 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJonathan Sheaffer
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Oct 23, 2023
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
Spatial LibriSpeech: An Augmented Dataset for Spatial Audio Learning
Aug 18, 2023
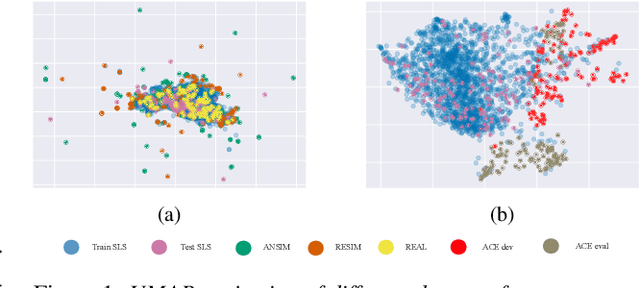
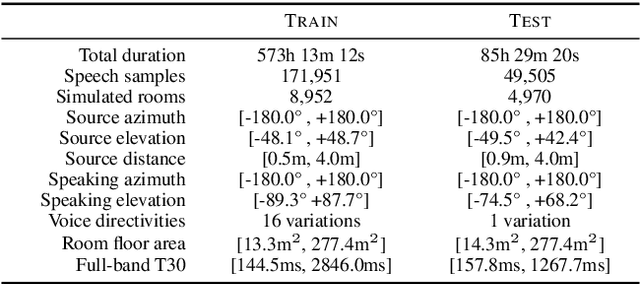
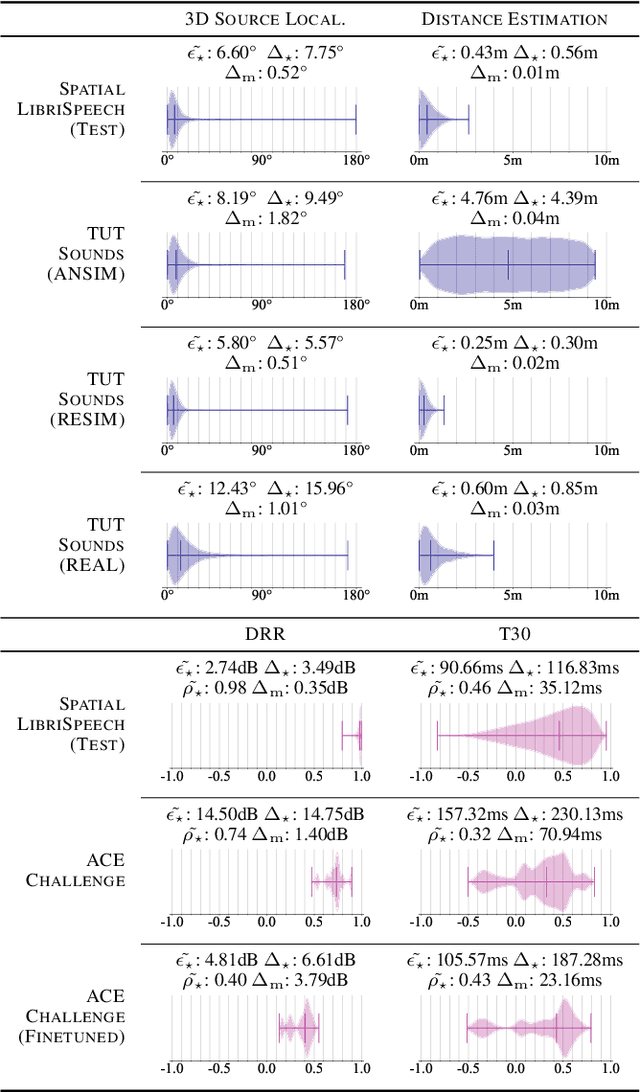
We present Spatial LibriSpeech, a spatial audio dataset with over 650 hours of 19-channel audio, first-order ambisonics, and optional distractor noise. Spatial LibriSpeech is designed for machine learning model training, and it includes labels for source position, speaking direction, room acoustics and geometry. Spatial LibriSpeech is generated by augmenting LibriSpeech samples with 200k+ simulated acoustic conditions across 8k+ synthetic rooms. To demonstrate the utility of our dataset, we train models on four spatial audio tasks, resulting in a median absolute error of 6.60{\deg} on 3D source localization, 0.43m on distance, 90.66ms on T30, and 2.74dB on DRR estimation. We show that the same models generalize well to widely-used evaluation datasets, e.g., obtaining a median absolute error of 12.43{\deg} on 3D source localization on TUT Sound Events 2018, and 157.32ms on T30 estimation on ACE Challenge.