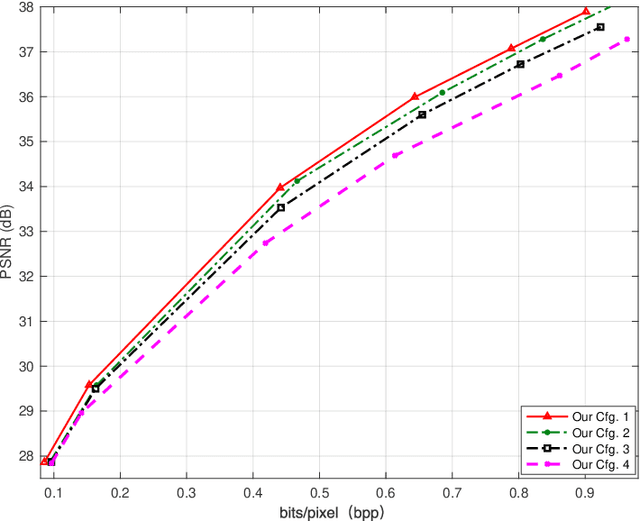
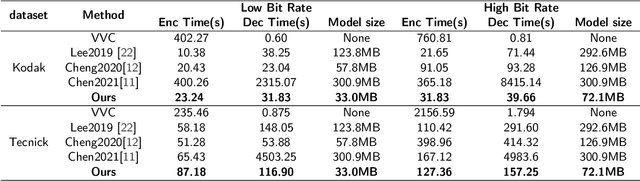
Deep learning-based image compression has made great progresses recently. However, many leading schemes use serial context-adaptive entropy model to improve the rate-distortion (R-D) performance, which is very slow. In addition, the complexities of the encoding and decoding networks are quite high and not suitable for many practical applications. In this paper, we introduce four techniques to balance the trade-off between the complexity and performance. We are the first to introduce deformable convolutional module in compression framework, which can remove more redundancies in the input image, thereby enhancing compression performance. Second, we design a checkerboard context model with two separate distribution parameter estimation networks and different probability models, which enables parallel decoding without sacrificing the performance compared to the sequential context-adaptive model. Third, we develop an improved three-step knowledge distillation and training scheme to achieve different trade-offs between the complexity and the performance of the decoder network, which transfers both the final and intermediate results of the teacher network to the student network to help its training. Fourth, we introduce $L_{1}$ regularization to make the numerical values of the latent representation more sparse. Then we only encode non-zero channels in the encoding and decoding process, which can greatly reduce the encoding and decoding time. Experiments show that compared to the state-of-the-art learned image coding scheme, our method can be about 20 times faster in encoding and 70-90 times faster in decoding, and our R-D performance is also $2.3 \%$ higher. Our method outperforms the traditional approach in H.266/VVC-intra (4:4:4) and some leading learned schemes in terms of PSNR and MS-SSIM metrics when testing on Kodak and Tecnick-40 datasets.
Enhanced Residual SwinV2 Transformer for Learned Image Compression
Aug 23, 2023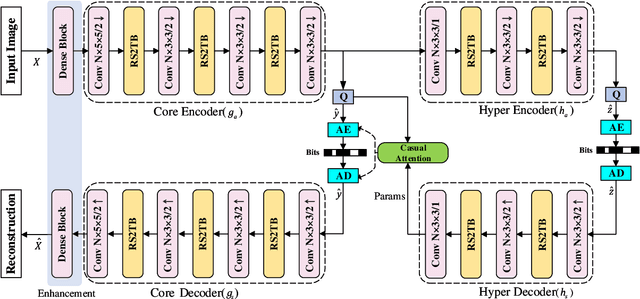
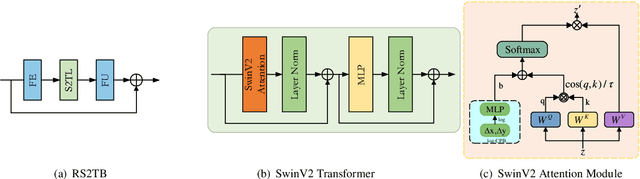

Recently, the deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. However, a challenge of many learning-based approaches is that they often achieve better performance via sacrificing complexity, which making practical deployment difficult. To alleviate this issue, in this paper, we propose an effective and efficient learned image compression framework based on an enhanced residual Swinv2 transformer. To enhance the nonlinear representation of images in our framework, we use a feature enhancement module that consists of three consecutive convolutional layers. In the subsequent coding and hyper coding steps, we utilize a SwinV2 transformer-based attention mechanism to process the input image. The SwinV2 model can help to reduce model complexity while maintaining high performance. Experimental results show that the proposed method achieves comparable performance compared to some recent learned image compression methods on Kodak and Tecnick datasets, and outperforms some traditional codecs including VVC. In particular, our method achieves comparable results while reducing model complexity by 56% compared to these recent methods.
ROI-based Deep Image Compression with Swin Transformers
May 12, 2023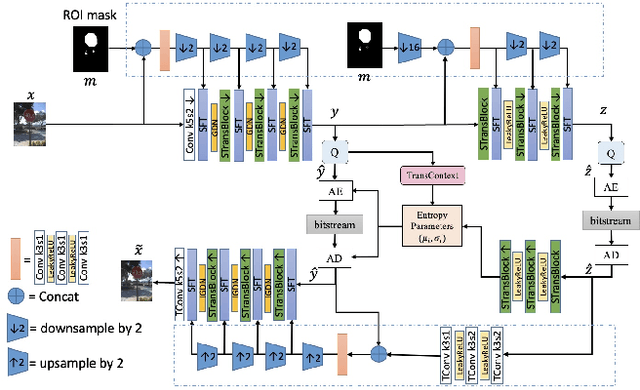

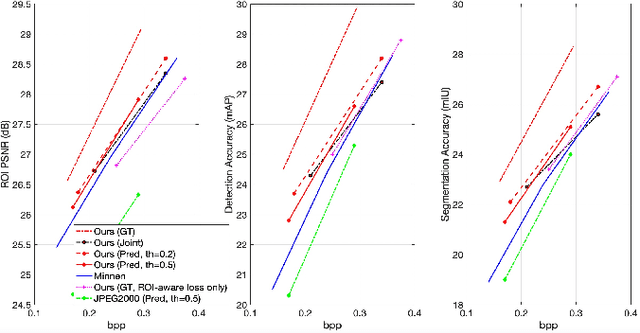

Encoding the Region Of Interest (ROI) with better quality than the background has many applications including video conferencing systems, video surveillance and object-oriented vision tasks. In this paper, we propose a ROI-based image compression framework with Swin transformers as main building blocks for the autoencoder network. The binary ROI mask is integrated into different layers of the network to provide spatial information guidance. Based on the ROI mask, we can control the relative importance of the ROI and non-ROI by modifying the corresponding Lagrange multiplier $ \lambda $ for different regions. Experimental results show our model achieves higher ROI PSNR than other methods and modest average PSNR for human evaluation. When tested on models pre-trained with original images, it has superior object detection and instance segmentation performance on the COCO validation dataset.
Human Guided Ground-truth Generation for Realistic Image Super-resolution
Mar 23, 2023
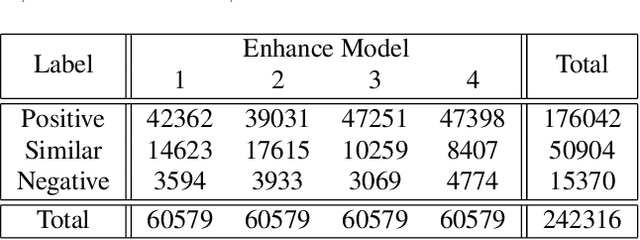
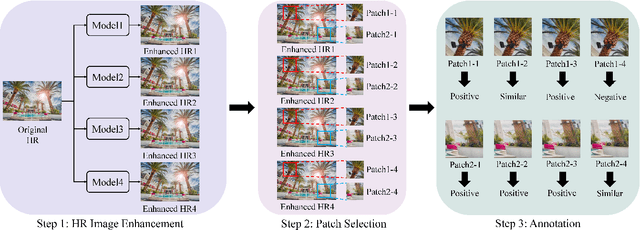
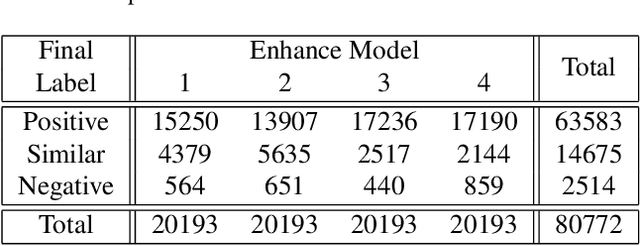
How to generate the ground-truth (GT) image is a critical issue for training realistic image super-resolution (Real-ISR) models. Existing methods mostly take a set of high-resolution (HR) images as GTs and apply various degradations to simulate their low-resolution (LR) counterparts. Though great progress has been achieved, such an LR-HR pair generation scheme has several limitations. First, the perceptual quality of HR images may not be high enough, limiting the quality of Real-ISR outputs. Second, existing schemes do not consider much human perception in GT generation, and the trained models tend to produce over-smoothed results or unpleasant artifacts. With the above considerations, we propose a human guided GT generation scheme. We first elaborately train multiple image enhancement models to improve the perceptual quality of HR images, and enable one LR image having multiple HR counterparts. Human subjects are then involved to annotate the high quality regions among the enhanced HR images as GTs, and label the regions with unpleasant artifacts as negative samples. A human guided GT image dataset with both positive and negative samples is then constructed, and a loss function is proposed to train the Real-ISR models. Experiments show that the Real-ISR models trained on our dataset can produce perceptually more realistic results with less artifacts. Dataset and codes can be found at https://github.com/ChrisDud0257/HGGT
Asymmetric Learned Image Compression with Multi-Scale Residual Block, Importance Map, and Post-Quantization Filtering
Jun 21, 2022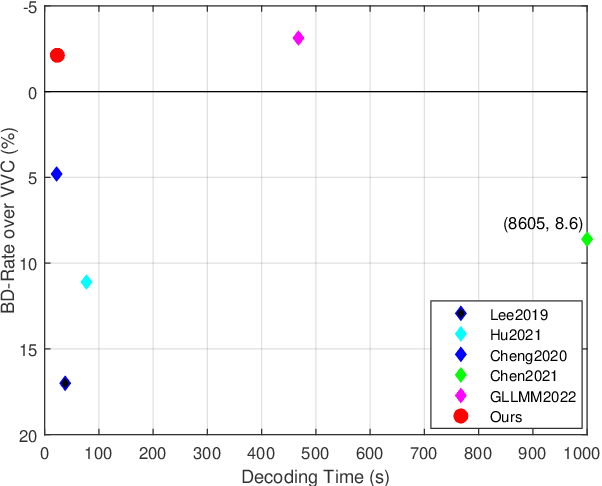
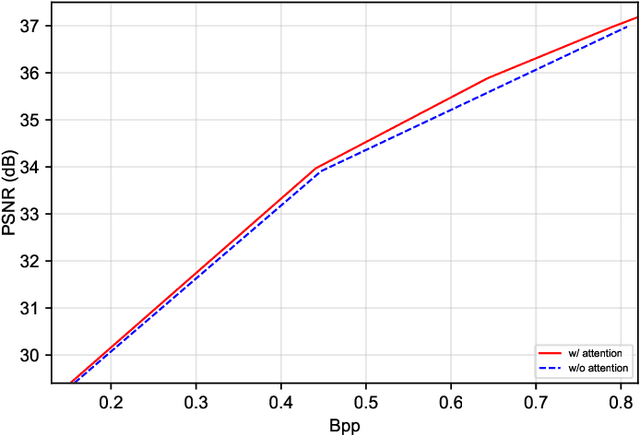


Recently, deep learning-based image compression has made signifcant progresses, and has achieved better ratedistortion (R-D) performance than the latest traditional method, H.266/VVC, in both subjective metric and the more challenging objective metric. However, a major problem is that many leading learned schemes cannot maintain a good trade-off between performance and complexity. In this paper, we propose an effcient and effective image coding framework, which achieves similar R-D performance with lower complexity than the state of the art. First, we develop an improved multi-scale residual block (MSRB) that can expand the receptive feld and is easier to obtain global information. It can further capture and reduce the spatial correlation of the latent representations. Second, a more advanced importance map network is introduced to adaptively allocate bits to different regions of the image. Third, we apply a 2D post-quantization flter (PQF) to reduce the quantization error, motivated by the Sample Adaptive Offset (SAO) flter in video coding. Moreover, We fnd that the complexity of encoder and decoder have different effects on image compression performance. Based on this observation, we design an asymmetric paradigm, in which the encoder employs three stages of MSRBs to improve the learning capacity, whereas the decoder only needs one stage of MSRB to yield satisfactory reconstruction, thereby reducing the decoding complexity without sacrifcing performance. Experimental results show that compared to the state-of-the-art method, the encoding and decoding time of the proposed method are about 17 times faster, and the R-D performance is only reduced by less than 1% on both Kodak and Tecnick datasets, which is still better than H.266/VVC(4:4:4) and other recent learning-based methods. Our source code is publicly available at https://github.com/fengyurenpingsheng.