 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinglong Gao
Towards Generalizable and Faithful Logic Reasoning over Natural Language via Resolution Refutation
Apr 03, 2024
Large language models (LLMs) have achieved significant performance in various natural language reasoning tasks. However, they still struggle with performing first-order logic reasoning over formal logical theories expressed in natural language. This is because the previous LLMs-based reasoning systems have the theoretical incompleteness issue. As a result, it can only address a limited set of simple reasoning problems, which significantly decreases their generalization ability. To address this issue, we propose a novel framework, named Generalizable and Faithful Reasoner (GFaiR), which introduces the paradigm of resolution refutation. Resolution refutation has the capability to solve all first-order logic reasoning problems by extending reasoning rules and employing the principle of proof by contradiction, so our system's completeness can be improved by introducing resolution refutation. Experimental results demonstrate that our system outperforms previous works by achieving state-of-the-art performances in complex scenarios while maintaining performances in simple scenarios. Besides, we observe that GFaiR is faithful to its reasoning process.
Is ChatGPT a Good Causal Reasoner? A Comprehensive Evaluation
May 18, 2023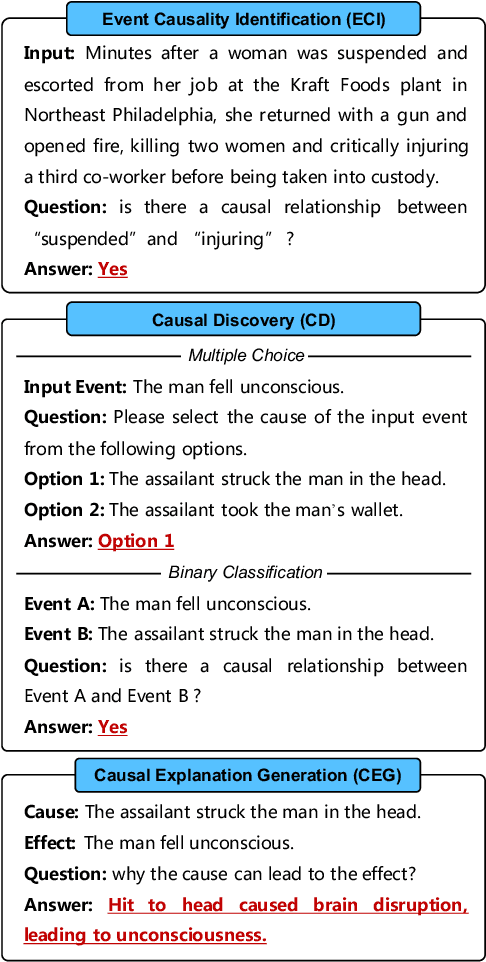
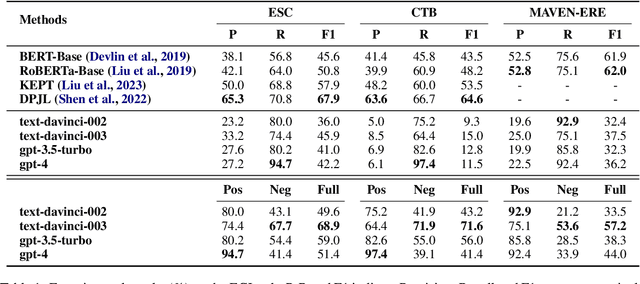
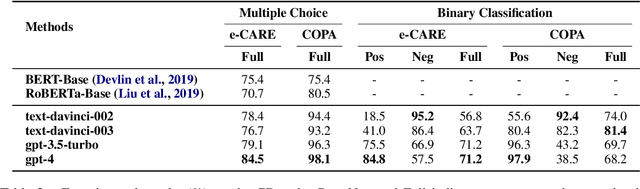
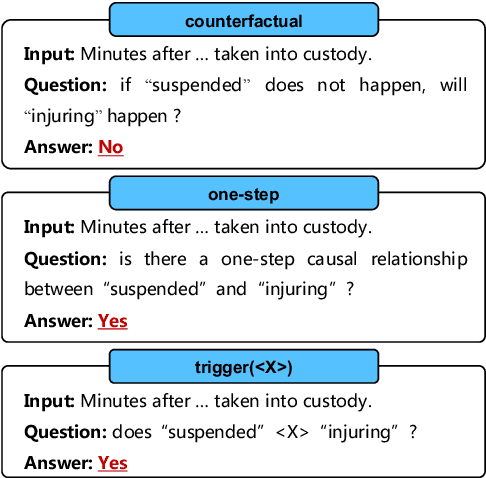
Causal reasoning ability is crucial for numerous NLP applications. Despite the impressive emerging ability of ChatGPT in various NLP tasks, it is unclear how well ChatGPT performs in causal reasoning. In this paper, we conduct the first comprehensive evaluation of the ChatGPT's causal reasoning capabilities. Experiments show that ChatGPT is not a good causal reasoner, but a good causal interpreter. Besides, ChatGPT has a serious hallucination on causal reasoning, possibly due to the reporting biases between causal and non-causal relationships in natural language, as well as ChatGPT's upgrading processes, such as RLHF. The In-Context Learning (ICL) and Chain-of-Though (COT) techniques can further exacerbate such causal hallucination. Additionally, the causal reasoning ability of ChatGPT is sensitive to the words used to express the causal concept in prompts, and close-ended prompts perform better than open-ended prompts. For events in sentences, ChatGPT excels at capturing explicit causality rather than implicit causality, and performs better in sentences with lower event density and smaller lexical distance between events.
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Aug 21, 2022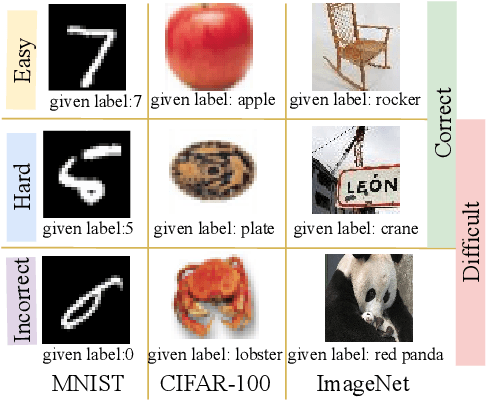
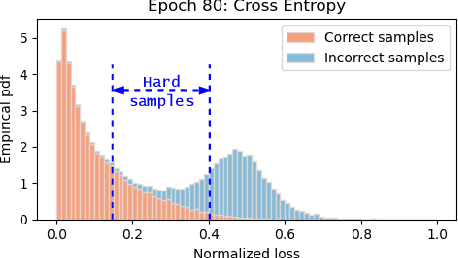
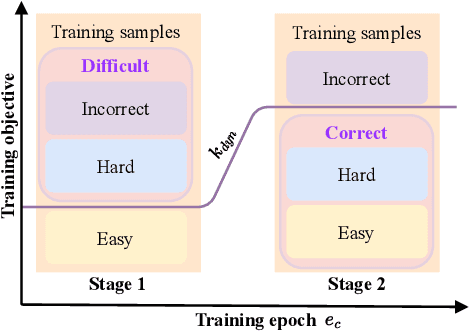
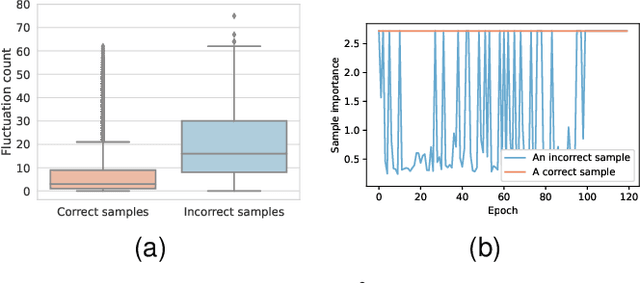
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.