 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingjing Wang
1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction
Apr 16, 2024
In this report, we present the 1st place solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction. The challenge aims to evaluate approaches for novel view synthesis and surface reconstruction using only a few posed images of each object. We utilize Pixel-NeRF as the basic model, and apply depth supervision as well as coarse-to-fine positional encoding. The experiments demonstrate the effectiveness of our approach in improving sparse-view reconstruction quality. We ranked first in the final test with a PSNR of 25.44614.
ChatASU: Evoking LLM's Reflexion to Truly Understand Aspect Sentiment in Dialogues
Mar 12, 2024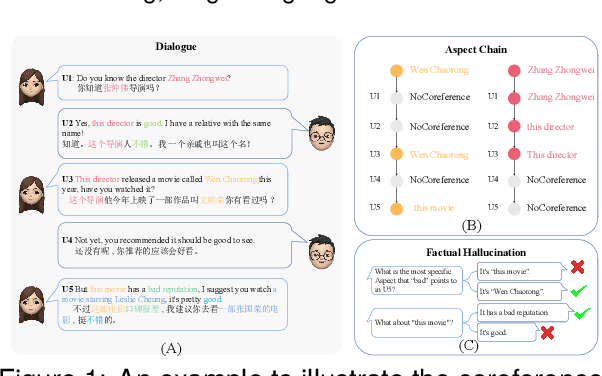
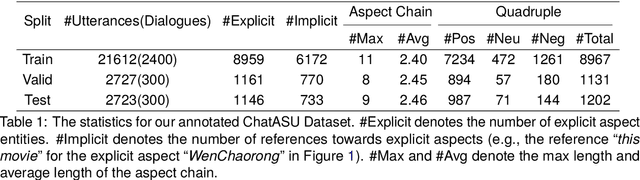
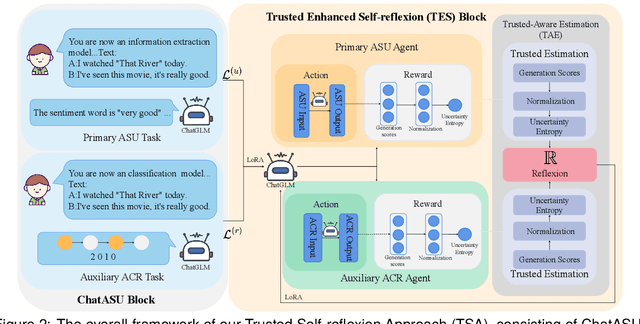
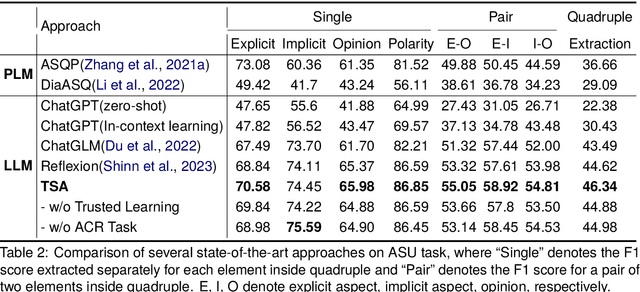
Aspect Sentiment Understanding (ASU) in interactive scenarios (e.g., Question-Answering and Dialogue) has attracted ever-more interest in recent years and achieved important progresses. However, existing studies on interactive ASU largely ignore the coreference issue for opinion targets (i.e., aspects), while this phenomenon is ubiquitous in interactive scenarios especially dialogues, limiting the ASU performance. Recently, large language models (LLMs) shows the powerful ability to integrate various NLP tasks with the chat paradigm. In this way, this paper proposes a new Chat-based Aspect Sentiment Understanding (ChatASU) task, aiming to explore LLMs' ability in understanding aspect sentiments in dialogue scenarios. Particularly, this ChatASU task introduces a sub-task, i.e., Aspect Chain Reasoning (ACR) task, to address the aspect coreference issue. On this basis, we propose a Trusted Self-reflexion Approach (TSA) with ChatGLM as backbone to ChatASU. Specifically, this TSA treats the ACR task as an auxiliary task to boost the performance of the primary ASU task, and further integrates trusted learning into reflexion mechanisms to alleviate the LLMs-intrinsic factual hallucination problem in TSA. Furthermore, a high-quality ChatASU dataset is annotated to evaluate TSA, and extensive experiments show that our proposed TSA can significantly outperform several state-of-the-art baselines, justifying the effectiveness of TSA to ChatASU and the importance of considering the coreference and hallucination issues in ChatASU.
TopicDiff: A Topic-enriched Diffusion Approach for Multimodal Conversational Emotion Detection
Mar 11, 2024
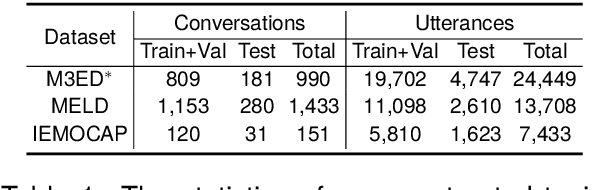
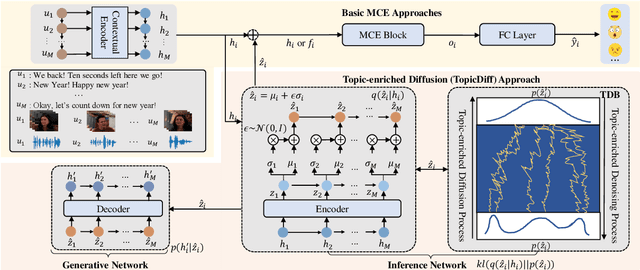
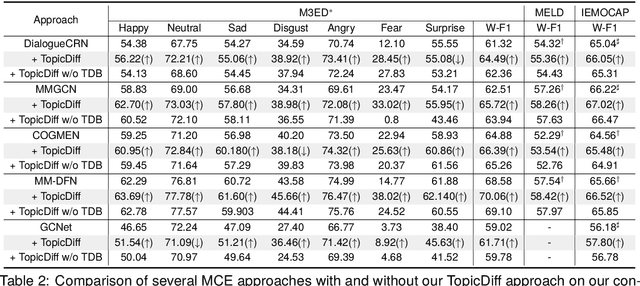
Multimodal Conversational Emotion (MCE) detection, generally spanning across the acoustic, vision and language modalities, has attracted increasing interest in the multimedia community. Previous studies predominantly focus on learning contextual information in conversations with only a few considering the topic information in single language modality, while always neglecting the acoustic and vision topic information. On this basis, we propose a model-agnostic Topic-enriched Diffusion (TopicDiff) approach for capturing multimodal topic information in MCE tasks. Particularly, we integrate the diffusion model into neural topic model to alleviate the diversity deficiency problem of neural topic model in capturing topic information. Detailed evaluations demonstrate the significant improvements of TopicDiff over the state-of-the-art MCE baselines, justifying the importance of multimodal topic information to MCE and the effectiveness of TopicDiff in capturing such information. Furthermore, we observe an interesting finding that the topic information in acoustic and vision is more discriminative and robust compared to the language.
Learning Expressive And Generalizable Motion Features For Face Forgery Detection
Mar 08, 2024
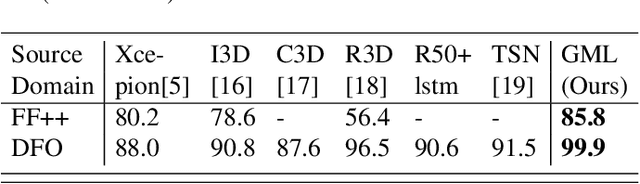
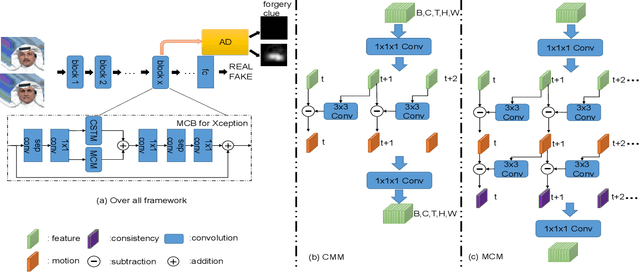

Previous face forgery detection methods mainly focus on appearance features, which may be easily attacked by sophisticated manipulation. Considering the majority of current face manipulation methods generate fake faces based on a single frame, which do not take frame consistency and coordination into consideration, artifacts on frame sequences are more effective for face forgery detection. However, current sequence-based face forgery detection methods use general video classification networks directly, which discard the special and discriminative motion information for face manipulation detection. To this end, we propose an effective sequence-based forgery detection framework based on an existing video classification method. To make the motion features more expressive for manipulation detection, we propose an alternative motion consistency block instead of the original motion features module. To make the learned features more generalizable, we propose an auxiliary anomaly detection block. With these two specially designed improvements, we make a general video classification network achieve promising results on three popular face forgery datasets.
Arbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024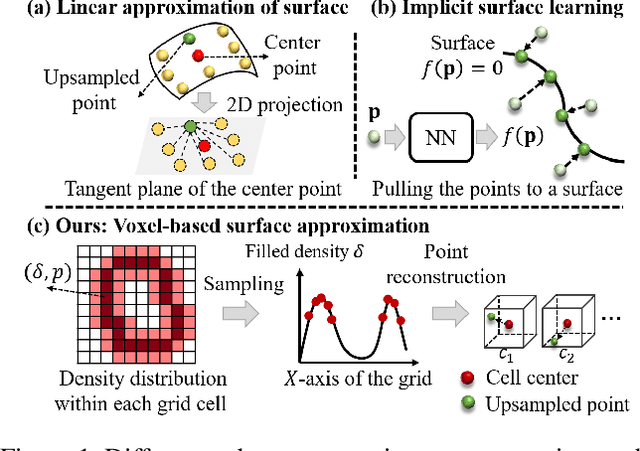
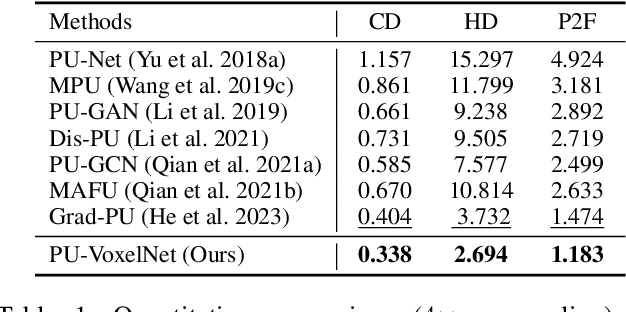
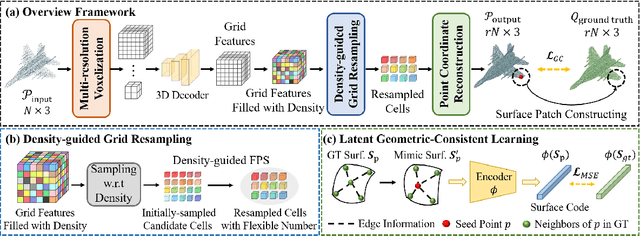
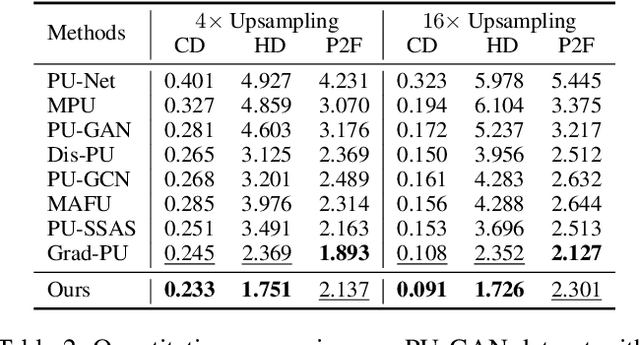
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
CLIP-Gaze: Towards General Gaze Estimation via Visual-Linguistic Model
Mar 08, 2024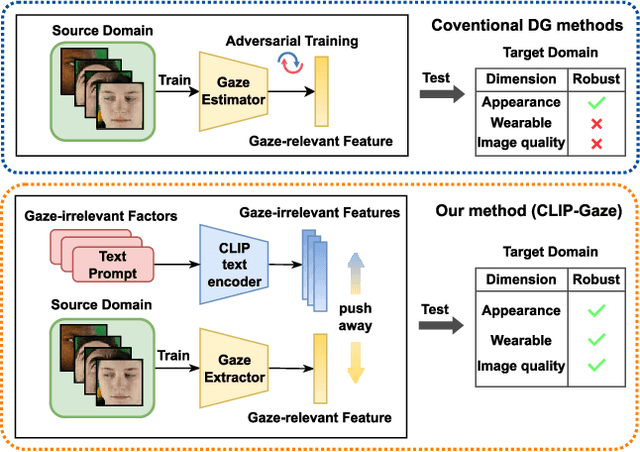
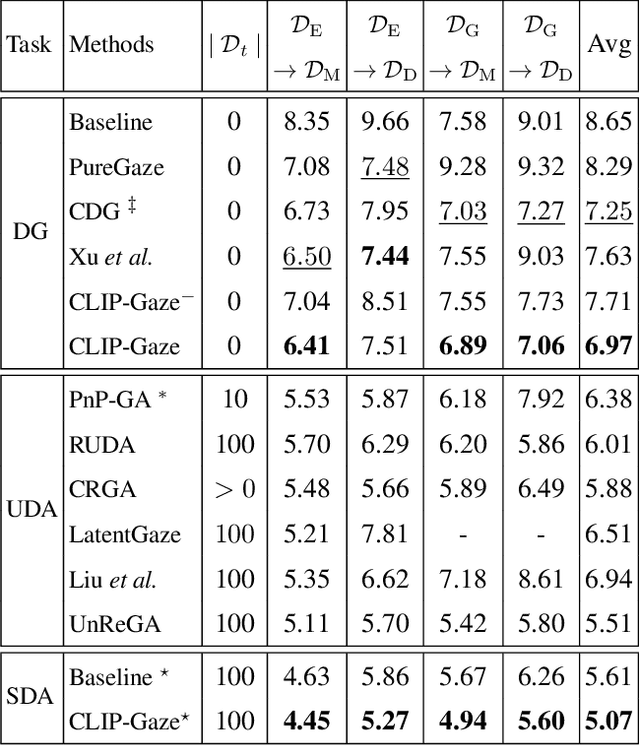
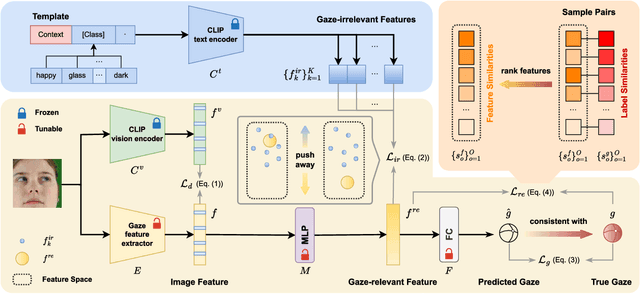
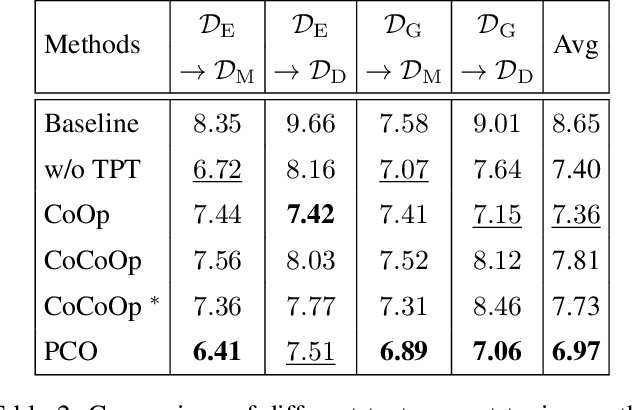
Gaze estimation methods often experience significant performance degradation when evaluated across different domains, due to the domain gap between the testing and training data. Existing methods try to address this issue using various domain generalization approaches, but with little success because of the limited diversity of gaze datasets, such as appearance, wearable, and image quality. To overcome these limitations, we propose a novel framework called CLIP-Gaze that utilizes a pre-trained vision-language model to leverage its transferable knowledge. Our framework is the first to leverage the vision-and-language cross-modality approach for gaze estimation task. Specifically, we extract gaze-relevant feature by pushing it away from gaze-irrelevant features which can be flexibly constructed via language descriptions. To learn more suitable prompts, we propose a personalized context optimization method for text prompt tuning. Furthermore, we utilize the relationship among gaze samples to refine the distribution of gaze-relevant features, thereby improving the generalization capability of the gaze estimation model. Extensive experiments demonstrate the excellent performance of CLIP-Gaze over existing methods on four cross-domain evaluations.
How to Understand "Support"? An Implicit-enhanced Causal Inference Approach for Weakly-supervised Phrase Grounding
Mar 04, 2024Weakly-supervised Phrase Grounding (WPG) is an emerging task of inferring the fine-grained phrase-region matching, while merely leveraging the coarse-grained sentence-image pairs for training. However, existing studies on WPG largely ignore the implicit phrase-region matching relations, which are crucial for evaluating the capability of models in understanding the deep multimodal semantics. To this end, this paper proposes an Implicit-Enhanced Causal Inference (IECI) approach to address the challenges of modeling the implicit relations and highlighting them beyond the explicit. Specifically, this approach leverages both the intervention and counterfactual techniques to tackle the above two challenges respectively. Furthermore, a high-quality implicit-enhanced dataset is annotated to evaluate IECI and detailed evaluations show the great advantages of IECI over the state-of-the-art baselines. Particularly, we observe an interesting finding that IECI outperforms the advanced multimodal LLMs by a large margin on this implicit-enhanced dataset, which may facilitate more research to evaluate the multimodal LLMs in this direction.
Is GPT Powerful Enough to Analyze the Emotions of Memes?
Nov 01, 2023Large Language Models (LLMs), representing a significant achievement in artificial intelligence (AI) research, have demonstrated their ability in a multitude of tasks. This project aims to explore the capabilities of GPT-3.5, a leading example of LLMs, in processing the sentiment analysis of Internet memes. Memes, which include both verbal and visual aspects, act as a powerful yet complex tool for expressing ideas and sentiments, demanding an understanding of societal norms and cultural contexts. Notably, the detection and moderation of hateful memes pose a significant challenge due to their implicit offensive nature. This project investigates GPT's proficiency in such subjective tasks, revealing its strengths and potential limitations. The tasks include the classification of meme sentiment, determination of humor type, and detection of implicit hate in memes. The performance evaluation, using datasets from SemEval-2020 Task 8 and Facebook hateful memes, offers a comparative understanding of GPT responses against human annotations. Despite GPT's remarkable progress, our findings underscore the challenges faced by these models in handling subjective tasks, which are rooted in their inherent limitations including contextual understanding, interpretation of implicit meanings, and data biases. This research contributes to the broader discourse on the applicability of AI in handling complex, context-dependent tasks, and offers valuable insights for future advancements.
Towards Scalable Wireless Federated Learning: Challenges and Solutions
Oct 08, 2023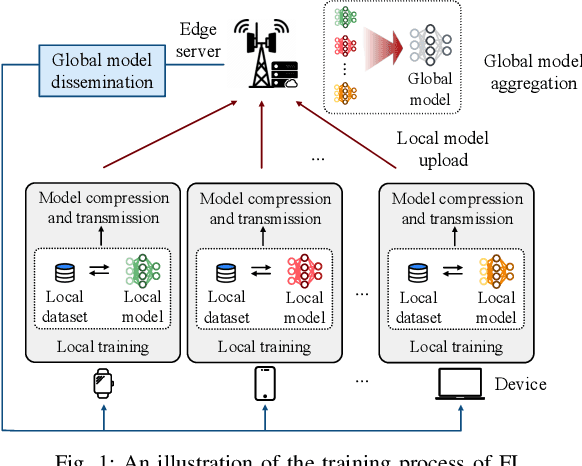
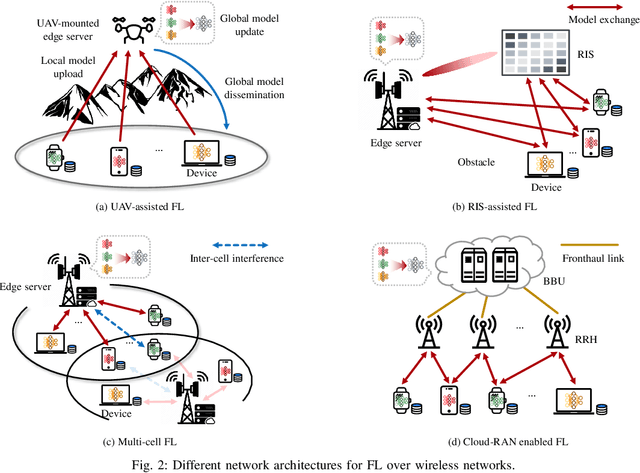
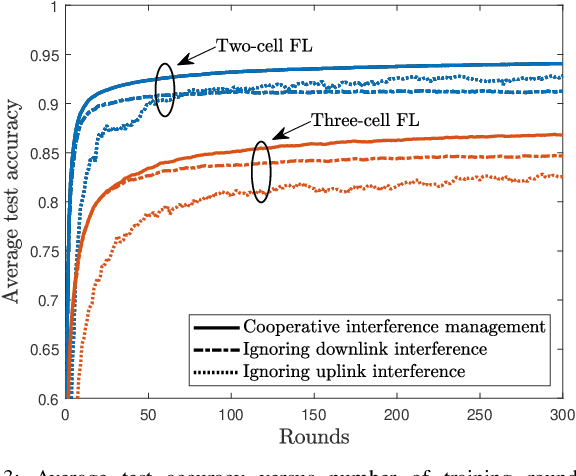

The explosive growth of smart devices (e.g., mobile phones, vehicles, drones) with sensing, communication, and computation capabilities gives rise to an unprecedented amount of data. The generated massive data together with the rapid advancement of machine learning (ML) techniques spark a variety of intelligent applications. To distill intelligence for supporting these applications, federated learning (FL) emerges as an effective distributed ML framework, given its potential to enable privacy-preserving model training at the network edge. In this article, we discuss the challenges and solutions of achieving scalable wireless FL from the perspectives of both network design and resource orchestration. For network design, we discuss how task-oriented model aggregation affects the performance of wireless FL, followed by proposing effective wireless techniques to enhance the communication scalability via reducing the model aggregation distortion and improving the device participation. For resource orchestration, we identify the limitations of the existing optimization-based algorithms and propose three task-oriented learning algorithms to enhance the algorithmic scalability via achieving computation-efficient resource allocation for wireless FL. We highlight several potential research issues that deserve further study.
Object Segmentation by Mining Cross-Modal Semantics
May 23, 2023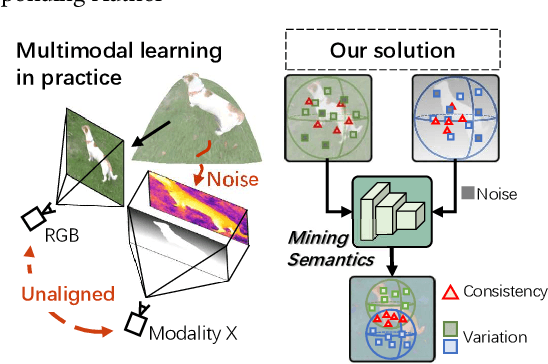
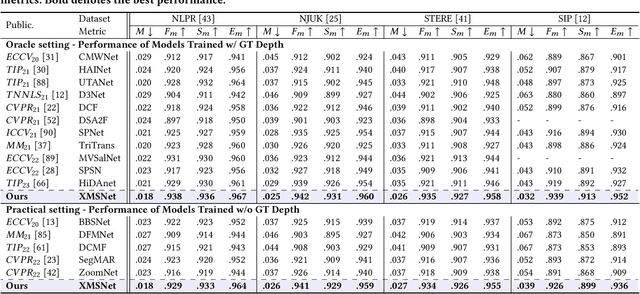
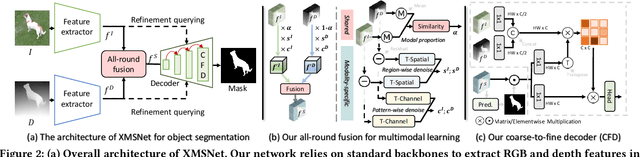
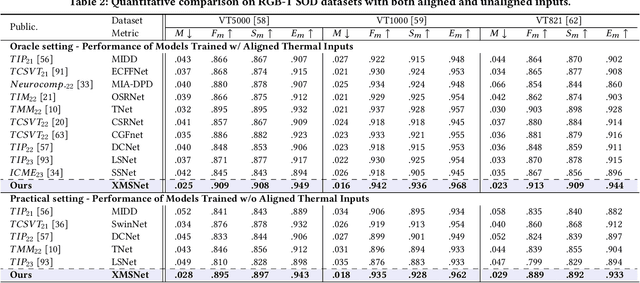
Multi-sensor clues have shown promise for object segmentation, but inherent noise in each sensor, as well as the calibration error in practice, may bias the segmentation accuracy. In this paper, we propose a novel approach by mining the Cross-Modal Semantics to guide the fusion and decoding of multimodal features, with the aim of controlling the modal contribution based on relative entropy. We explore semantics among the multimodal inputs in two aspects: the modality-shared consistency and the modality-specific variation. Specifically, we propose a novel network, termed XMSNet, consisting of (1) all-round attentive fusion (AF), (2) coarse-to-fine decoder (CFD), and (3) cross-layer self-supervision. On the one hand, the AF block explicitly dissociates the shared and specific representation and learns to weight the modal contribution by adjusting the proportion, region, and pattern, depending upon the quality. On the other hand, our CFD initially decodes the shared feature and then refines the output through specificity-aware querying. Further, we enforce semantic consistency across the decoding layers to enable interaction across network hierarchies, improving feature discriminability. Exhaustive comparison on eleven datasets with depth or thermal clues, and on two challenging tasks, namely salient and camouflage object segmentation, validate our effectiveness in terms of both performance and robustness.