 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoey Hong
LMRL Gym: Benchmarks for Multi-Turn Reinforcement Learning with Language Models
Nov 30, 2023
Large language models (LLMs) provide excellent text-generation capabilities, but standard prompting and generation methods generally do not lead to intentional or goal-directed agents and might necessitate considerable prompt tuning. This becomes particularly apparent in multi-turn conversations: even the best current LLMs rarely ask clarifying questions, engage in explicit information gathering, or take actions now that lead to better decisions after multiple turns. Reinforcement learning has the potential to leverage the powerful modeling capabilities of LLMs, as well as their internal representation of textual interactions, to create capable goal-directed language agents. This can enable intentional and temporally extended interactions, such as with humans, through coordinated persuasion and carefully crafted questions, or in goal-directed play through text games to bring about desired final outcomes. However, enabling this requires the community to develop stable and reliable reinforcement learning algorithms that can effectively train LLMs. Developing such algorithms requires tasks that can gauge progress on algorithm design, provide accessible and reproducible evaluations for multi-turn interactions, and cover a range of task properties and challenges in improving reinforcement learning algorithms. Our paper introduces the LMRL-Gym benchmark for evaluating multi-turn RL for LLMs, together with an open-source research framework containing a basic toolkit for getting started on multi-turn RL with offline value-based and policy-based RL methods. Our benchmark consists of 8 different language tasks, which require multiple rounds of language interaction and cover a range of tasks in open-ended dialogue and text games.
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations
Nov 09, 2023Large language models (LLMs) have emerged as powerful and general solutions to many natural language tasks. However, many of the most important applications of language generation are interactive, where an agent has to talk to a person to reach a desired outcome. For example, a teacher might try to understand their student's current comprehension level to tailor their instruction accordingly, and a travel agent might ask questions of their customer to understand their preferences in order to recommend activities they might enjoy. LLMs trained with supervised fine-tuning or "single-step" RL, as with standard RLHF, might struggle which tasks that require such goal-directed behavior, since they are not trained to optimize for overall conversational outcomes after multiple turns of interaction. In this work, we explore a new method for adapting LLMs with RL for such goal-directed dialogue. Our key insight is that, though LLMs might not effectively solve goal-directed dialogue tasks out of the box, they can provide useful data for solving such tasks by simulating suboptimal but human-like behaviors. Given a textual description of a goal-directed dialogue task, we leverage LLMs to sample diverse synthetic rollouts of hypothetical in-domain human-human interactions. Our algorithm then utilizes this dataset with offline reinforcement learning to train an interactive conversational agent that can optimize goal-directed objectives over multiple turns. In effect, the LLM produces examples of possible interactions, and RL then processes these examples to learn to perform more optimal interactions. Empirically, we show that our proposed approach achieves state-of-the-art performance in various goal-directed dialogue tasks that include teaching and preference elicitation.
Offline RL with Observation Histories: Analyzing and Improving Sample Complexity
Oct 31, 2023Offline reinforcement learning (RL) can in principle synthesize more optimal behavior from a dataset consisting only of suboptimal trials. One way that this can happen is by "stitching" together the best parts of otherwise suboptimal trajectories that overlap on similar states, to create new behaviors where each individual state is in-distribution, but the overall returns are higher. However, in many interesting and complex applications, such as autonomous navigation and dialogue systems, the state is partially observed. Even worse, the state representation is unknown or not easy to define. In such cases, policies and value functions are often conditioned on observation histories instead of states. In these cases, it is not clear if the same kind of "stitching" is feasible at the level of observation histories, since two different trajectories would always have different histories, and thus "similar states" that might lead to effective stitching cannot be leveraged. Theoretically, we show that standard offline RL algorithms conditioned on observation histories suffer from poor sample complexity, in accordance with the above intuition. We then identify sufficient conditions under which offline RL can still be efficient -- intuitively, it needs to learn a compact representation of history comprising only features relevant for action selection. We introduce a bisimulation loss that captures the extent to which this happens, and propose that offline RL can explicitly optimize this loss to aid worst-case sample complexity. Empirically, we show that across a variety of tasks either our proposed loss improves performance, or the value of this loss is already minimized as a consequence of standard offline RL, indicating that it correlates well with good performance.
ExeDec: Execution Decomposition for Compositional Generalization in Neural Program Synthesis
Jul 26, 2023When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, we can measure whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we characterize several different forms of compositional generalization that are desirable in program synthesis, forming a meta-benchmark which we use to create generalization tasks for two popular datasets, RobustFill and DeepCoder. We then propose ExeDec, a novel decomposition-based synthesis strategy that predicts execution subgoals to solve problems step-by-step informed by program execution at each step. ExeDec has better synthesis performance and greatly improved compositional generalization ability compared to baselines.
Learning to Influence Human Behavior with Offline Reinforcement Learning
Mar 10, 2023


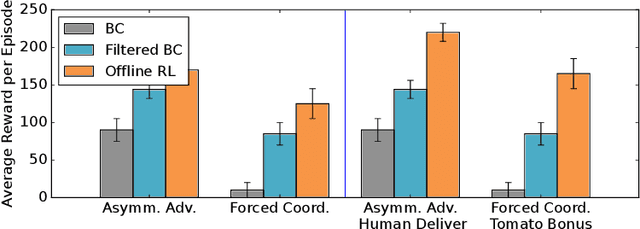
In the real world, some of the most complex settings for learned agents involve interaction with humans, who often exhibit suboptimal, unpredictable behavior due to sophisticated biases. Agents that interact with people in such settings end up influencing the actions that these people take. Our goal in this work is to enable agents to leverage that influence to improve the human's performance in collaborative tasks, as the task unfolds. Unlike prior work, we do not assume online training with people (which tends to be too expensive and unsafe), nor access to a high fidelity simulator of the environment. Our idea is that by taking a variety of previously observed human-human interaction data and labeling it with the task reward, offline reinforcement learning (RL) can learn to combine components of behavior, and uncover actions that lead to more desirable human actions. First, we show that offline RL can learn strategies to influence and improve human behavior, despite those strategies not appearing in the dataset, by utilizing components of diverse, suboptimal interactions. In addition, we demonstrate that offline RL can learn influence that adapts with humans, thus achieving long-term coordination with them even when their behavior changes. We evaluate our proposed method with real people in the Overcooked collaborative benchmark domain, and demonstrate successful improvement in human performance.
Multi-Task Off-Policy Learning from Bandit Feedback
Dec 09, 2022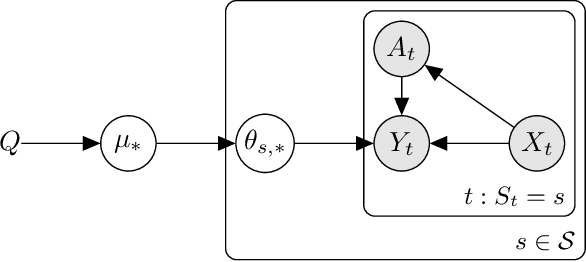

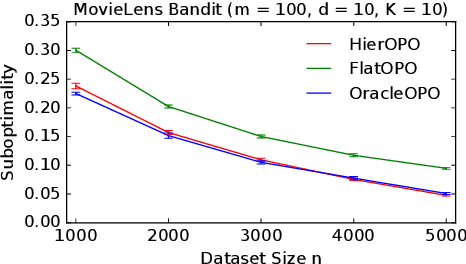
Many practical applications, such as recommender systems and learning to rank, involve solving multiple similar tasks. One example is learning of recommendation policies for users with similar movie preferences, where the users may still rank the individual movies slightly differently. Such tasks can be organized in a hierarchy, where similar tasks are related through a shared structure. In this work, we formulate this problem as a contextual off-policy optimization in a hierarchical graphical model from logged bandit feedback. To solve the problem, we propose a hierarchical off-policy optimization algorithm (HierOPO), which estimates the parameters of the hierarchical model and then acts pessimistically with respect to them. We instantiate HierOPO in linear Gaussian models, for which we also provide an efficient implementation and analysis. We prove per-task bounds on the suboptimality of the learned policies, which show a clear improvement over not using the hierarchical model. We also evaluate the policies empirically. Our theoretical and empirical results show a clear advantage of using the hierarchy over solving each task independently.
On the Sensitivity of Reward Inference to Misspecified Human Models
Dec 09, 2022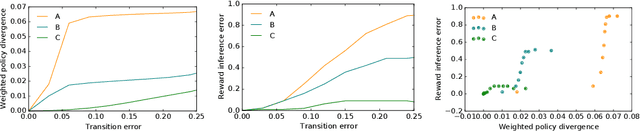

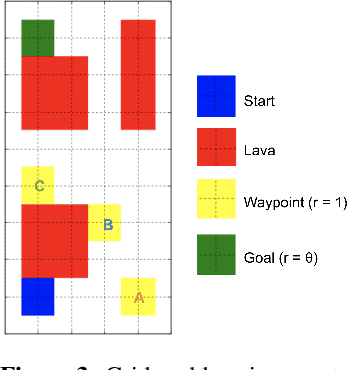
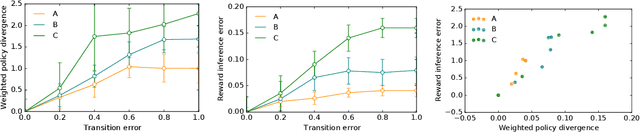
Inferring reward functions from human behavior is at the center of value alignment - aligning AI objectives with what we, humans, actually want. But doing so relies on models of how humans behave given their objectives. After decades of research in cognitive science, neuroscience, and behavioral economics, obtaining accurate human models remains an open research topic. This begs the question: how accurate do these models need to be in order for the reward inference to be accurate? On the one hand, if small errors in the model can lead to catastrophic error in inference, the entire framework of reward learning seems ill-fated, as we will never have perfect models of human behavior. On the other hand, if as our models improve, we can have a guarantee that reward accuracy also improves, this would show the benefit of more work on the modeling side. We study this question both theoretically and empirically. We do show that it is unfortunately possible to construct small adversarial biases in behavior that lead to arbitrarily large errors in the inferred reward. However, and arguably more importantly, we are also able to identify reasonable assumptions under which the reward inference error can be bounded linearly in the error in the human model. Finally, we verify our theoretical insights in discrete and continuous control tasks with simulated and human data.
Confidence-Conditioned Value Functions for Offline Reinforcement Learning
Dec 08, 2022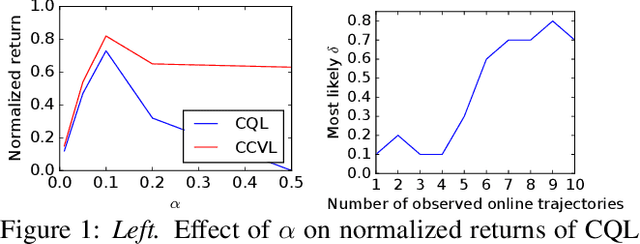

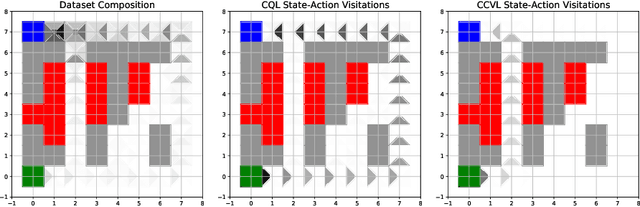
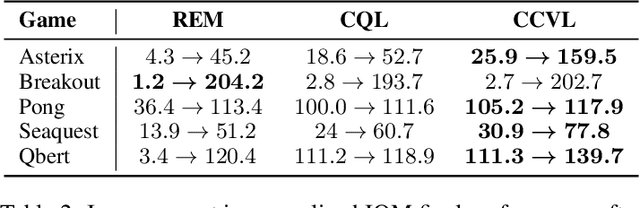
Offline reinforcement learning (RL) promises the ability to learn effective policies solely using existing, static datasets, without any costly online interaction. To do so, offline RL methods must handle distributional shift between the dataset and the learned policy. The most common approach is to learn conservative, or lower-bound, value functions, which underestimate the return of out-of-distribution (OOD) actions. However, such methods exhibit one notable drawback: policies optimized on such value functions can only behave according to a fixed, possibly suboptimal, degree of conservatism. However, this can be alleviated if we instead are able to learn policies for varying degrees of conservatism at training time and devise a method to dynamically choose one of them during evaluation. To do so, in this work, we propose learning value functions that additionally condition on the degree of conservatism, which we dub confidence-conditioned value functions. We derive a new form of a Bellman backup that simultaneously learns Q-values for any degree of confidence with high probability. By conditioning on confidence, our value functions enable adaptive strategies during online evaluation by controlling for confidence level using the history of observations thus far. This approach can be implemented in practice by conditioning the Q-function from existing conservative algorithms on the confidence. We theoretically show that our learned value functions produce conservative estimates of the true value at any desired confidence. Finally, we empirically show that our algorithm outperforms existing conservative offline RL algorithms on multiple discrete control domains.
When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?
Apr 12, 2022



Offline reinforcement learning (RL) algorithms can acquire effective policies by utilizing previously collected experience, without any online interaction. It is widely understood that offline RL is able to extract good policies even from highly suboptimal data, a scenario where imitation learning finds suboptimal solutions that do not improve over the demonstrator that generated the dataset. However, another common use case for practitioners is to learn from data that resembles demonstrations. In this case, one can choose to apply offline RL, but can also use behavioral cloning (BC) algorithms, which mimic a subset of the dataset via supervised learning. Therefore, it seems natural to ask: when can an offline RL method outperform BC with an equal amount of expert data, even when BC is a natural choice? To answer this question, we characterize the properties of environments that allow offline RL methods to perform better than BC methods, even when only provided with expert data. Additionally, we show that policies trained on sufficiently noisy suboptimal data can attain better performance than even BC algorithms with expert data, especially on long-horizon problems. We validate our theoretical results via extensive experiments on both diagnostic and high-dimensional domains including robotic manipulation, maze navigation, and Atari games, with a variety of data distributions. We observe that, under specific but common conditions such as sparse rewards or noisy data sources, modern offline RL methods can significantly outperform BC.
Compositional Generalization and Decomposition in Neural Program Synthesis
Apr 07, 2022
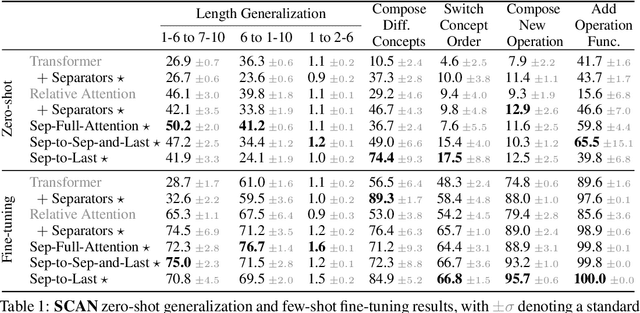
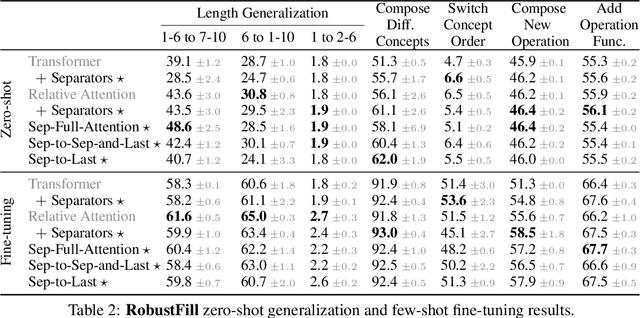

When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, what we can measure is whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we focus on measuring the ability of learned program synthesizers to compositionally generalize. We first characterize several different axes along which program synthesis methods would be desired to generalize, e.g., length generalization, or the ability to combine known subroutines in new ways that do not occur in the training data. Based on this characterization, we introduce a benchmark suite of tasks to assess these abilities based on two popular existing datasets, SCAN and RobustFill. Finally, we make first attempts to improve the compositional generalization ability of Transformer models along these axes through novel attention mechanisms that draw inspiration from a human-like decomposition strategy. Empirically, we find our modified Transformer models generally perform better than natural baselines, but the tasks remain challenging.