 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingbo Zhang
Advances in 3D Generation: A Survey
Jan 31, 2024
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content generation is developing rapidly, enabling the creation of increasingly high-quality and diverse 3D models. The rapid growth of this field makes it difficult to stay abreast of all recent developments. In this survey, we aim to introduce the fundamental methodologies of 3D generation methods and establish a structured roadmap, encompassing 3D representation, generation methods, datasets, and corresponding applications. Specifically, we introduce the 3D representations that serve as the backbone for 3D generation. Furthermore, we provide a comprehensive overview of the rapidly growing literature on generation methods, categorized by the type of algorithmic paradigms, including feedforward generation, optimization-based generation, procedural generation, and generative novel view synthesis. Lastly, we discuss available datasets, applications, and open challenges. We hope this survey will help readers explore this exciting topic and foster further advancements in the field of 3D content generation.
HumanRef: Single Image to 3D Human Generation via Reference-Guided Diffusion
Nov 28, 2023Generating a 3D human model from a single reference image is challenging because it requires inferring textures and geometries in invisible views while maintaining consistency with the reference image. Previous methods utilizing 3D generative models are limited by the availability of 3D training data. Optimization-based methods that lift text-to-image diffusion models to 3D generation often fail to preserve the texture details of the reference image, resulting in inconsistent appearances in different views. In this paper, we propose HumanRef, a 3D human generation framework from a single-view input. To ensure the generated 3D model is photorealistic and consistent with the input image, HumanRef introduces a novel method called reference-guided score distillation sampling (Ref-SDS), which effectively incorporates image guidance into the generation process. Furthermore, we introduce region-aware attention to Ref-SDS, ensuring accurate correspondence between different body regions. Experimental results demonstrate that HumanRef outperforms state-of-the-art methods in generating 3D clothed humans with fine geometry, photorealistic textures, and view-consistent appearances.
VQ-NeRF: Neural Reflectance Decomposition and Editing with Vector Quantization
Nov 05, 2023



We propose VQ-NeRF, a two-branch neural network model that incorporates Vector Quantization (VQ) to decompose and edit reflectance fields in 3D scenes. Conventional neural reflectance fields use only continuous representations to model 3D scenes, despite the fact that objects are typically composed of discrete materials in reality. This lack of discretization can result in noisy material decomposition and complicated material editing. To address these limitations, our model consists of a continuous branch and a discrete branch. The continuous branch follows the conventional pipeline to predict decomposed materials, while the discrete branch uses the VQ mechanism to quantize continuous materials into individual ones. By discretizing the materials, our model can reduce noise in the decomposition process and generate a segmentation map of discrete materials. Specific materials can be easily selected for further editing by clicking on the corresponding area of the segmentation outcomes. Additionally, we propose a dropout-based VQ codeword ranking strategy to predict the number of materials in a scene, which reduces redundancy in the material segmentation process. To improve usability, we also develop an interactive interface to further assist material editing. We evaluate our model on both computer-generated and real-world scenes, demonstrating its superior performance. To the best of our knowledge, our model is the first to enable discrete material editing in 3D scenes.
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
May 19, 2023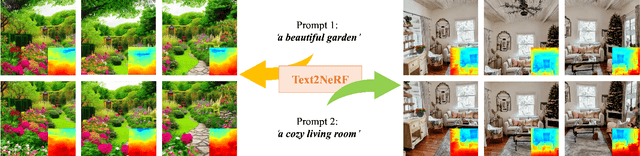

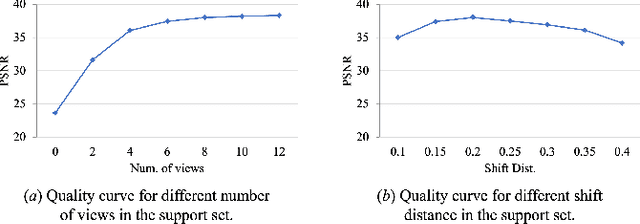

Text-driven 3D scene generation is widely applicable to video gaming, film industry, and metaverse applications that have a large demand for 3D scenes. However, existing text-to-3D generation methods are limited to producing 3D objects with simple geometries and dreamlike styles that lack realism. In this work, we present Text2NeRF, which is able to generate a wide range of 3D scenes with complicated geometric structures and high-fidelity textures purely from a text prompt. To this end, we adopt NeRF as the 3D representation and leverage a pre-trained text-to-image diffusion model to constrain the 3D reconstruction of the NeRF to reflect the scene description. Specifically, we employ the diffusion model to infer the text-related image as the content prior and use a monocular depth estimation method to offer the geometric prior. Both content and geometric priors are utilized to update the NeRF model. To guarantee textured and geometric consistency between different views, we introduce a progressive scene inpainting and updating strategy for novel view synthesis of the scene. Our method requires no additional training data but only a natural language description of the scene as the input. Extensive experiments demonstrate that our Text2NeRF outperforms existing methods in producing photo-realistic, multi-view consistent, and diverse 3D scenes from a variety of natural language prompts.
AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
Mar 30, 2023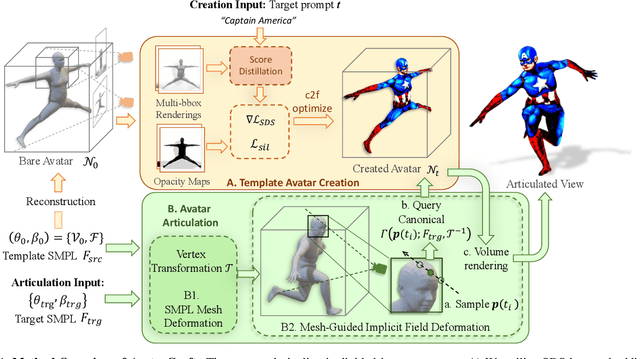
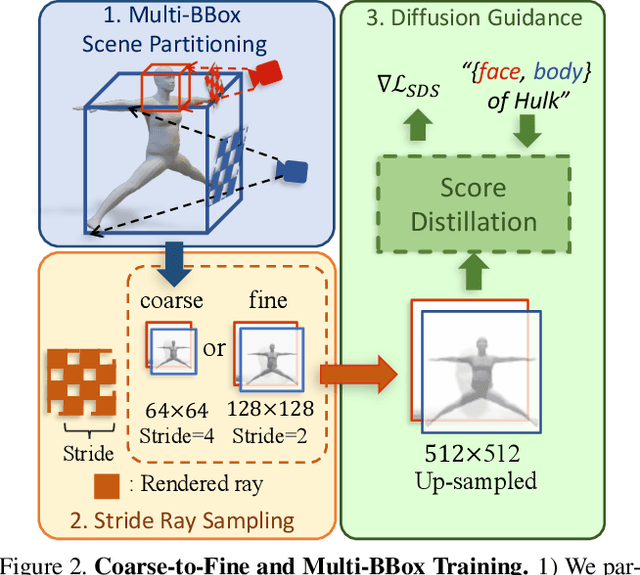
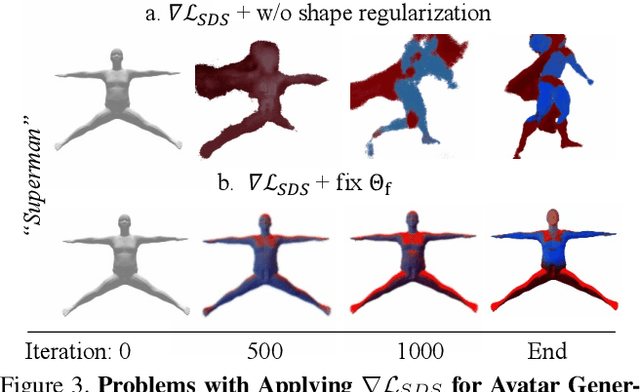

Neural implicit fields are powerful for representing 3D scenes and generating high-quality novel views, but it remains challenging to use such implicit representations for creating a 3D human avatar with a specific identity and artistic style that can be easily animated. Our proposed method, AvatarCraft, addresses this challenge by using diffusion models to guide the learning of geometry and texture for a neural avatar based on a single text prompt. We carefully design the optimization framework of neural implicit fields, including a coarse-to-fine multi-bounding box training strategy, shape regularization, and diffusion-based constraints, to produce high-quality geometry and texture. Additionally, we make the human avatar animatable by deforming the neural implicit field with an explicit warping field that maps the target human mesh to a template human mesh, both represented using parametric human models. This simplifies animation and reshaping of the generated avatar by controlling pose and shape parameters. Extensive experiments on various text descriptions show that AvatarCraft is effective and robust in creating human avatars and rendering novel views, poses, and shapes. Our project page is: \url{https://avatar-craft.github.io/}.
Adaptive Joint Optimization for 3D Reconstruction with Differentiable Rendering
Aug 15, 2022

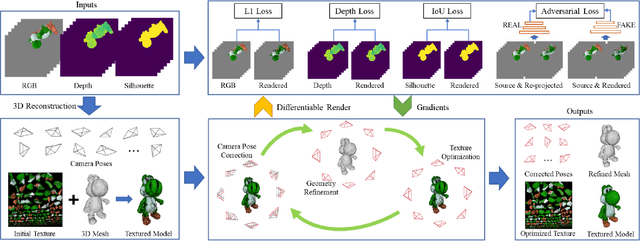
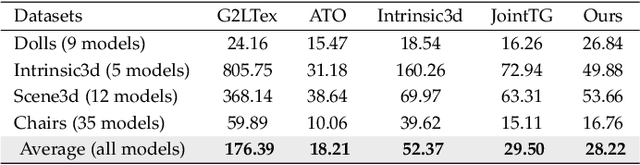
Due to inevitable noises introduced during scanning and quantization, 3D reconstruction via RGB-D sensors suffers from errors both in geometry and texture, leading to artifacts such as camera drifting, mesh distortion, texture ghosting, and blurriness. Given an imperfect reconstructed 3D model, most previous methods have focused on the refinement of either geometry, texture, or camera pose. Or different optimization schemes and objectives for optimizing each component have been used in previous joint optimization methods, forming a complicated system. In this paper, we propose a novel optimization approach based on differentiable rendering, which integrates the optimization of camera pose, geometry, and texture into a unified framework by enforcing consistency between the rendered results and the corresponding RGB-D inputs. Based on the unified framework, we introduce a joint optimization approach to fully exploit the inter-relationships between geometry, texture, and camera pose, and describe an adaptive interleaving strategy to improve optimization stability and efficiency. Using differentiable rendering, an image-level adversarial loss is applied to further improve the 3D model, making it more photorealistic. Experiments on synthetic and real data using quantitative and qualitative evaluation demonstrated the superiority of our approach in recovering both fine-scale geometry and high-fidelity texture.
FDNeRF: Few-shot Dynamic Neural Radiance Fields for Face Reconstruction and Expression Editing
Aug 11, 2022



We propose a Few-shot Dynamic Neural Radiance Field (FDNeRF), the first NeRF-based method capable of reconstruction and expression editing of 3D faces based on a small number of dynamic images. Unlike existing dynamic NeRFs that require dense images as input and can only be modeled for a single identity, our method enables face reconstruction across different persons with few-shot inputs. Compared to state-of-the-art few-shot NeRFs designed for modeling static scenes, the proposed FDNeRF accepts view-inconsistent dynamic inputs and supports arbitrary facial expression editing, i.e., producing faces with novel expressions beyond the input ones. To handle the inconsistencies between dynamic inputs, we introduce a well-designed conditional feature warping (CFW) module to perform expression conditioned warping in 2D feature space, which is also identity adaptive and 3D constrained. As a result, features of different expressions are transformed into the target ones. We then construct a radiance field based on these view-consistent features and use volumetric rendering to synthesize novel views of the modeled faces. Extensive experiments with quantitative and qualitative evaluation demonstrate that our method outperforms existing dynamic and few-shot NeRFs on both 3D face reconstruction and expression editing tasks. Our code and model will be available upon acceptance.
High-Fidelity Pluralistic Image Completion with Transformers
Mar 25, 2021



Image completion has made tremendous progress with convolutional neural networks (CNNs), because of their powerful texture modeling capacity. However, due to some inherent properties (e.g., local inductive prior, spatial-invariant kernels), CNNs do not perform well in understanding global structures or naturally support pluralistic completion. Recently, transformers demonstrate their power in modeling the long-term relationship and generating diverse results, but their computation complexity is quadratic to input length, thus hampering the application in processing high-resolution images. This paper brings the best of both worlds to pluralistic image completion: appearance prior reconstruction with transformer and texture replenishment with CNN. The former transformer recovers pluralistic coherent structures together with some coarse textures, while the latter CNN enhances the local texture details of coarse priors guided by the high-resolution masked images. The proposed method vastly outperforms state-of-the-art methods in terms of three aspects: 1) large performance boost on image fidelity even compared to deterministic completion methods; 2) better diversity and higher fidelity for pluralistic completion; 3) exceptional generalization ability on large masks and generic dataset, like ImageNet.
An influence-based fast preceding questionnaire model for elderly assessments
Nov 22, 2017



To improve the efficiency of elderly assessments, an influence-based fast preceding questionnaire model (FPQM) is proposed. Compared with traditional assessments, the FPQM optimizes questionnaires by reordering their attributes. The values of low-ranking attributes can be predicted by the values of the high-ranking attributes. Therefore, the number of attributes can be reduced without redesigning the questionnaires. A new function for calculating the influence of the attributes is proposed based on probability theory. Reordering and reducing algorithms are given based on the attributes' influences. The model is verified through a practical application. The practice in an elderly-care company shows that the FPQM can reduce the number of attributes by 90.56% with a prediction accuracy of 98.39%. Compared with other methods, such as the Expert Knowledge, Rough Set and C4.5 methods, the FPQM achieves the best performance. In addition, the FPQM can also be applied to other questionnaires.