 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJielei Zhang
Facial Attribute Transformers for Precise and Robust Makeup Transfer
Apr 07, 2021
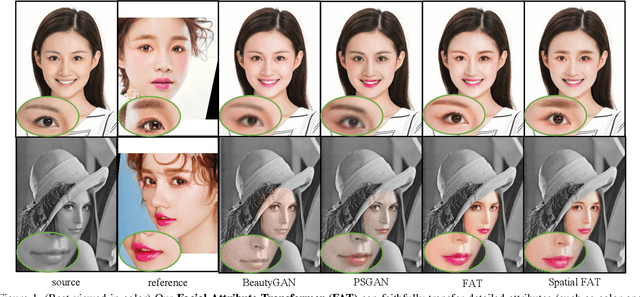

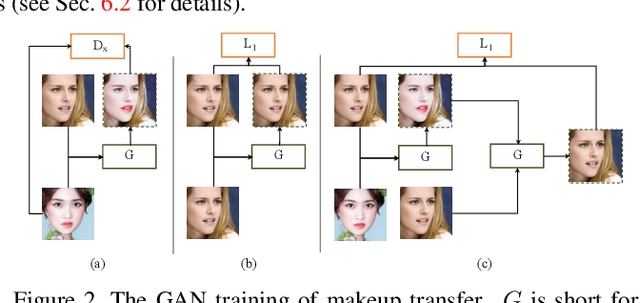
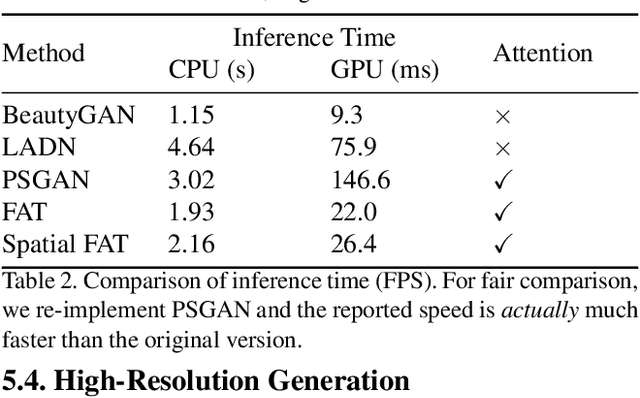
In this paper, we address the problem of makeup transfer, which aims at transplanting the makeup from the reference face to the source face while preserving the identity of the source. Existing makeup transfer methods have made notable progress in generating realistic makeup faces, but do not perform well in terms of color fidelity and spatial transformation. To tackle these issues, we propose a novel Facial Attribute Transformer (FAT) and its variant Spatial FAT for high-quality makeup transfer. Drawing inspirations from the Transformer in NLP, FAT is able to model the semantic correspondences and interactions between the source face and reference face, and then precisely estimate and transfer the facial attributes. To further facilitate shape deformation and transformation of facial parts, we also integrate thin plate splines (TPS) into FAT, thus creating Spatial FAT, which is the first method that can transfer geometric attributes in addition to color and texture. Extensive qualitative and quantitative experiments demonstrate the effectiveness and superiority of our proposed FATs in the following aspects: (1) ensuring high-fidelity color transfer; (2) allowing for geometric transformation of facial parts; (3) handling facial variations (such as poses and shadows) and (4) supporting high-resolution face generation.
On Vocabulary Reliance in Scene Text Recognition
May 08, 2020
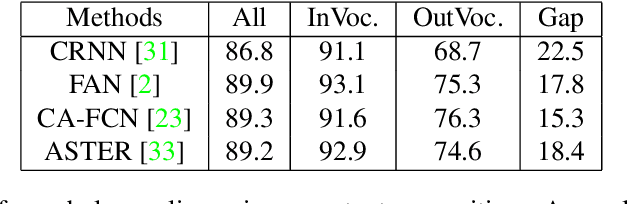
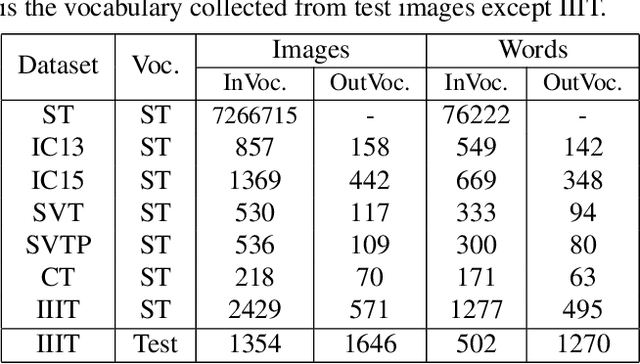

The pursuit of high performance on public benchmarks has been the driving force for research in scene text recognition, and notable progress has been achieved. However, a close investigation reveals a startling fact that the state-of-the-art methods perform well on images with words within vocabulary but generalize poorly to images with words outside vocabulary. We call this phenomenon "vocabulary reliance". In this paper, we establish an analytical framework to conduct an in-depth study on the problem of vocabulary reliance in scene text recognition. Key findings include: (1) Vocabulary reliance is ubiquitous, i.e., all existing algorithms more or less exhibit such characteristic; (2) Attention-based decoders prove weak in generalizing to words outside vocabulary and segmentation-based decoders perform well in utilizing visual features; (3) Context modeling is highly coupled with the prediction layers. These findings provide new insights and can benefit future research in scene text recognition. Furthermore, we propose a simple yet effective mutual learning strategy to allow models of two families (attention-based and segmentation-based) to learn collaboratively. This remedy alleviates the problem of vocabulary reliance and improves the overall scene text recognition performance.
* CVPR'20