 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJimin Huang
MetaAligner: Conditional Weak-to-Strong Correction for Generalizable Multi-Objective Alignment of Language Models
Mar 25, 2024

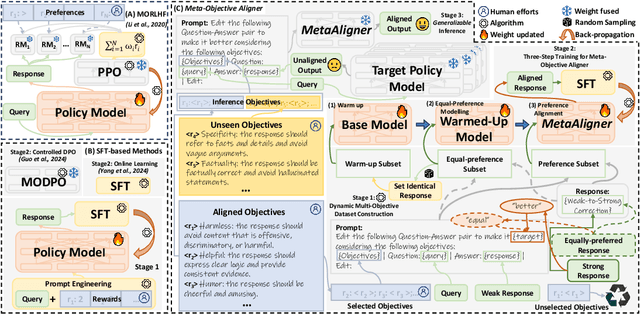
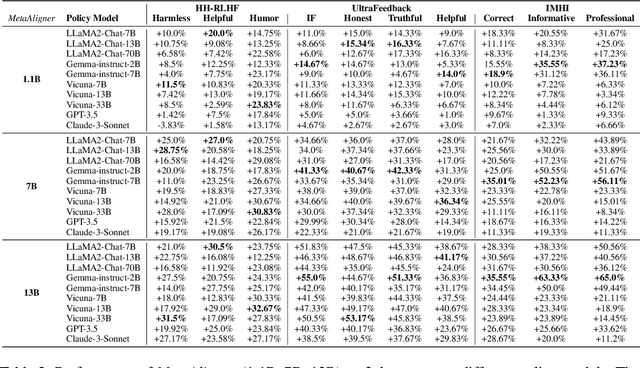

Recent advancements in large language models (LLMs) aim to tackle heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are parameter-adherent to the policy model, leading to two key limitations: (1) the high-cost repetition of their alignment algorithms for each new target model; (2) they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), a model that performs conditional weak-to-strong correction for weak responses to approach strong responses. MetaAligner is the first policy-agnostic and generalizable method for multi-objective preference alignment, which enables plug-and-play alignment by decoupling parameter updates from the policy models and facilitates zero-shot preference alignment for unseen objectives via in-context learning. Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 11 policy models with up to 63x more parameters, and outperforms previous alignment methods with down to 22.27x less computational resources. The model also accurately aligns with unseen objectives, marking the first step towards generalizable multi-objective preference alignment.
No Language is an Island: Unifying Chinese and English in Financial Large Language Models, Instruction Data, and Benchmarks
Mar 10, 2024
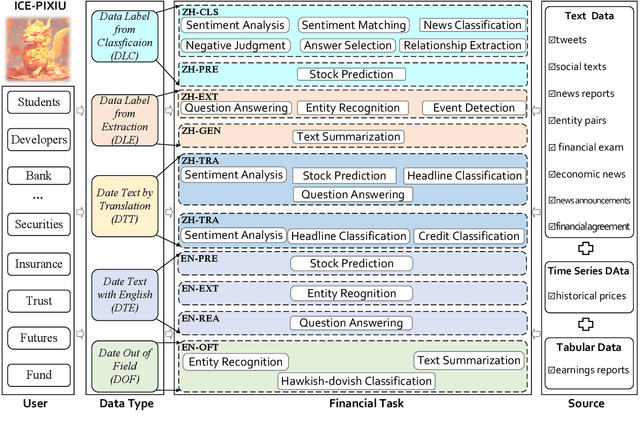

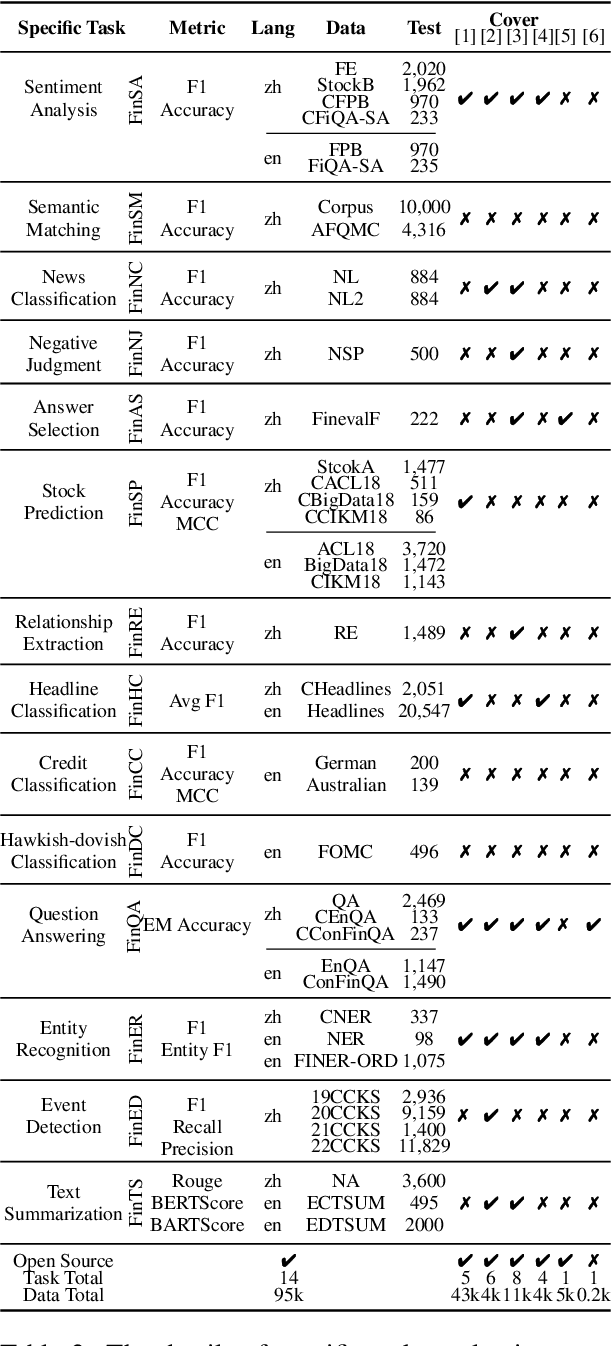
While the progression of Large Language Models (LLMs) has notably propelled financial analysis, their application has largely been confined to singular language realms, leaving untapped the potential of bilingual Chinese-English capacity. To bridge this chasm, we introduce ICE-PIXIU, seamlessly amalgamating the ICE-INTENT model and ICE-FLARE benchmark for bilingual financial analysis. ICE-PIXIU uniquely integrates a spectrum of Chinese tasks, alongside translated and original English datasets, enriching the breadth and depth of bilingual financial modeling. It provides unrestricted access to diverse model variants, a substantial compilation of diverse cross-lingual and multi-modal instruction data, and an evaluation benchmark with expert annotations, comprising 10 NLP tasks, 20 bilingual specific tasks, totaling 1,185k datasets. Our thorough evaluation emphasizes the advantages of incorporating these bilingual datasets, especially in translation tasks and utilizing original English data, enhancing both linguistic flexibility and analytical acuity in financial contexts. Notably, ICE-INTENT distinguishes itself by showcasing significant enhancements over conventional LLMs and existing financial LLMs in bilingual milieus, underscoring the profound impact of robust bilingual data on the accuracy and efficacy of financial NLP.
HealMe: Harnessing Cognitive Reframing in Large Language Models for Psychotherapy
Feb 26, 2024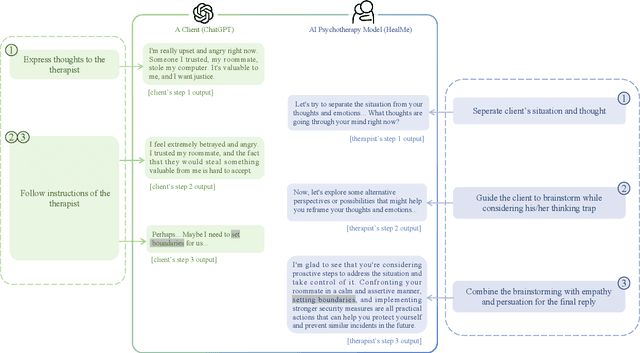
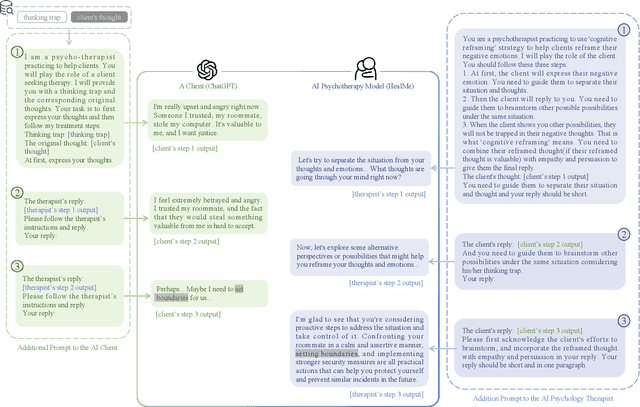

Large Language Models (LLMs) can play a vital role in psychotherapy by adeptly handling the crucial task of cognitive reframing and overcoming challenges such as shame, distrust, therapist skill variability, and resource scarcity. Previous LLMs in cognitive reframing mainly converted negative emotions to positive ones, but these approaches have limited efficacy, often not promoting clients' self-discovery of alternative perspectives. In this paper, we unveil the Helping and Empowering through Adaptive Language in Mental Enhancement (HealMe) model. This novel cognitive reframing therapy method effectively addresses deep-rooted negative thoughts and fosters rational, balanced perspectives. Diverging from traditional LLM methods, HealMe employs empathetic dialogue based on psychotherapeutic frameworks. It systematically guides clients through distinguishing circumstances from feelings, brainstorming alternative viewpoints, and developing empathetic, actionable suggestions. Moreover, we adopt the first comprehensive and expertly crafted psychological evaluation metrics, specifically designed to rigorously assess the performance of cognitive reframing, in both AI-simulated dialogues and real-world therapeutic conversations. Experimental results show that our model outperforms others in terms of empathy, guidance, and logical coherence, demonstrating its effectiveness and potential positive impact on psychotherapy.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Me LLaMA: Foundation Large Language Models for Medical Applications
Feb 20, 2024Recent large language models (LLMs) like ChatGPT and LLaMA have shown great promise in many AI applications. However, their performance on medical tasks is suboptimal and can be further improved by training on large domain-specific datasets. This study introduces Me LLaMA, a medical LLM family including foundation models - Me LLaMA 13/70B and their chat-enhanced versions - Me LLaMA 13/70B-chat, developed through the continual pre-training and instruction tuning of LLaMA2 using large medical data. Our domain-specific data suite for training and evaluation, includes a large-scale continual pre-training dataset with 129B tokens, an instruction tuning dataset with 214k samples, and a medical evaluation benchmark (MIBE) across six tasks with 14 datasets. Our extensive evaluation using MIBE shows that Me LLaMA models surpass existing open-source medical LLMs in zero-shot and few-shot learning and outperform commercial giants like ChatGPT on 6 out of 8 datasets and GPT-4 in 3 out of 8 datasets. In addition, we empirically investigated the catastrophic forgetting problem, and our results show that Me LLaMA models outperform other medical LLMs. Me LLaMA is one of the first and largest open-source foundational LLMs designed for the medical domain, using both biomedical and clinical data. It exhibits superior performance across both general and medical tasks compared to other medical LLMs, rendering it an attractive choice for medical AI applications. All resources are available at: https://github.com/BIDS-Xu-Lab/Me-LLaMA.
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English
Feb 12, 2024Despite Spanish's pivotal role in the global finance industry, a pronounced gap exists in Spanish financial natural language processing (NLP) and application studies compared to English, especially in the era of large language models (LLMs). To bridge this gap, we unveil Tois\'on de Oro, the first bilingual framework that establishes instruction datasets, finetuned LLMs, and evaluation benchmark for financial LLMs in Spanish joint with English. We construct a rigorously curated bilingual instruction dataset including over 144K Spanish and English samples from 15 datasets covering 7 tasks. Harnessing this, we introduce FinMA-ES, an LLM designed for bilingual financial applications. We evaluate our model and existing LLMs using FLARE-ES, the first comprehensive bilingual evaluation benchmark with 21 datasets covering 9 tasks. The FLARE-ES benchmark results reveal a significant multilingual performance gap and bias in existing LLMs. FinMA-ES models surpass SOTA LLMs such as GPT-4 in Spanish financial tasks, due to strategic instruction tuning and leveraging data from diverse linguistic resources, highlighting the positive impact of cross-linguistic transfer. All our datasets, models, and benchmarks have been released.
LAiW: A Chinese Legal Large Language Models Benchmark (A Technical Report)
Oct 09, 2023With the emergence of numerous legal LLMs, there is currently a lack of a comprehensive benchmark for evaluating their legal abilities. In this paper, we propose the first Chinese Legal LLMs benchmark based on legal capabilities. Through the collaborative efforts of legal and artificial intelligence experts, we divide the legal capabilities of LLMs into three levels: basic legal NLP capability, basic legal application capability, and complex legal application capability. We have completed the first phase of evaluation, which mainly focuses on the capability of basic legal NLP. The evaluation results show that although some legal LLMs have better performance than their backbones, there is still a gap compared to ChatGPT. Our benchmark can be found at URL.
Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models
Oct 08, 2023Temporal reasoning is a crucial NLP task, providing a nuanced understanding of time-sensitive contexts within textual data. Although recent advancements in LLMs have demonstrated their potential in temporal reasoning, the predominant focus has been on tasks such as temporal expression and temporal relation extraction. These tasks are primarily designed for the extraction of direct and past temporal cues and to engage in simple reasoning processes. A significant gap remains when considering complex reasoning tasks such as event forecasting, which requires multi-step temporal reasoning on events and prediction on the future timestamp. Another notable limitation of existing methods is their incapability to provide an illustration of their reasoning process, hindering explainability. In this paper, we introduce the first task of explainable temporal reasoning, to predict an event's occurrence at a future timestamp based on context which requires multiple reasoning over multiple events, and subsequently provide a clear explanation for their prediction. Our task offers a comprehensive evaluation of both the LLMs' complex temporal reasoning ability, the future event prediction ability, and explainability-a critical attribute for AI applications. To support this task, we present the first multi-source instruction-tuning dataset of explainable temporal reasoning (ExpTime) with 26k derived from the temporal knowledge graph datasets and their temporal reasoning paths, using a novel knowledge-graph-instructed-generation strategy. Based on the dataset, we propose the first open-source LLM series TimeLlaMA based on the foundation LlaMA2, with the ability of instruction following for explainable temporal reasoning. We compare the performance of our method and a variety of LLMs, where our method achieves the state-of-the-art performance of temporal prediction and explanation.
Empowering Many, Biasing a Few: Generalist Credit Scoring through Large Language Models
Oct 01, 2023Credit and risk assessments are cornerstones of the financial landscape, impacting both individual futures and broader societal constructs. Existing credit scoring models often exhibit limitations stemming from knowledge myopia and task isolation. In response, we formulate three hypotheses and undertake an extensive case study to investigate LLMs' viability in credit assessment. Our empirical investigations unveil LLMs' ability to overcome the limitations inherent in conventional models. We introduce a novel benchmark curated for credit assessment purposes, fine-tune a specialized Credit and Risk Assessment Large Language Model (CALM), and rigorously examine the biases that LLMs may harbor. Our findings underscore LLMs' potential in revolutionizing credit assessment, showcasing their adaptability across diverse financial evaluations, and emphasizing the critical importance of impartial decision-making in the financial sector. Our datasets, models, and benchmarks are open-sourced for other researchers.
PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance
Jun 08, 2023
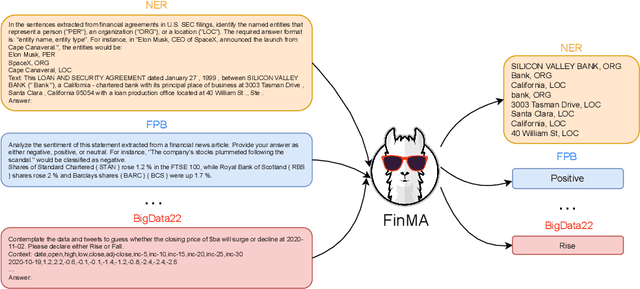


Although large language models (LLMs) has shown great performance on natural language processing (NLP) in the financial domain, there are no publicly available financial tailtored LLMs, instruction tuning datasets, and evaluation benchmarks, which is critical for continually pushing forward the open-source development of financial artificial intelligence (AI). This paper introduces PIXIU, a comprehensive framework including the first financial LLM based on fine-tuning LLaMA with instruction data, the first instruction data with 136K data samples to support the fine-tuning, and an evaluation benchmark with 5 tasks and 9 datasets. We first construct the large-scale multi-task instruction data considering a variety of financial tasks, financial document types, and financial data modalities. We then propose a financial LLM called FinMA by fine-tuning LLaMA with the constructed dataset to be able to follow instructions for various financial tasks. To support the evaluation of financial LLMs, we propose a standardized benchmark that covers a set of critical financial tasks, including five financial NLP tasks and one financial prediction task. With this benchmark, we conduct a detailed analysis of FinMA and several existing LLMs, uncovering their strengths and weaknesses in handling critical financial tasks. The model, datasets, benchmark, and experimental results are open-sourced to facilitate future research in financial AI.