 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Ma
General Purpose Verification for Chain of Thought Prompting
Apr 30, 2024
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Apr 18, 2024Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, \textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (\textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.68\% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
Few-Shot Data-to-Text Generation via Unified Representation and Multi-Source Learning
Aug 10, 2023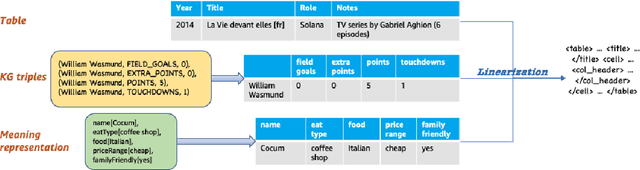

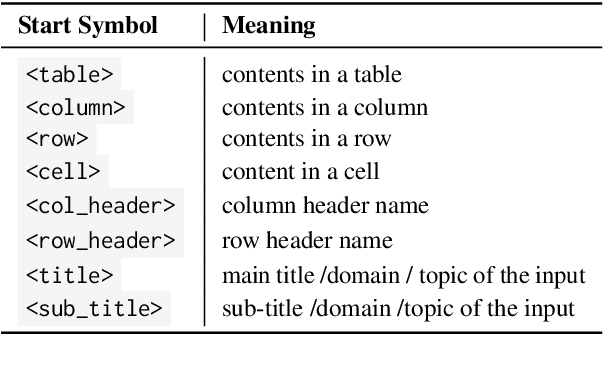
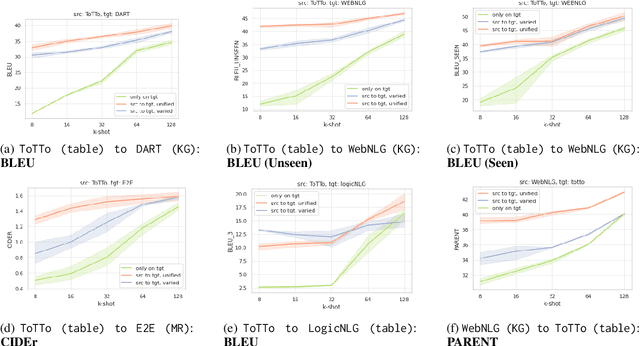
We present a novel approach for structured data-to-text generation that addresses the limitations of existing methods that primarily focus on specific types of structured data. Our proposed method aims to improve performance in multi-task training, zero-shot and few-shot scenarios by providing a unified representation that can handle various forms of structured data such as tables, knowledge graph triples, and meaning representations. We demonstrate that our proposed approach can effectively adapt to new structured forms, and can improve performance in comparison to current methods. For example, our method resulted in a 66% improvement in zero-shot BLEU scores when transferring models trained on table inputs to a knowledge graph dataset. Our proposed method is an important step towards a more general data-to-text generation framework.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023
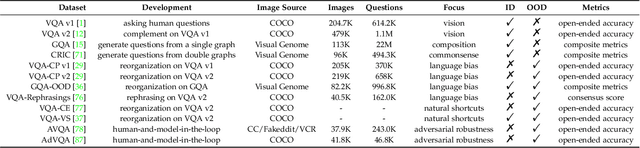
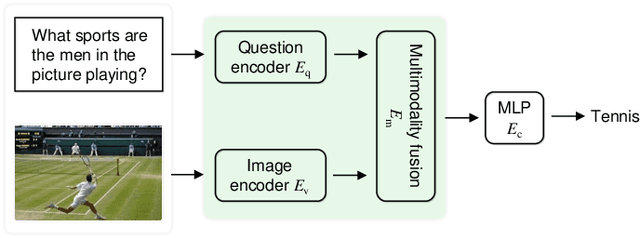
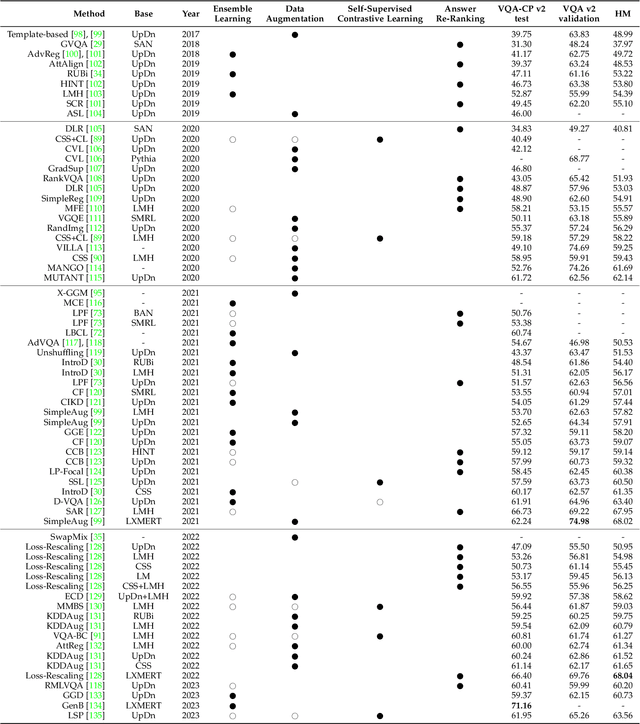
Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.
Benchmarking Diverse-Modal Entity Linking with Generative Models
May 27, 2023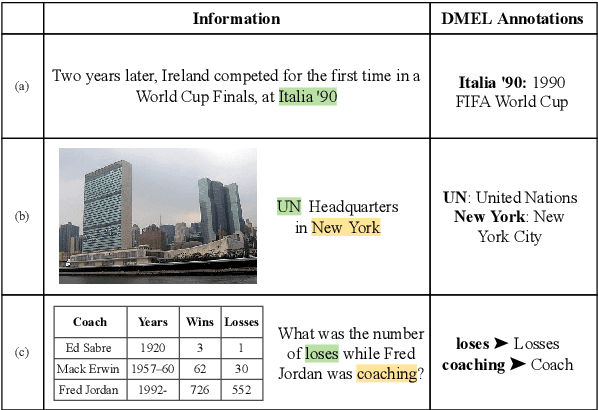
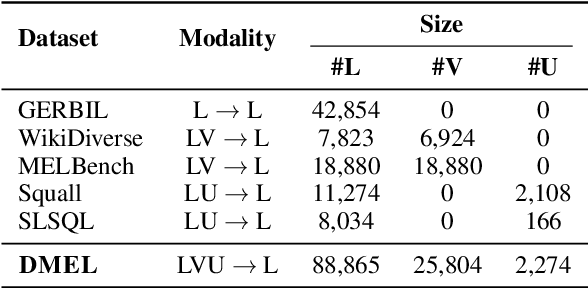
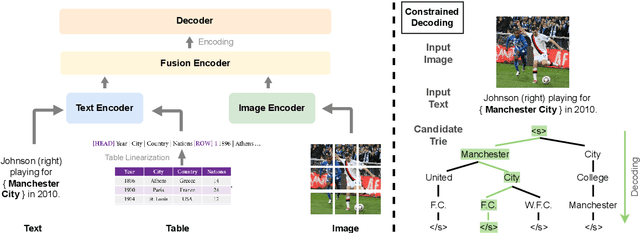
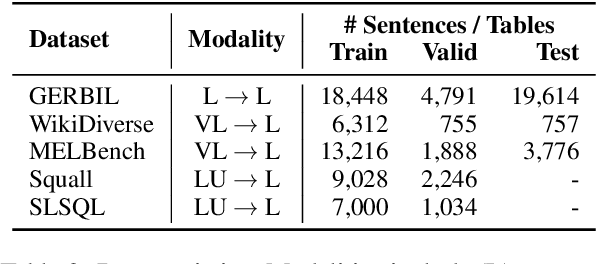
Entities can be expressed in diverse formats, such as texts, images, or column names and cell values in tables. While existing entity linking (EL) models work well on per modality configuration, such as text-only EL, visual grounding, or schema linking, it is more challenging to design a unified model for diverse modality configurations. To bring various modality configurations together, we constructed a benchmark for diverse-modal EL (DMEL) from existing EL datasets, covering all three modalities including text, image, and table. To approach the DMEL task, we proposed a generative diverse-modal model (GDMM) following a multimodal-encoder-decoder paradigm. Pre-training \Model with rich corpora builds a solid foundation for DMEL without storing the entire KB for inference. Fine-tuning GDMM builds a stronger DMEL baseline, outperforming state-of-the-art task-specific EL models by 8.51 F1 score on average. Additionally, extensive error analyses are conducted to highlight the challenges of DMEL, facilitating future research on this task.
Taxonomy Expansion for Named Entity Recognition
May 22, 2023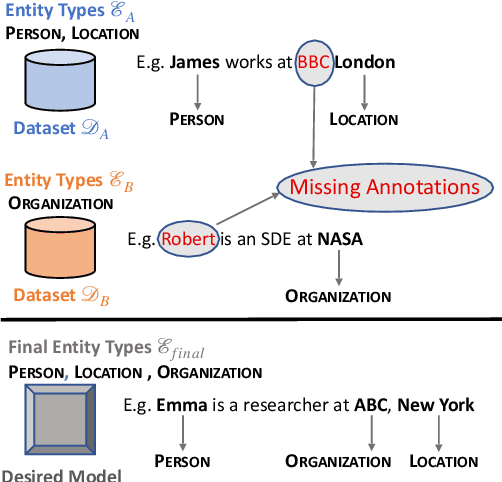
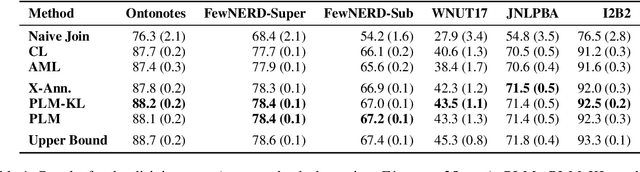
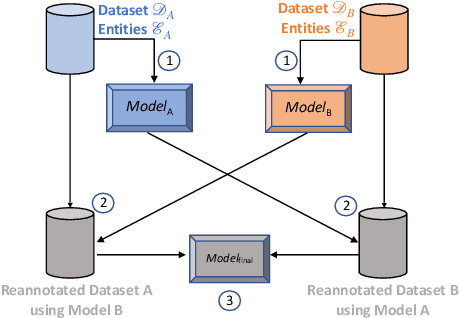
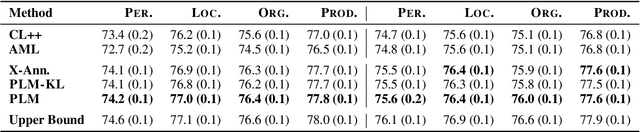
Training a Named Entity Recognition (NER) model often involves fixing a taxonomy of entity types. However, requirements evolve and we might need the NER model to recognize additional entity types. A simple approach is to re-annotate entire dataset with both existing and additional entity types and then train the model on the re-annotated dataset. However, this is an extremely laborious task. To remedy this, we propose a novel approach called Partial Label Model (PLM) that uses only partially annotated datasets. We experiment with 6 diverse datasets and show that PLM consistently performs better than most other approaches (0.5 - 2.5 F1), including in novel settings for taxonomy expansion not considered in prior work. The gap between PLM and all other approaches is especially large in settings where there is limited data available for the additional entity types (as much as 11 F1), thus suggesting a more cost effective approaches to taxonomy expansion.
Dual-Diffusion: Dual Conditional Denoising Diffusion Probabilistic Models for Blind Super-Resolution Reconstruction in RSIs
May 20, 2023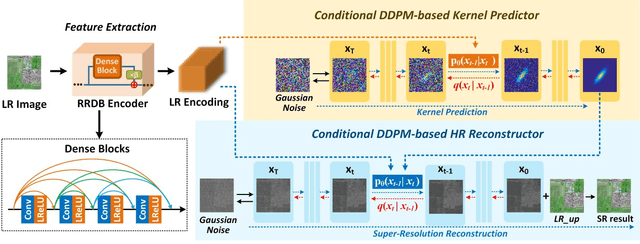


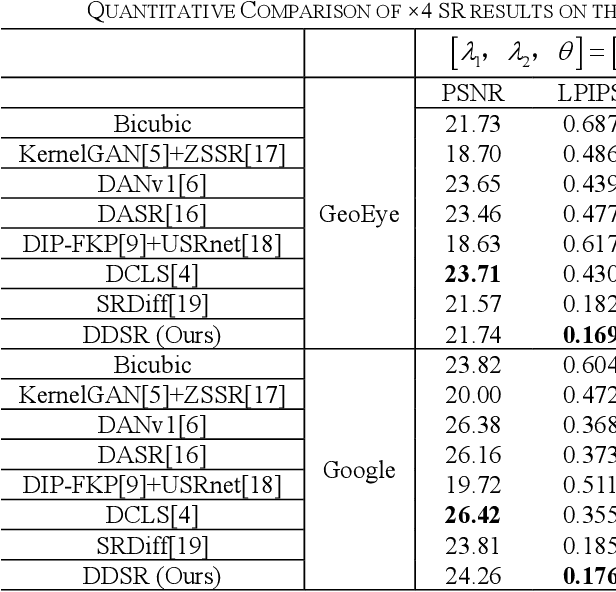
Previous super-resolution reconstruction (SR) works are always designed on the assumption that the degradation operation is fixed, such as bicubic downsampling. However, as for remote sensing images, some unexpected factors can cause the blurred visual performance, like weather factors, orbit altitude, etc. Blind SR methods are proposed to deal with various degradations. There are two main challenges of blind SR in RSIs: 1) the accu-rate estimation of degradation kernels; 2) the realistic image generation in the ill-posed problem. To rise to the challenge, we propose a novel blind SR framework based on dual conditional denoising diffusion probabilistic models (DDSR). In our work, we introduce conditional denoising diffusion probabilistic models (DDPM) from two aspects: kernel estimation progress and re-construction progress, named as the dual-diffusion. As for kernel estimation progress, conditioned on low-resolution (LR) images, a new DDPM-based kernel predictor is constructed by studying the invertible mapping between the kernel distribution and the latent distribution. As for reconstruction progress, regarding the predicted degradation kernels and LR images as conditional information, we construct a DDPM-based reconstructor to learning the mapping from the LR images to HR images. Com-prehensive experiments show the priority of our proposal com-pared with SOTA blind SR methods. Source Code is available at https://github.com/Lincoln20030413/DDSR
Comparing Biases and the Impact of Multilingual Training across Multiple Languages
May 18, 2023
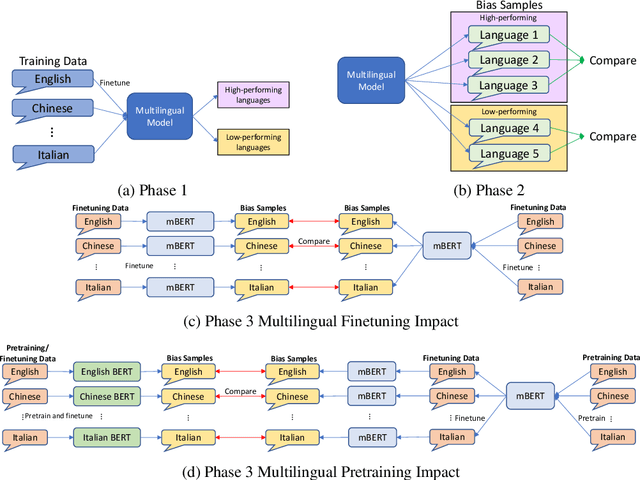
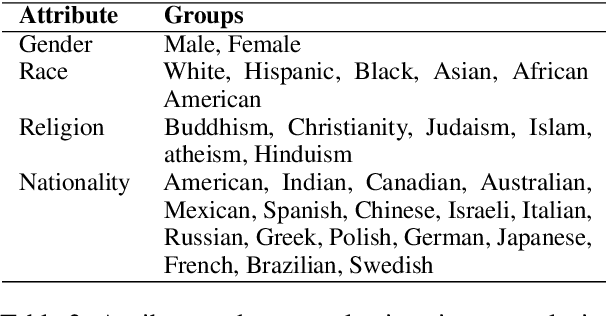

Studies in bias and fairness in natural language processing have primarily examined social biases within a single language and/or across few attributes (e.g. gender, race). However, biases can manifest differently across various languages for individual attributes. As a result, it is critical to examine biases within each language and attribute. Of equal importance is to study how these biases compare across languages and how the biases are affected when training a model on multilingual data versus monolingual data. We present a bias analysis across Italian, Chinese, English, Hebrew, and Spanish on the downstream sentiment analysis task to observe whether specific demographics are viewed more positively. We study bias similarities and differences across these languages and investigate the impact of multilingual vs. monolingual training data. We adapt existing sentiment bias templates in English to Italian, Chinese, Hebrew, and Spanish for four attributes: race, religion, nationality, and gender. Our results reveal similarities in bias expression such as favoritism of groups that are dominant in each language's culture (e.g. majority religions and nationalities). Additionally, we find an increased variation in predictions across protected groups, indicating bias amplification, after multilingual finetuning in comparison to multilingual pretraining.
Scribble-Supervised Target Extraction Method Based on Inner Structure-Constraint for Remote Sensing Images
May 18, 2023
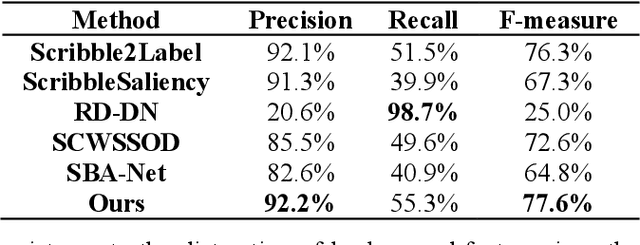
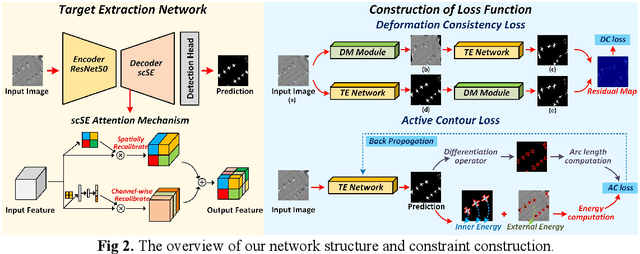
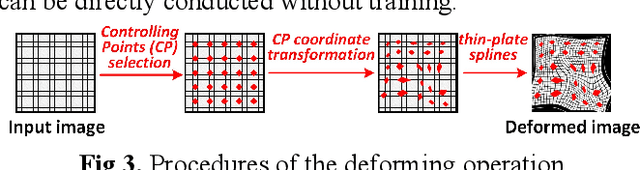
Weakly supervised learning based on scribble annotations in target extraction of remote sensing images has drawn much interest due to scribbles' flexibility in denoting winding objects and low cost of manually labeling. However, scribbles are too sparse to identify object structure and detailed information, bringing great challenges in target localization and boundary description. To alleviate these problems, in this paper, we construct two inner structure-constraints, a deformation consistency loss and a trainable active contour loss, together with a scribble-constraint to supervise the optimization of the encoder-decoder network without introducing any auxiliary module or extra operation based on prior cues. Comprehensive experiments demonstrate our method's superiority over five state-of-the-art algorithms in this field. Source code is available at https://github.com/yitongli123/ISC-TE.
Weakly-supervised ROI extraction method based on contrastive learning for remote sensing images
May 10, 2023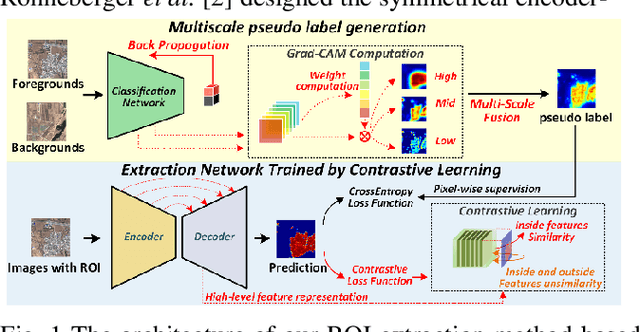

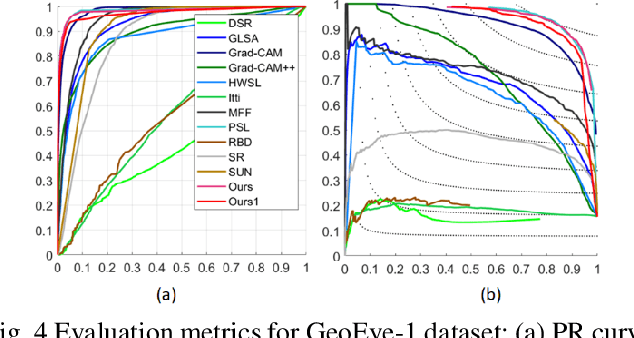

ROI extraction is an active but challenging task in remote sensing because of the complicated landform, the complex boundaries and the requirement of annotations. Weakly supervised learning (WSL) aims at learning a mapping from input image to pixel-wise prediction under image-wise labels, which can dramatically decrease the labor cost. However, due to the imprecision of labels, the accuracy and time consumption of WSL methods are relatively unsatisfactory. In this paper, we propose a two-step ROI extraction based on contractive learning. Firstly, we present to integrate multiscale Grad-CAM to obtain pseudo pixelwise annotations with well boundaries. Then, to reduce the compact of misjudgments in pseudo annotations, we construct a contrastive learning strategy to encourage the features inside ROI as close as possible and separate background features from foreground features. Comprehensive experiments demonstrate the superiority of our proposal. Code is available at https://github.com/HE-Lingfeng/ROI-Extraction