 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinze Li
MENTOR: Multi-level Self-supervised Learning for Multimodal Recommendation
Feb 29, 2024
With the increasing multimedia information, multimodal recommendation has received extensive attention. It utilizes multimodal information to alleviate the data sparsity problem in recommendation systems, thus improving recommendation accuracy. However, the reliance on labeled data severely limits the performance of multimodal recommendation models. Recently, self-supervised learning has been used in multimodal recommendations to mitigate the label sparsity problem. Nevertheless, the state-of-the-art methods cannot avoid the modality noise when aligning multimodal information due to the large differences in the distributions of different modalities. To this end, we propose a Multi-level sElf-supervised learNing for mulTimOdal Recommendation (MENTOR) method to address the label sparsity problem and the modality alignment problem. Specifically, MENTOR first enhances the specific features of each modality using the graph convolutional network (GCN) and fuses the visual and textual modalities. It then enhances the item representation via the item semantic graph for all modalities, including the fused modality. Then, it introduces two multilevel self-supervised tasks: the multilevel cross-modal alignment task and the general feature enhancement task. The multilevel cross-modal alignment task aligns each modality under the guidance of the ID embedding from multiple levels while maintaining the historical interaction information. The general feature enhancement task enhances the general feature from both the graph and feature perspectives to improve the robustness of our model. Extensive experiments on three publicly available datasets demonstrate the effectiveness of our method. Our code is publicly available at https://github.com/Jinfeng-Xu/MENTOR.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022
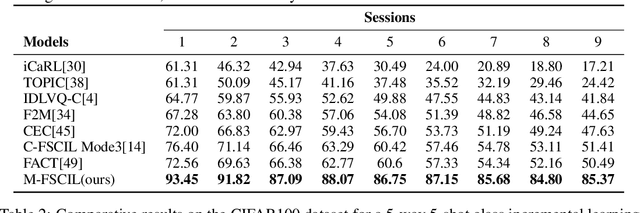
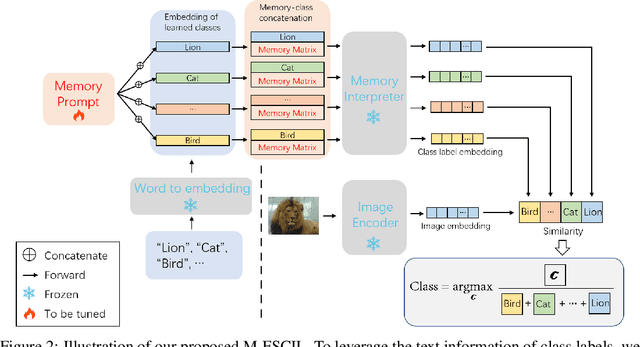
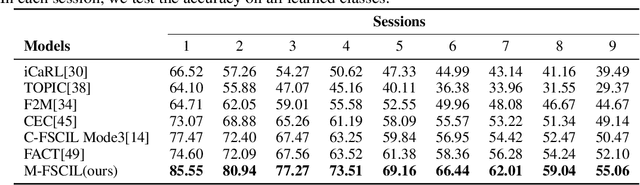
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
Nov 19, 2019
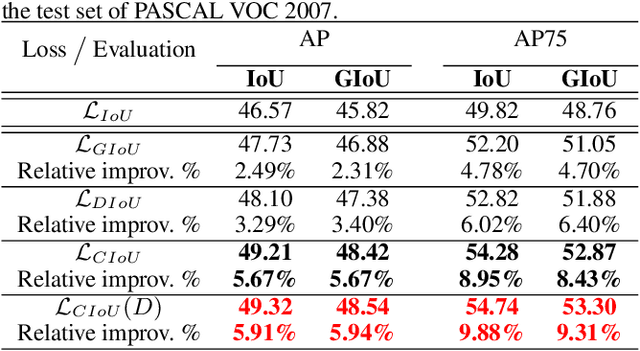
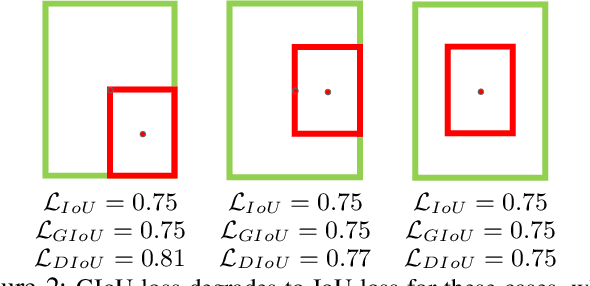
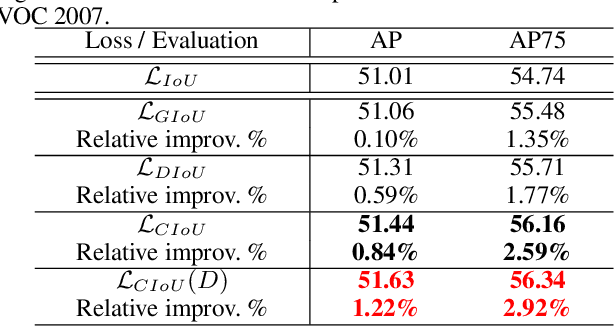
Bounding box regression is the crucial step in object detection. In existing methods, while $\ell_n$-norm loss is widely adopted for bounding box regression, it is not tailored to the evaluation metric, i.e., Intersection over Union (IoU). Recently, IoU loss and generalized IoU (GIoU) loss have been proposed to benefit the IoU metric, but still suffer from the problems of slow convergence and inaccurate regression. In this paper, we propose a Distance-IoU (DIoU) loss by incorporating the normalized distance between the predicted box and the target box, which converges much faster in training than IoU and GIoU losses. Furthermore, this paper summarizes three geometric factors in bounding box regression, \ie, overlap area, central point distance and aspect ratio, based on which a Complete IoU (CIoU) loss is proposed, thereby leading to faster convergence and better performance. By incorporating DIoU and CIoU losses into state-of-the-art object detection algorithms, e.g., YOLO v3, SSD and Faster RCNN, we achieve notable performance gains in terms of not only IoU metric but also GIoU metric. Moreover, DIoU can be easily adopted into non-maximum suppression (NMS) to act as the criterion, further boosting performance improvement. The source code and trained models are available at https://github.com/Zzh-tju/DIoU.