 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinyuan Liu
Little Strokes Fell Great Oaks: Boosting the Hierarchical Features for Multi-exposure Image Fusion
Apr 10, 2024
In recent years, deep learning networks have made remarkable strides in the domain of multi-exposure image fusion. Nonetheless, prevailing approaches often involve directly feeding over-exposed and under-exposed images into the network, which leads to the under-utilization of inherent information present in the source images. Additionally, unsupervised techniques predominantly employ rudimentary weighted summation for color channel processing, culminating in an overall desaturated final image tone. To partially mitigate these issues, this study proposes a gamma correction module specifically designed to fully leverage latent information embedded within source images. Furthermore, a modified transformer block, embracing with self-attention mechanisms, is introduced to optimize the fusion process. Ultimately, a novel color enhancement algorithm is presented to augment image saturation while preserving intricate details. The source code is available at https://github.com/ZhiyingDu/BHFMEF.
Have You Merged My Model? On The Robustness of Large Language Model IP Protection Methods Against Model Merging
Apr 08, 2024Model merging is a promising lightweight model empowerment technique that does not rely on expensive computing devices (e.g., GPUs) or require the collection of specific training data. Instead, it involves editing different upstream model parameters to absorb their downstream task capabilities. However, uncertified model merging can infringe upon the Intellectual Property (IP) rights of the original upstream models. In this paper, we conduct the first study on the robustness of IP protection methods in model merging scenarios. We investigate two state-of-the-art IP protection techniques: Quantization Watermarking and Instructional Fingerprint, along with various advanced model merging technologies, such as Task Arithmetic, TIES-MERGING, and so on. Experimental results indicate that current Large Language Model (LLM) watermarking techniques cannot survive in the merged models, whereas model fingerprinting techniques can. Our research aims to highlight that model merging should be an indispensable consideration in the robustness assessment of model IP protection techniques, thereby promoting the healthy development of the open-source LLM community.
Towards Robust Image Stitching: An Adaptive Resistance Learning against Compatible Attacks
Feb 25, 2024Image stitching seamlessly integrates images captured from varying perspectives into a single wide field-of-view image. Such integration not only broadens the captured scene but also augments holistic perception in computer vision applications. Given a pair of captured images, subtle perturbations and distortions which go unnoticed by the human visual system tend to attack the correspondence matching, impairing the performance of image stitching algorithms. In light of this challenge, this paper presents the first attempt to improve the robustness of image stitching against adversarial attacks. Specifically, we introduce a stitching-oriented attack~(SoA), tailored to amplify the alignment loss within overlapping regions, thereby targeting the feature matching procedure. To establish an attack resistant model, we delve into the robustness of stitching architecture and develop an adaptive adversarial training~(AAT) to balance attack resistance with stitching precision. In this way, we relieve the gap between the routine adversarial training and benign models, ensuring resilience without quality compromise. Comprehensive evaluation across real-world and synthetic datasets validate the deterioration of SoA on stitching performance. Furthermore, AAT emerges as a more robust solution against adversarial perturbations, delivering superior stitching results. Code is available at:https://github.com/Jzy2017/TRIS.
From Text to Pixels: A Context-Aware Semantic Synergy Solution for Infrared and Visible Image Fusion
Dec 31, 2023With the rapid progression of deep learning technologies, multi-modality image fusion has become increasingly prevalent in object detection tasks. Despite its popularity, the inherent disparities in how different sources depict scene content make fusion a challenging problem. Current fusion methodologies identify shared characteristics between the two modalities and integrate them within this shared domain using either iterative optimization or deep learning architectures, which often neglect the intricate semantic relationships between modalities, resulting in a superficial understanding of inter-modal connections and, consequently, suboptimal fusion outcomes. To address this, we introduce a text-guided multi-modality image fusion method that leverages the high-level semantics from textual descriptions to integrate semantics from infrared and visible images. This method capitalizes on the complementary characteristics of diverse modalities, bolstering both the accuracy and robustness of object detection. The codebook is utilized to enhance a streamlined and concise depiction of the fused intra- and inter-domain dynamics, fine-tuned for optimal performance in detection tasks. We present a bilevel optimization strategy that establishes a nexus between the joint problem of fusion and detection, optimizing both processes concurrently. Furthermore, we introduce the first dataset of paired infrared and visible images accompanied by text prompts, paving the way for future research. Extensive experiments on several datasets demonstrate that our method not only produces visually superior fusion results but also achieves a higher detection mAP over existing methods, achieving state-of-the-art results.
Improving Cross-modal Alignment with Synthetic Pairs for Text-only Image Captioning
Dec 14, 2023Although image captioning models have made significant advancements in recent years, the majority of them heavily depend on high-quality datasets containing paired images and texts which are costly to acquire. Previous works leverage the CLIP's cross-modal association ability for image captioning, relying solely on textual information under unsupervised settings. However, not only does a modality gap exist between CLIP text and image features, but a discrepancy also arises between training and inference due to the unavailability of real-world images, which hinders the cross-modal alignment in text-only captioning. This paper proposes a novel method to address these issues by incorporating synthetic image-text pairs. A pre-trained text-to-image model is deployed to obtain images that correspond to textual data, and the pseudo features of generated images are optimized toward the real ones in the CLIP embedding space. Furthermore, textual information is gathered to represent image features, resulting in the image features with various semantics and the bridged modality gap. To unify training and inference, synthetic image features would serve as the training prefix for the language decoder, while real images are used for inference. Additionally, salient objects in images are detected as assistance to enhance the learning of modality alignment. Experimental results demonstrate that our method obtains the state-of-the-art performance on benchmark datasets.
FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts
Nov 09, 2023Large vision-language models (VLMs) like GPT-4V represent an unprecedented revolution in the field of artificial intelligence (AI). Compared to single-modal large language models (LLMs), VLMs possess more versatile capabilities by incorporating additional modalities (e.g., images). Meanwhile, there's a rising enthusiasm in the AI community to develop open-source VLMs, such as LLaVA and MiniGPT4, which, however, have not undergone rigorous safety assessment. In this paper, to demonstrate that more modalities lead to unforeseen AI safety issues, we propose FigStep, a novel jailbreaking framework against VLMs. FigStep feeds harmful instructions into VLMs through the image channel and then uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. Our experimental results show that FigStep can achieve an average attack success rate of 94.8% across 2 families of popular open-source VLMs, LLaVA and MiniGPT4 (a total of 5 VLMs). Moreover, we demonstrate that the methodology of FigStep can even jailbreak GPT-4V, which already leverages several system-level mechanisms to filter harmful queries. Above all, our experimental results reveal that VLMs are vulnerable to jailbreaking attacks, which highlights the necessity of novel safety alignments between visual and textual modalities.
Trash to Treasure: Low-Light Object Detection via Decomposition-and-Aggregation
Sep 07, 2023
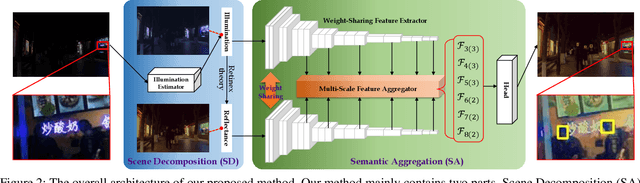
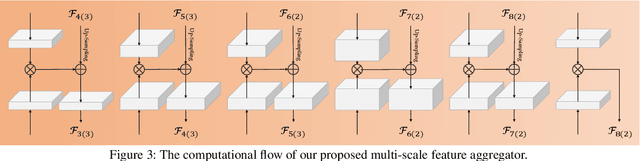

Object detection in low-light scenarios has attracted much attention in the past few years. A mainstream and representative scheme introduces enhancers as the pre-processing for regular detectors. However, because of the disparity in task objectives between the enhancer and detector, this paradigm cannot shine at its best ability. In this work, we try to arouse the potential of enhancer + detector. Different from existing works, we extend the illumination-based enhancers (our newly designed or existing) as a scene decomposition module, whose removed illumination is exploited as the auxiliary in the detector for extracting detection-friendly features. A semantic aggregation module is further established for integrating multi-scale scene-related semantic information in the context space. Actually, our built scheme successfully transforms the "trash" (i.e., the ignored illumination in the detector) into the "treasure" for the detector. Plenty of experiments are conducted to reveal our superiority against other state-of-the-art methods. The code will be public if it is accepted.
Dual Adversarial Resilience for Collaborating Robust Underwater Image Enhancement and Perception
Sep 03, 2023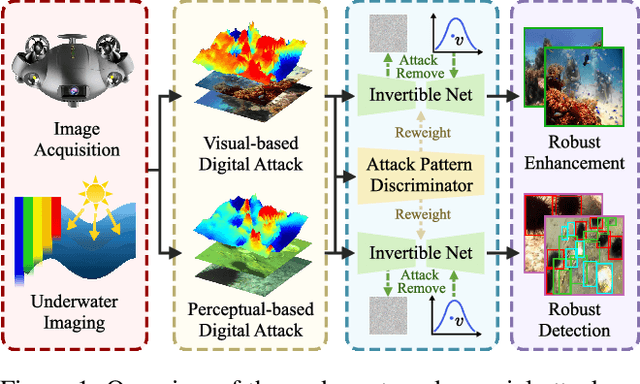
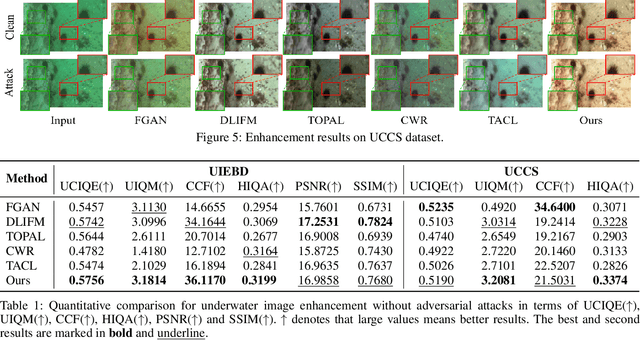
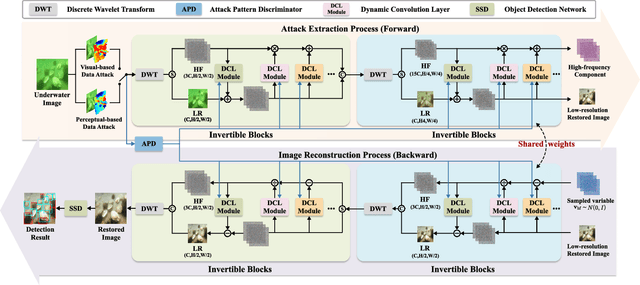
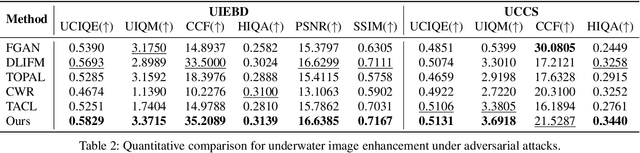
Due to the uneven scattering and absorption of different light wavelengths in aquatic environments, underwater images suffer from low visibility and clear color deviations. With the advancement of autonomous underwater vehicles, extensive research has been conducted on learning-based underwater enhancement algorithms. These works can generate visually pleasing enhanced images and mitigate the adverse effects of degraded images on subsequent perception tasks. However, learning-based methods are susceptible to the inherent fragility of adversarial attacks, causing significant disruption in results. In this work, we introduce a collaborative adversarial resilience network, dubbed CARNet, for underwater image enhancement and subsequent detection tasks. Concretely, we first introduce an invertible network with strong perturbation-perceptual abilities to isolate attacks from underwater images, preventing interference with image enhancement and perceptual tasks. Furthermore, we propose a synchronized attack training strategy with both visual-driven and perception-driven attacks enabling the network to discern and remove various types of attacks. Additionally, we incorporate an attack pattern discriminator to heighten the robustness of the network against different attacks. Extensive experiments demonstrate that the proposed method outputs visually appealing enhancement images and perform averagely 6.71% higher detection mAP than state-of-the-art methods.
AdvMono3D: Advanced Monocular 3D Object Detection with Depth-Aware Robust Adversarial Training
Sep 03, 2023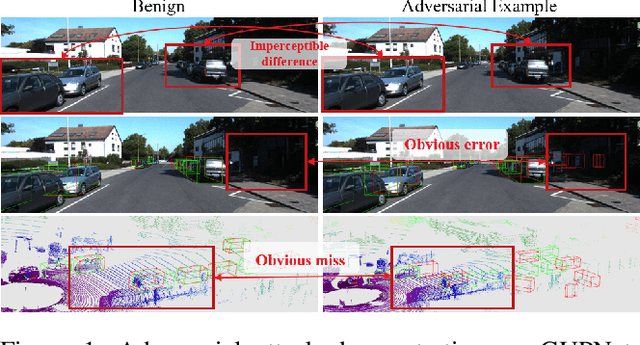
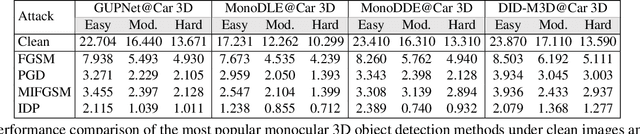
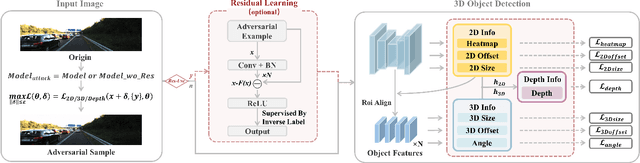

Monocular 3D object detection plays a pivotal role in the field of autonomous driving and numerous deep learning-based methods have made significant breakthroughs in this area. Despite the advancements in detection accuracy and efficiency, these models tend to fail when faced with such attacks, rendering them ineffective. Therefore, bolstering the adversarial robustness of 3D detection models has become a crucial issue that demands immediate attention and innovative solutions. To mitigate this issue, we propose a depth-aware robust adversarial training method for monocular 3D object detection, dubbed DART3D. Specifically, we first design an adversarial attack that iteratively degrades the 2D and 3D perception capabilities of 3D object detection models(IDP), serves as the foundation for our subsequent defense mechanism. In response to this attack, we propose an uncertainty-based residual learning method for adversarial training. Our adversarial training approach capitalizes on the inherent uncertainty, enabling the model to significantly improve its robustness against adversarial attacks. We conducted extensive experiments on the KITTI 3D datasets, demonstrating that DART3D surpasses direct adversarial training (the most popular approach) under attacks in 3D object detection $AP_{R40}$ of car category for the Easy, Moderate, and Hard settings, with improvements of 4.415%, 4.112%, and 3.195%, respectively.
Hybrid-Supervised Dual-Search: Leveraging Automatic Learning for Loss-free Multi-Exposure Image Fusion
Sep 03, 2023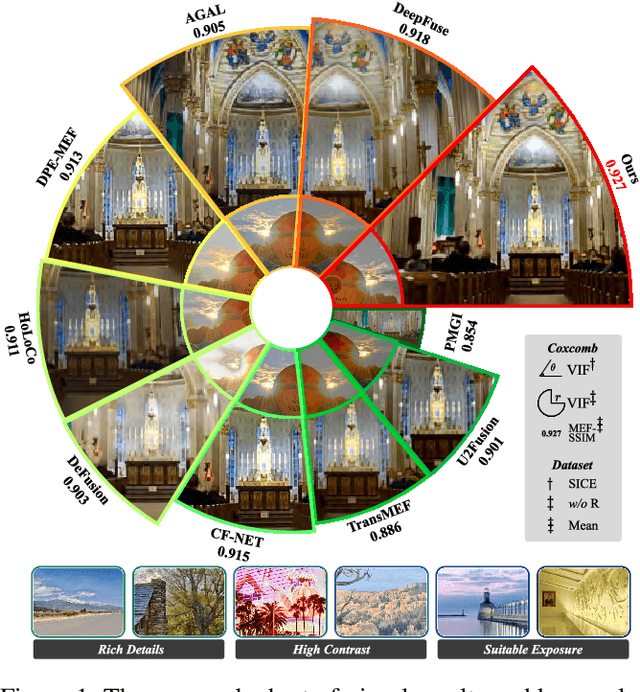

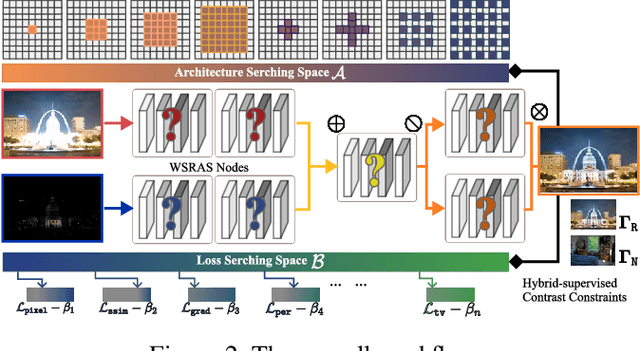
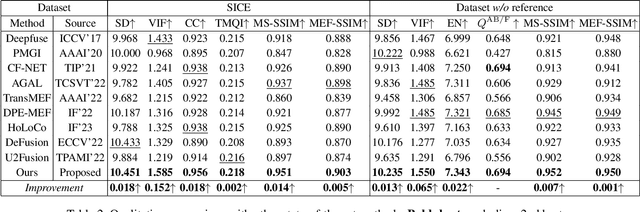
Multi-exposure image fusion (MEF) has emerged as a prominent solution to address the limitations of digital imaging in representing varied exposure levels. Despite its advancements, the field grapples with challenges, notably the reliance on manual designs for network structures and loss functions, and the constraints of utilizing simulated reference images as ground truths. Consequently, current methodologies often suffer from color distortions and exposure artifacts, further complicating the quest for authentic image representation. In addressing these challenges, this paper presents a Hybrid-Supervised Dual-Search approach for MEF, dubbed HSDS-MEF, which introduces a bi-level optimization search scheme for automatic design of both network structures and loss functions. More specifically, we harnesses a unique dual research mechanism rooted in a novel weighted structure refinement architecture search. Besides, a hybrid supervised contrast constraint seamlessly guides and integrates with searching process, facilitating a more adaptive and comprehensive search for optimal loss functions. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 10.61% and 4.38% improvement in Visual Information Fidelity (VIF) for general and no-reference scenarios, respectively, while providing results with high contrast, rich details and colors.