 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoão Ranhel
On the Linguistic and Computational Requirements for Creating Face-to-Face Multimodal Human-Machine Interaction
Nov 24, 2022
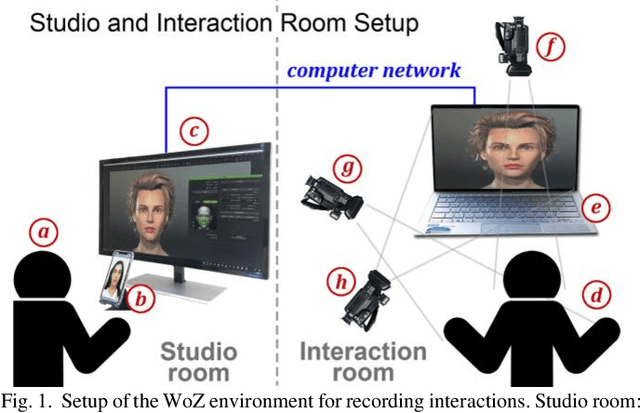
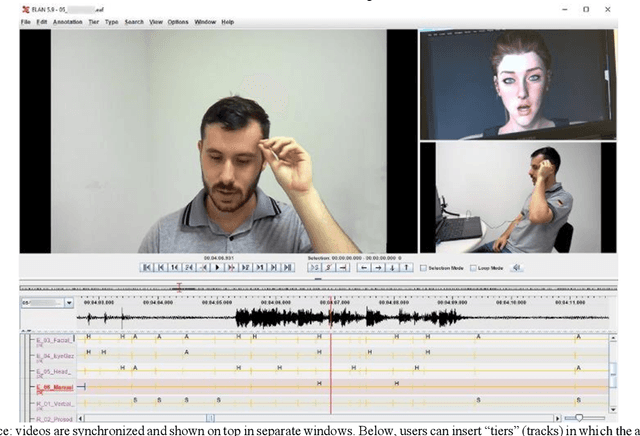
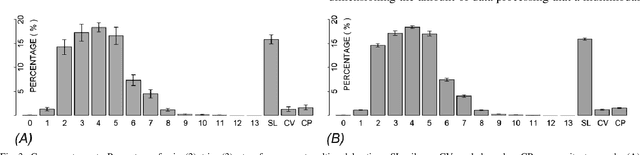
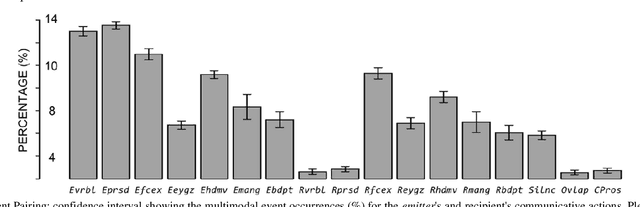
In this study, conversations between humans and avatars are linguistically, organizationally, and structurally analyzed, focusing on what is necessary for creating face-to-face multimodal interfaces for machines. We videorecorded thirty-four human-avatar interactions, performed complete linguistic microanalysis on video excerpts, and marked all the occurrences of multimodal actions and events. Statistical inferences were applied to data, allowing us to comprehend not only how often multimodal actions occur but also how multimodal events are distributed between the speaker (emitter) and the listener (recipient). We also observed the distribution of multimodal occurrences for each modality. The data show evidence that double-loop feedback is established during a face-to-face conversation. This led us to propose that knowledge from Conversation Analysis (CA), cognitive science, and Theory of Mind (ToM), among others, should be incorporated into the ones used for describing human-machine multimodal interactions. Face-to-face interfaces require an additional control layer to the multimodal fusion layer. This layer has to organize the flow of conversation, integrate the social context into the interaction, as well as make plans concerning 'what' and 'how' to progress on the interaction. This higher level is best understood if we incorporate insights from CA and ToM into the interface system.
Guidelines for creating man-machine multimodal interfaces
Jan 29, 2019
Understanding details of human multimodal interaction can elucidate many aspects of the type of information processing machines must perform to interact with humans. This article gives an overview of recent findings from Linguistics regarding the organization of conversation in turns, adjacent pairs, (dis)preferred responses, (self)repairs, etc. Besides, we describe how multiple modalities of signs interfere with each other modifying meanings. Then, we propose an abstract algorithm that describes how a machine can implement a double-feedback system that can reproduces a human-like face-to-face interaction by processing various signs, such as verbal, prosodic, facial expressions, gestures, etc. Multimodal face-to-face interactions enrich the exchange of information between agents, mainly because these agents are active all the time by emitting and interpreting signs simultaneously. This article is not about an untested new computational model. Instead, it translates findings from Linguistics as guidelines for designs of multimodal man-machine interfaces. An algorithm is presented. Brought from Linguistics, it is a description pointing out how human face-to-face interactions work. The linguistic findings reported here are the first steps towards the integration of multimodal communication. Some developers involved on interface designs carry on working on isolated models for interpreting text, grammar, gestures and facial expressions, neglecting the interwoven between these signs. In contrast, for linguists working on the state-of-the-art multimodal integration, the interpretation of separated modalities leads to an incomplete interpretation, if not to a miscomprehension of information. The algorithm proposed herein intends to guide man-machine interface designers who want to integrate multimodal components on face-to-face interactions as close as possible to those performed between humans.
A Draft Memory Model on Spiking Neural Assemblies
Mar 26, 2016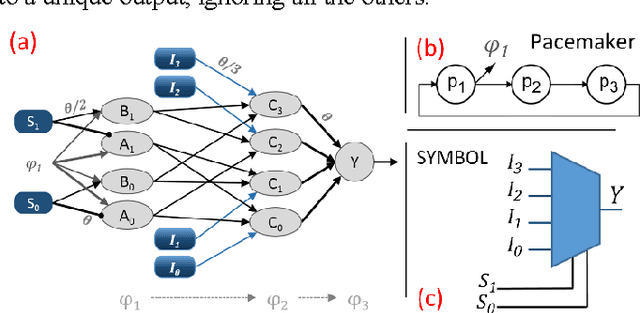
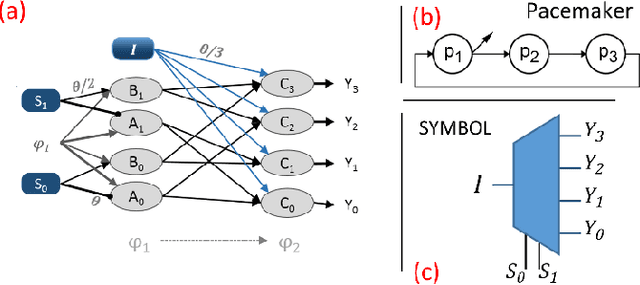
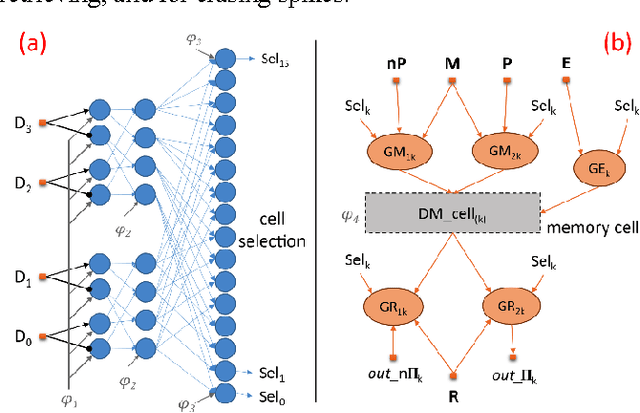
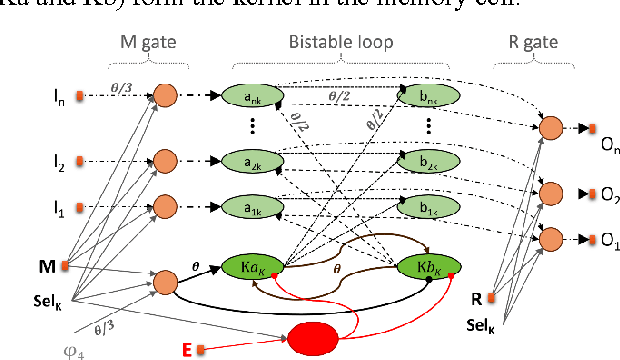
A draft memory model (DM) for neural networks with spike propagation delay (SNNwD) is described. Novelty in this approach are that the DM learns immediately, with stimuli presented once, without synaptic weight changes, and without external learning algorithm. Basal on this model is to trap spikes within neural loops. In order to construct the DM we developed two functional blocks, also described herein. The decoder block receives input from a single spikes source and connect it to one among many outputs. The selector block operates in the opposite direction, receiving many spikes sources and connecting one of them to a single output. We realized conceptual proofs by testing the DM in the prime numbers classifying task. This activation-based memory can be used as immediate and short-term memory.