 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJohannes Maucher
Trapped in texture bias? A large scale comparison of deep instance segmentation
Jan 17, 2024
Do deep learning models for instance segmentation generalize to novel objects in a systematic way? For classification, such behavior has been questioned. In this study, we aim to understand if certain design decisions such as framework, architecture or pre-training contribute to the semantic understanding of instance segmentation. To answer this question, we consider a special case of robustness and compare pre-trained models on a challenging benchmark for object-centric, out-of-distribution texture. We do not introduce another method in this work. Instead, we take a step back and evaluate a broad range of existing literature. This includes Cascade and Mask R-CNN, Swin Transformer, BMask, YOLACT(++), DETR, BCNet, SOTR and SOLOv2. We find that YOLACT++, SOTR and SOLOv2 are significantly more robust to out-of-distribution texture than other frameworks. In addition, we show that deeper and dynamic architectures improve robustness whereas training schedules, data augmentation and pre-training have only a minor impact. In summary we evaluate 68 models on 61 versions of MS COCO for a total of 4148 evaluations.
* Accepted at ECCV 2022. Code: https://github.com/JohannesTheo/trapped-in-texture-bias
Learning of Generalizable and Interpretable Knowledge in Grid-Based Reinforcement Learning Environments
Sep 07, 2023
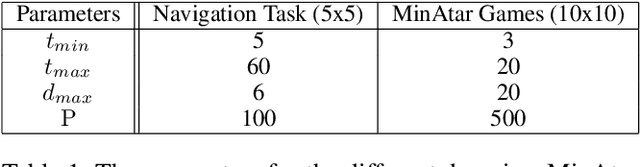

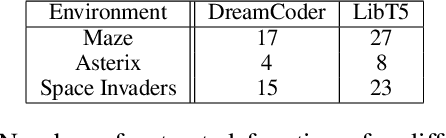
Understanding the interactions of agents trained with deep reinforcement learning is crucial for deploying agents in games or the real world. In the former, unreasonable actions confuse players. In the latter, that effect is even more significant, as unexpected behavior cause accidents with potentially grave and long-lasting consequences for the involved individuals. In this work, we propose using program synthesis to imitate reinforcement learning policies after seeing a trajectory of the action sequence. Programs have the advantage that they are inherently interpretable and verifiable for correctness. We adapt the state-of-the-art program synthesis system DreamCoder for learning concepts in grid-based environments, specifically, a navigation task and two miniature versions of Atari games, Space Invaders and Asterix. By inspecting the generated libraries, we can make inferences about the concepts the black-box agent has learned and better understand the agent's behavior. We achieve the same by visualizing the agent's decision-making process for the imitated sequences. We evaluate our approach with different types of program synthesizers based on a search-only method, a neural-guided search, and a language model fine-tuned on code.
Fine-tuning BERT for Low-Resource Natural Language Understanding via Active Learning
Dec 04, 2020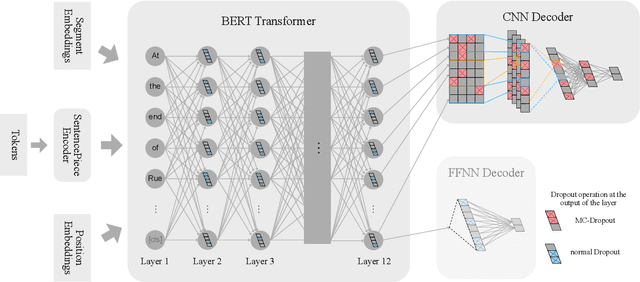
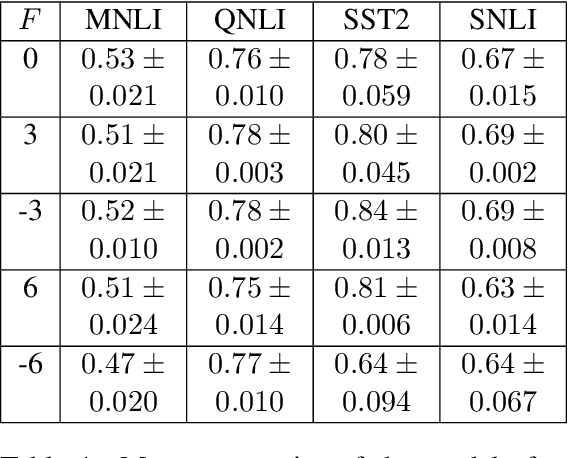

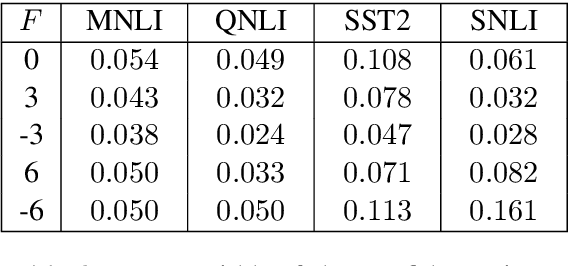
Recently, leveraging pre-trained Transformer based language models in down stream, task specific models has advanced state of the art results in natural language understanding tasks. However, only a little research has explored the suitability of this approach in low resource settings with less than 1,000 training data points. In this work, we explore fine-tuning methods of BERT -- a pre-trained Transformer based language model -- by utilizing pool-based active learning to speed up training while keeping the cost of labeling new data constant. Our experimental results on the GLUE data set show an advantage in model performance by maximizing the approximate knowledge gain of the model when querying from the pool of unlabeled data. Finally, we demonstrate and analyze the benefits of freezing layers of the language model during fine-tuning to reduce the number of trainable parameters, making it more suitable for low-resource settings.
Low-Resource Text Classification using Domain-Adversarial Learning
Jul 13, 2018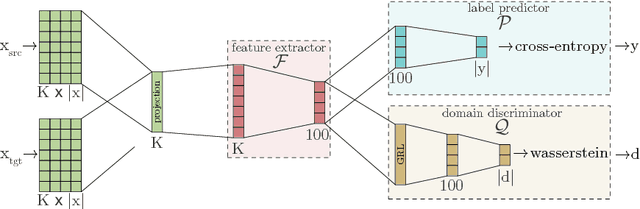
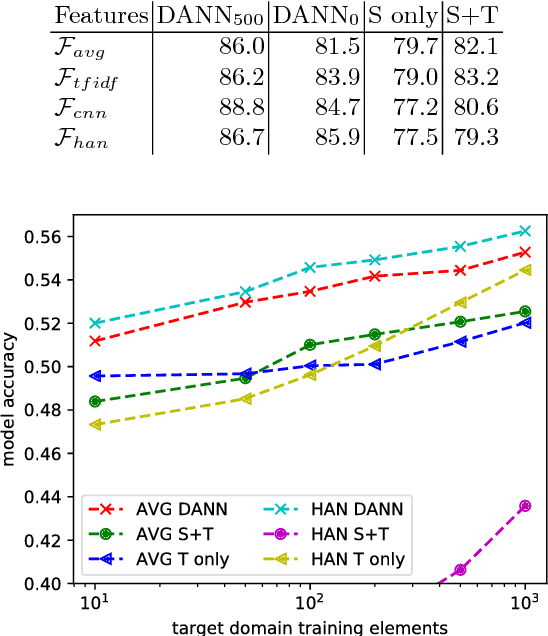
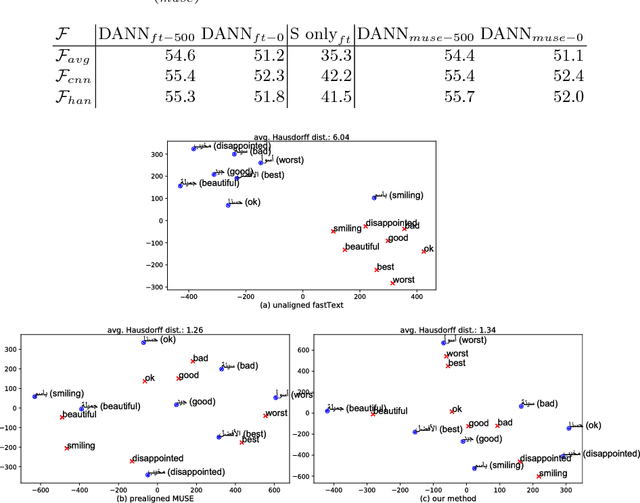
Deep learning techniques have recently shown to be successful in many natural language processing tasks forming state-of-the-art systems. They require, however, a large amount of annotated data which is often missing. This paper explores the use of domain-adversarial learning as a regularizer to avoid overfitting when training domain invariant features for deep, complex neural network in low-resource and zero-resource settings in new target domains or languages. In the case of new languages, we show that monolingual word-vectors can be directly used for training without pre-alignment. Their projection into a common space can be learnt ad-hoc at training time reaching the final performance of pretrained multilingual word-vectors.