 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJonathan Raiman
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023
ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning
May 14, 2022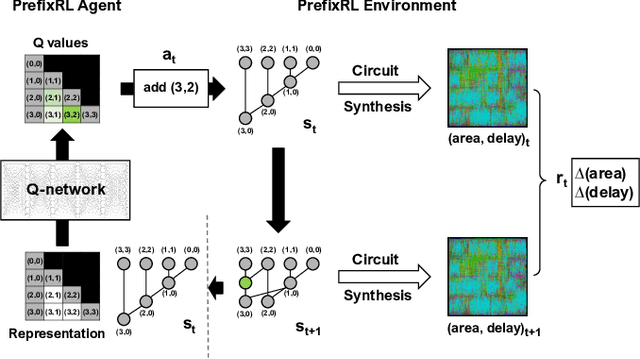
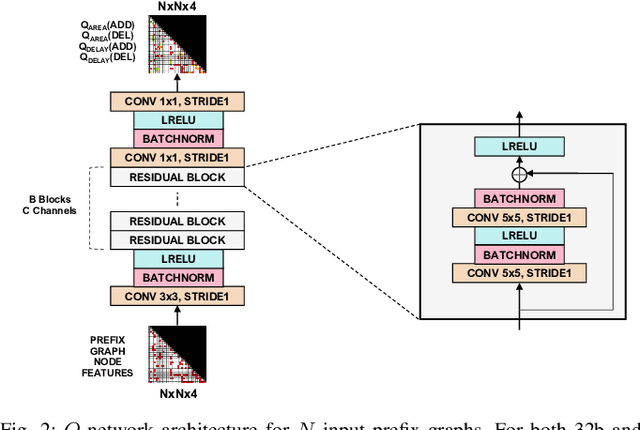
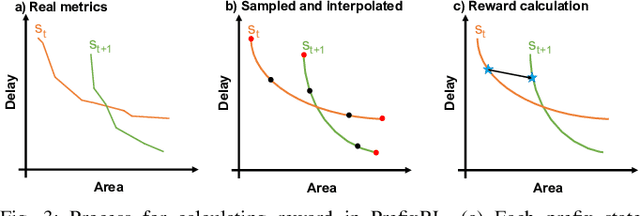
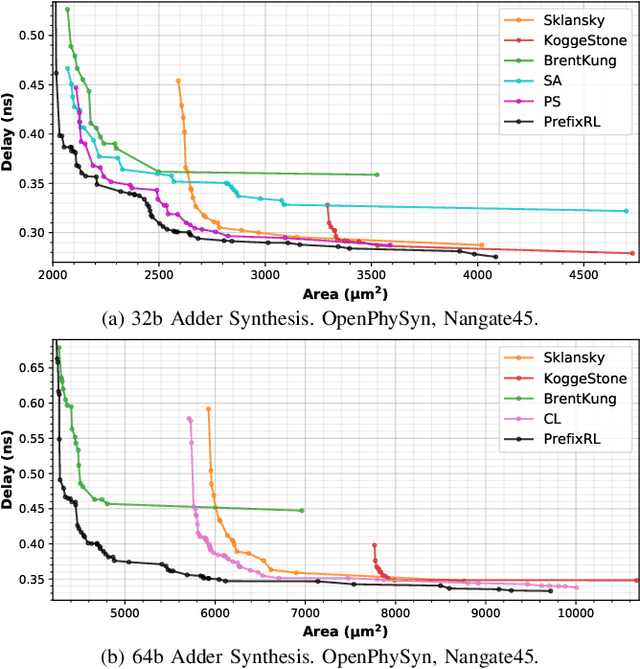
In this work, we present a reinforcement learning (RL) based approach to designing parallel prefix circuits such as adders or priority encoders that are fundamental to high-performance digital design. Unlike prior methods, our approach designs solutions tabula rasa purely through learning with synthesis in the loop. We design a grid-based state-action representation and an RL environment for constructing legal prefix circuits. Deep Convolutional RL agents trained on this environment produce prefix adder circuits that Pareto-dominate existing baselines with up to 16.0% and 30.2% lower area for the same delay in the 32b and 64b settings respectively. We observe that agents trained with open-source synthesis tools and cell library can design adder circuits that achieve lower area and delay than commercial tool adders in an industrial cell library.
* Copyright 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Generative Adversarial Simulator
Nov 23, 2020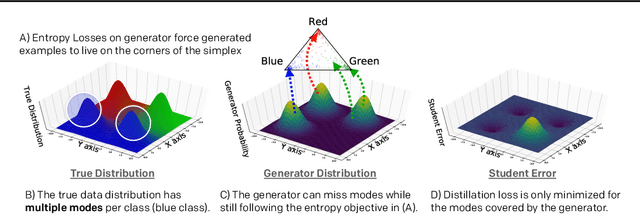
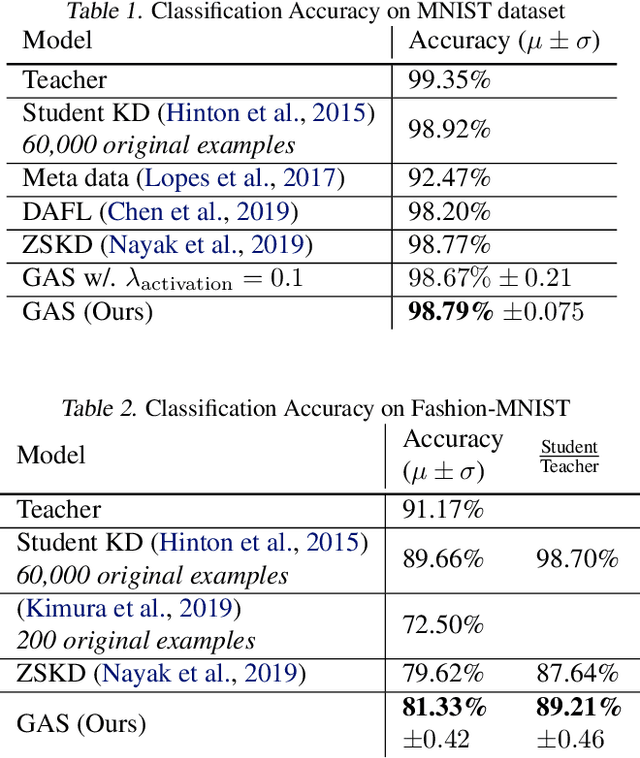
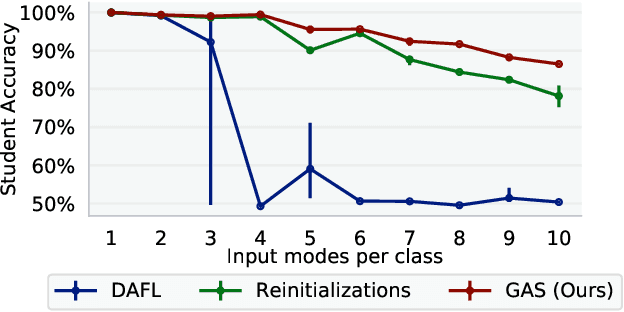
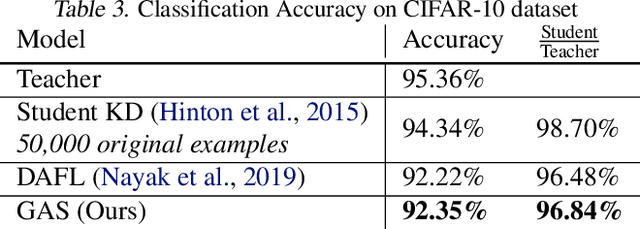
Knowledge distillation between machine learning models has opened many new avenues for parameter count reduction, performance improvements, or amortizing training time when changing architectures between the teacher and student network. In the case of reinforcement learning, this technique has also been applied to distill teacher policies to students. Until now, policy distillation required access to a simulator or real world trajectories. In this paper we introduce a simulator-free approach to knowledge distillation in the context of reinforcement learning. A key challenge is having the student learn the multiplicity of cases that correspond to a given action. While prior work has shown that data-free knowledge distillation is possible with supervised learning models by generating synthetic examples, these approaches to are vulnerable to only producing a single prototype example for each class. We propose an extension to explicitly handle multiple observations per output class that seeks to find as many exemplars as possible for a given output class by reinitializing our data generator and making use of an adversarial loss. To the best of our knowledge, this is the first demonstration of simulator-free knowledge distillation between a teacher and a student policy. This new approach improves over the state of the art on data-free learning of student networks on benchmark datasets (MNIST, Fashion-MNIST, CIFAR-10), and we also demonstrate that it specifically tackles issues with multiple input modes. We also identify open problems when distilling agents trained in high dimensional environments such as Pong, Breakout, or Seaquest.
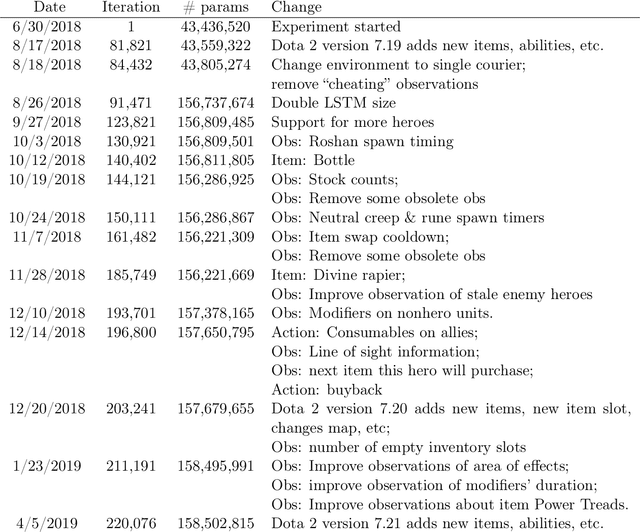
Long-Term Planning and Situational Awareness in OpenAI Five
Dec 13, 2019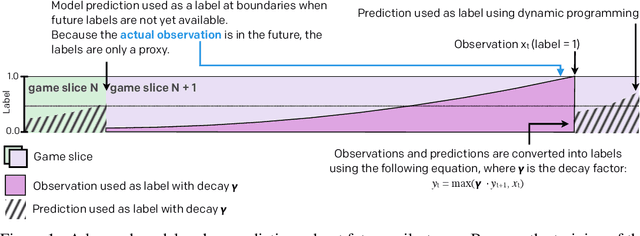
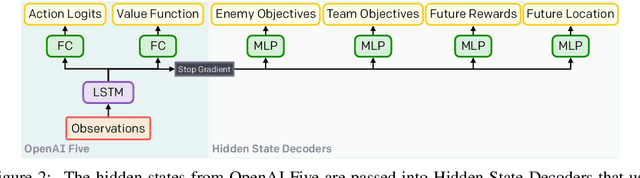
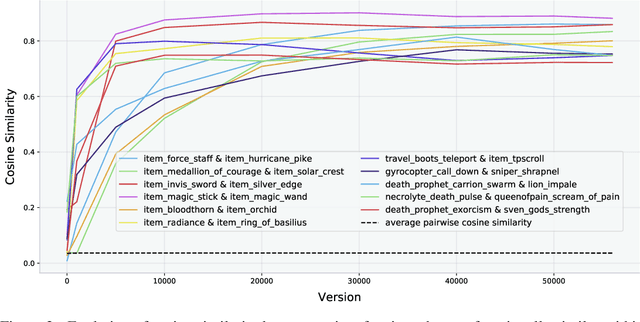
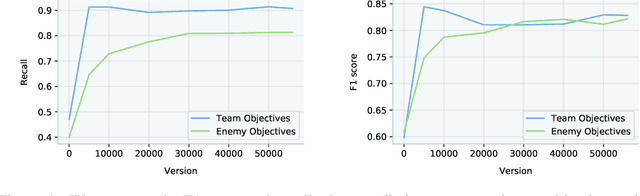
Understanding how knowledge about the world is represented within model-free deep reinforcement learning methods is a major challenge given the black box nature of its learning process within high-dimensional observation and action spaces. AlphaStar and OpenAI Five have shown that agents can be trained without any explicit hierarchical macro-actions to reach superhuman skill in games that require taking thousands of actions before reaching the final goal. Assessing the agent's plans and game understanding becomes challenging given the lack of hierarchy or explicit representations of macro-actions in these models, coupled with the incomprehensible nature of the internal representations. In this paper, we study the distributed representations learned by OpenAI Five to investigate how game knowledge is gradually obtained over the course of training. We also introduce a general technique for learning a model from the agent's hidden states to identify the formation of plans and subgoals. We show that the agent can learn situational similarity across actions, and find evidence of planning towards accomplishing subgoals minutes before they are executed. We perform a qualitative analysis of these predictions during the games against the DotA 2 world champions OG in April 2019.
Neural Network Surgery with Sets
Dec 13, 2019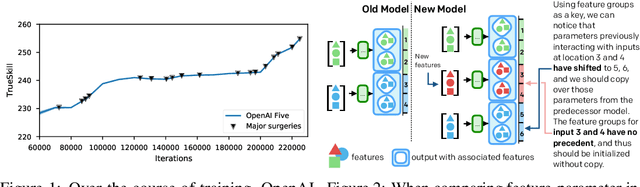


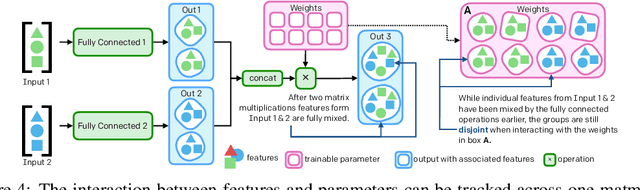
The cost to train machine learning models has been increasing exponentially, making exploration and research into the correct features and architecture a costly or intractable endeavor at scale. However, using a technique named "surgery" OpenAI Five was continuously trained to play the game DotA 2 over the course of 10 months through 20 major changes in features and architecture. Surgery transfers trained weights from one network to another after a selection process to determine which sections of the model are unchanged and which must be re-initialized. In the past, the selection process relied on heuristics, manual labor, or pre-existing boundaries in the structure of the model, limiting the ability to salvage experiments after modifications of the feature set or input reorderings. We propose a solution to automatically determine which components of a neural network model should be salvaged and which require retraining. We achieve this by allowing the model to operate over discrete sets of features and use set-based operations to determine the exact relationship between inputs and outputs, and how they change across tweaks in model architecture. In this paper, we introduce the methodology for enabling neural networks to operate on sets, derive two methods for detecting feature-parameter interaction maps, and show their equivalence. We empirically validate that we can surgery weights across feature and architecture changes to the OpenAI Five model.
Dota 2 with Large Scale Deep Reinforcement Learning
Dec 13, 2019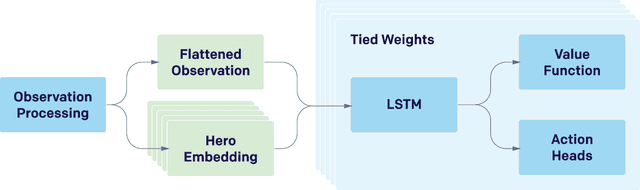

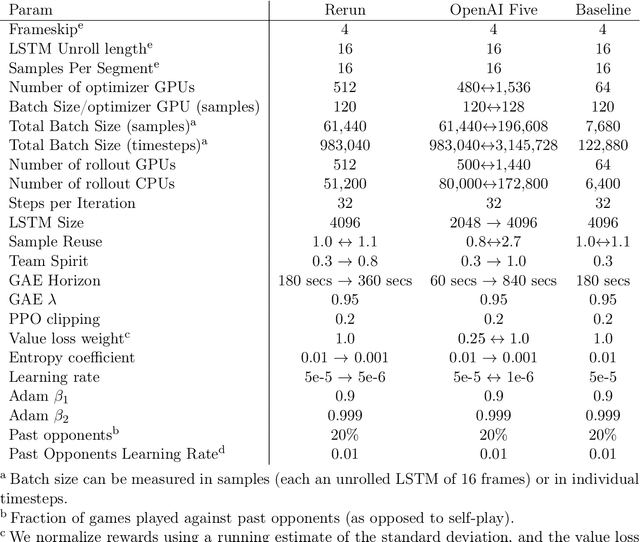
On April 13th, 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game of Dota 2 presents novel challenges for AI systems such as long time horizons, imperfect information, and complex, continuous state-action spaces, all challenges which will become increasingly central to more capable AI systems. OpenAI Five leveraged existing reinforcement learning techniques, scaled to learn from batches of approximately 2 million frames every 2 seconds. We developed a distributed training system and tools for continual training which allowed us to train OpenAI Five for 10 months. By defeating the Dota 2 world champion (Team OG), OpenAI Five demonstrates that self-play reinforcement learning can achieve superhuman performance on a difficult task.
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Feb 22, 2018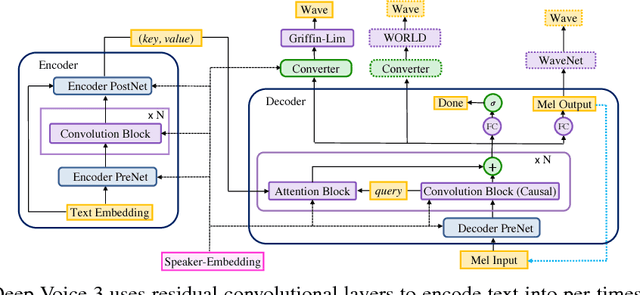

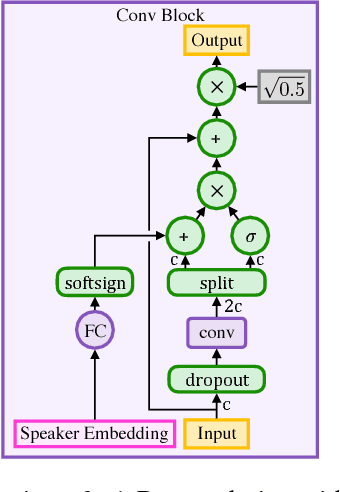
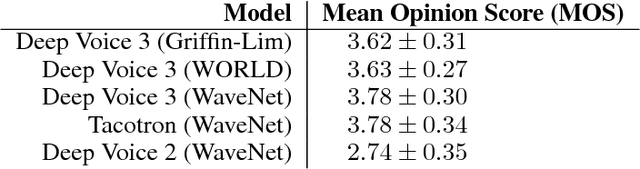
We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster. We scale Deep Voice 3 to data set sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on one single-GPU server.
DeepType: Multilingual Entity Linking by Neural Type System Evolution
Feb 03, 2018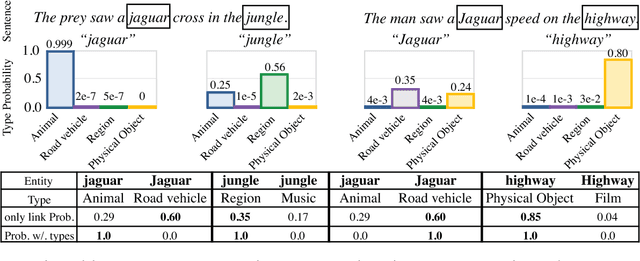
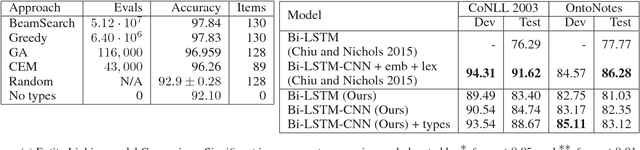
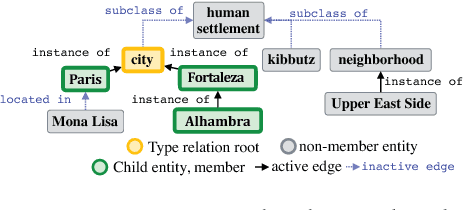
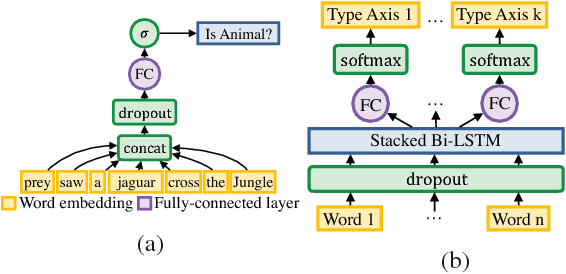
The wealth of structured (e.g. Wikidata) and unstructured data about the world available today presents an incredible opportunity for tomorrow's Artificial Intelligence. So far, integration of these two different modalities is a difficult process, involving many decisions concerning how best to represent the information so that it will be captured or useful, and hand-labeling large amounts of data. DeepType overcomes this challenge by explicitly integrating symbolic information into the reasoning process of a neural network with a type system. First we construct a type system, and second, we use it to constrain the outputs of a neural network to respect the symbolic structure. We achieve this by reformulating the design problem into a mixed integer problem: create a type system and subsequently train a neural network with it. In this reformulation discrete variables select which parent-child relations from an ontology are types within the type system, while continuous variables control a classifier fit to the type system. The original problem cannot be solved exactly, so we propose a 2-step algorithm: 1) heuristic search or stochastic optimization over discrete variables that define a type system informed by an Oracle and a Learnability heuristic, 2) gradient descent to fit classifier parameters. We apply DeepType to the problem of Entity Linking on three standard datasets (i.e. WikiDisamb30, CoNLL (YAGO), TAC KBP 2010) and find that it outperforms all existing solutions by a wide margin, including approaches that rely on a human-designed type system or recent deep learning-based entity embeddings, while explicitly using symbolic information lets it integrate new entities without retraining.
Deep Voice 2: Multi-Speaker Neural Text-to-Speech
Sep 20, 2017
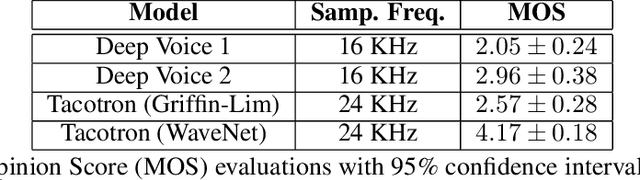
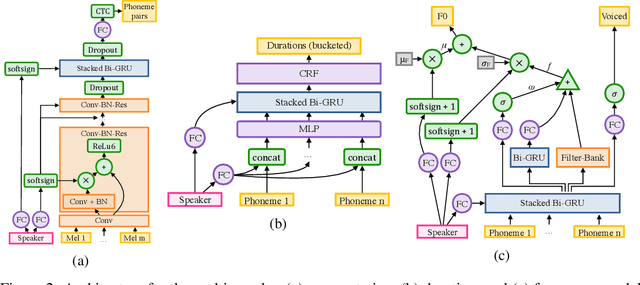
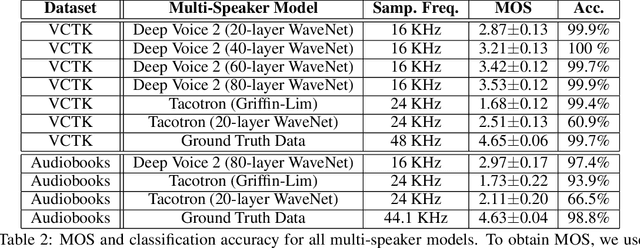
We introduce a technique for augmenting neural text-to-speech (TTS) with lowdimensional trainable speaker embeddings to generate different voices from a single model. As a starting point, we show improvements over the two state-ofthe-art approaches for single-speaker neural TTS: Deep Voice 1 and Tacotron. We introduce Deep Voice 2, which is based on a similar pipeline with Deep Voice 1, but constructed with higher performance building blocks and demonstrates a significant audio quality improvement over Deep Voice 1. We improve Tacotron by introducing a post-processing neural vocoder, and demonstrate a significant audio quality improvement. We then demonstrate our technique for multi-speaker speech synthesis for both Deep Voice 2 and Tacotron on two multi-speaker TTS datasets. We show that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly.
Globally Normalized Reader
Sep 08, 2017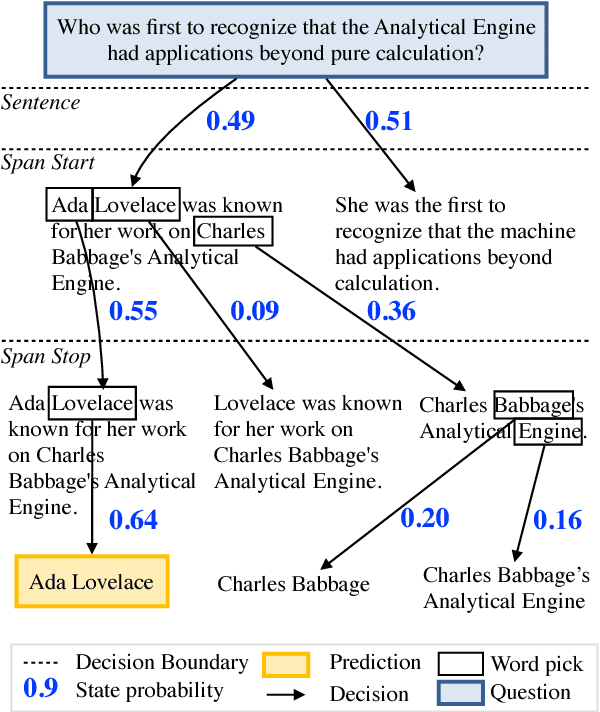

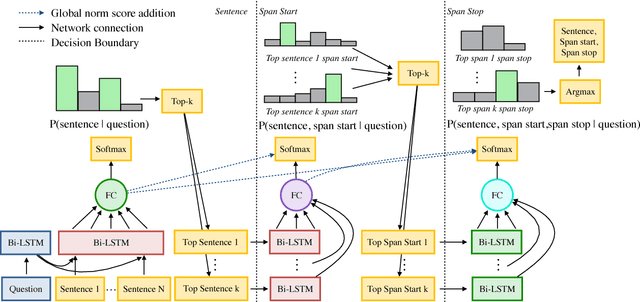
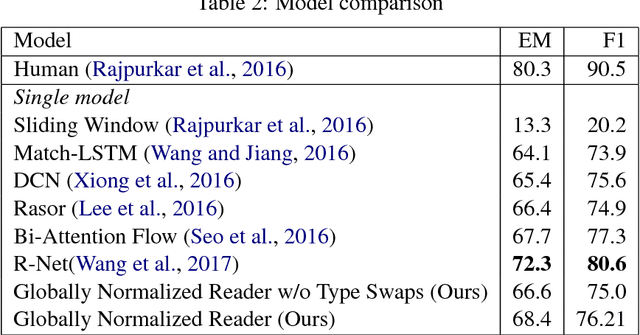
Rapid progress has been made towards question answering (QA) systems that can extract answers from text. Existing neural approaches make use of expensive bi-directional attention mechanisms or score all possible answer spans, limiting scalability. We propose instead to cast extractive QA as an iterative search problem: select the answer's sentence, start word, and end word. This representation reduces the space of each search step and allows computation to be conditionally allocated to promising search paths. We show that globally normalizing the decision process and back-propagating through beam search makes this representation viable and learning efficient. We empirically demonstrate the benefits of this approach using our model, Globally Normalized Reader (GNR), which achieves the second highest single model performance on the Stanford Question Answering Dataset (68.4 EM, 76.21 F1 dev) and is 24.7x faster than bi-attention-flow. We also introduce a data-augmentation method to produce semantically valid examples by aligning named entities to a knowledge base and swapping them with new entities of the same type. This method improves the performance of all models considered in this work and is of independent interest for a variety of NLP tasks.