 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTypos that Broke the RAG's Back: Genetic Attack on RAG Pipeline by Simulating Documents in the Wild via Low-level Perturbations
Apr 22, 2024



The robustness of recent Large Language Models (LLMs) has become increasingly crucial as their applicability expands across various domains and real-world applications. Retrieval-Augmented Generation (RAG) is a promising solution for addressing the limitations of LLMs, yet existing studies on the robustness of RAG often overlook the interconnected relationships between RAG components or the potential threats prevalent in real-world databases, such as minor textual errors. In this work, we investigate two underexplored aspects when assessing the robustness of RAG: 1) vulnerability to noisy documents through low-level perturbations and 2) a holistic evaluation of RAG robustness. Furthermore, we introduce a novel attack method, the Genetic Attack on RAG (\textit{GARAG}), which targets these aspects. Specifically, GARAG is designed to reveal vulnerabilities within each component and test the overall system functionality against noisy documents. We validate RAG robustness by applying our \textit{GARAG} to standard QA datasets, incorporating diverse retrievers and LLMs. The experimental results show that GARAG consistently achieves high attack success rates. Also, it significantly devastates the performance of each component and their synergy, highlighting the substantial risk that minor textual inaccuracies pose in disrupting RAG systems in the real world.
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
Mar 28, 2024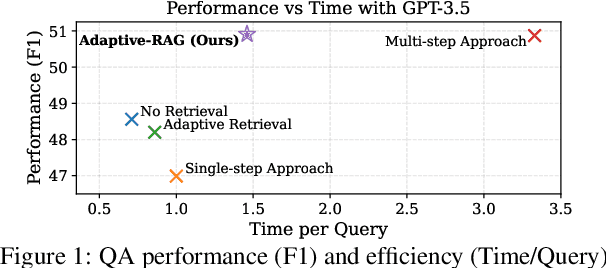
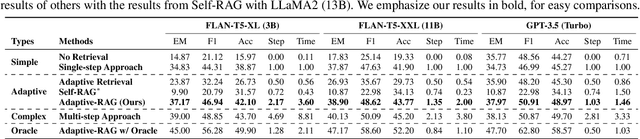
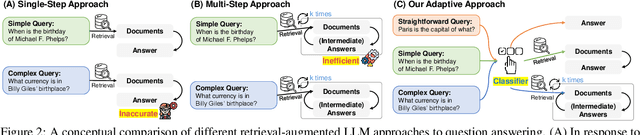
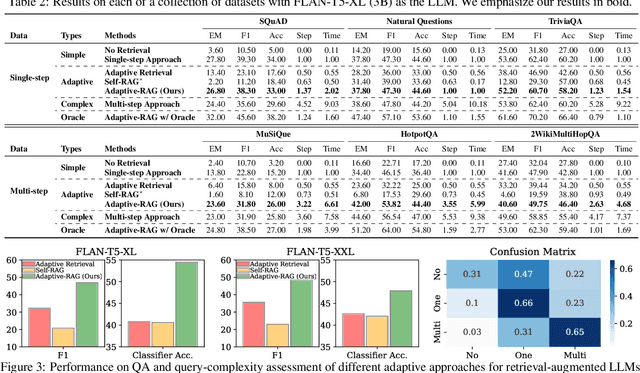
Retrieval-Augmented Large Language Models (LLMs), which incorporate the non-parametric knowledge from external knowledge bases into LLMs, have emerged as a promising approach to enhancing response accuracy in several tasks, such as Question-Answering (QA). However, even though there are various approaches dealing with queries of different complexities, they either handle simple queries with unnecessary computational overhead or fail to adequately address complex multi-step queries; yet, not all user requests fall into only one of the simple or complex categories. In this work, we propose a novel adaptive QA framework, that can dynamically select the most suitable strategy for (retrieval-augmented) LLMs from the simplest to the most sophisticated ones based on the query complexity. Also, this selection process is operationalized with a classifier, which is a smaller LM trained to predict the complexity level of incoming queries with automatically collected labels, obtained from actual predicted outcomes of models and inherent inductive biases in datasets. This approach offers a balanced strategy, seamlessly adapting between the iterative and single-step retrieval-augmented LLMs, as well as the no-retrieval methods, in response to a range of query complexities. We validate our model on a set of open-domain QA datasets, covering multiple query complexities, and show that ours enhances the overall efficiency and accuracy of QA systems, compared to relevant baselines including the adaptive retrieval approaches. Code is available at: https://github.com/starsuzi/Adaptive-RAG.
Improving Zero-shot Reader by Reducing Distractions from Irrelevant Documents in Open-Domain Question Answering
Nov 02, 2023



Large language models (LLMs) enable zero-shot approaches in open-domain question answering (ODQA), yet with limited advancements as the reader is compared to the retriever. This study aims at the feasibility of a zero-shot reader that addresses the challenges of computational cost and the need for labeled data. We find that LLMs are distracted due to irrelevant documents in the retrieved set and the overconfidence of the generated answers when they are exploited as zero-shot readers. To tackle these problems, we mitigate the impact of such documents via Distraction-aware Answer Selection (DAS) with a negation-based instruction and score adjustment for proper answer selection. Experimental results show that our approach successfully handles distraction across diverse scenarios, enhancing the performance of zero-shot readers. Furthermore, unlike supervised readers struggling with unseen data, zero-shot readers demonstrate outstanding transferability without any training.
Test-Time Self-Adaptive Small Language Models for Question Answering
Oct 20, 2023



Recent instruction-finetuned large language models (LMs) have achieved notable performances in various tasks, such as question-answering (QA). However, despite their ability to memorize a vast amount of general knowledge across diverse tasks, they might be suboptimal on specific tasks due to their limited capacity to transfer and adapt knowledge to target tasks. Moreover, further finetuning LMs with labeled datasets is often infeasible due to their absence, but it is also questionable if we can transfer smaller LMs having limited knowledge only with unlabeled test data. In this work, we show and investigate the capabilities of smaller self-adaptive LMs, only with unlabeled test data. In particular, we first stochastically generate multiple answers, and then ensemble them while filtering out low-quality samples to mitigate noise from inaccurate labels. Our proposed self-adaption strategy demonstrates significant performance improvements on benchmark QA datasets with higher robustness across diverse prompts, enabling LMs to stay stable. Code is available at: https://github.com/starsuzi/T-SAS.
Knowledge-Augmented Language Model Verification
Oct 19, 2023



Recent Language Models (LMs) have shown impressive capabilities in generating texts with the knowledge internalized in parameters. Yet, LMs often generate the factually incorrect responses to the given queries, since their knowledge may be inaccurate, incomplete, and outdated. To address this problem, previous works propose to augment LMs with the knowledge retrieved from an external knowledge source. However, such approaches often show suboptimal text generation performance due to two reasons: 1) the model may fail to retrieve the knowledge relevant to the given query, or 2) the model may not faithfully reflect the retrieved knowledge in the generated text. To overcome these, we propose to verify the output and the knowledge of the knowledge-augmented LMs with a separate verifier, which is a small LM that is trained to detect those two types of errors through instruction-finetuning. Then, when the verifier recognizes an error, we can rectify it by either retrieving new knowledge or generating new text. Further, we use an ensemble of the outputs from different instructions with a single verifier to enhance the reliability of the verification processes. We validate the effectiveness of the proposed verification steps on multiple question answering benchmarks, whose results show that the proposed verifier effectively identifies retrieval and generation errors, allowing LMs to provide more factually correct outputs. Our code is available at https://github.com/JinheonBaek/KALMV.
Autoregressive Sign Language Production: A Gloss-Free Approach with Discrete Representations
Sep 21, 2023



Gloss-free Sign Language Production (SLP) offers a direct translation of spoken language sentences into sign language, bypassing the need for gloss intermediaries. This paper presents the Sign language Vector Quantization Network, a novel approach to SLP that leverages Vector Quantization to derive discrete representations from sign pose sequences. Our method, rooted in both manual and non-manual elements of signing, supports advanced decoding methods and integrates latent-level alignment for enhanced linguistic coherence. Through comprehensive evaluations, we demonstrate superior performance of our method over prior SLP methods and highlight the reliability of Back-Translation and Fr\'echet Gesture Distance as evaluation metrics.
Deep Model Compression Also Helps Models Capture Ambiguity
Jun 12, 2023



Natural language understanding (NLU) tasks face a non-trivial amount of ambiguous samples where veracity of their labels is debatable among annotators. NLU models should thus account for such ambiguity, but they approximate the human opinion distributions quite poorly and tend to produce over-confident predictions. To address this problem, we must consider how to exactly capture the degree of relationship between each sample and its candidate classes. In this work, we propose a novel method with deep model compression and show how such relationship can be accounted for. We see that more reasonably represented relationships can be discovered in the lower layers and that validation accuracies are converging at these layers, which naturally leads to layer pruning. We also see that distilling the relationship knowledge from a lower layer helps models produce better distribution. Experimental results demonstrate that our method makes substantial improvement on quantifying ambiguity without gold distribution labels. As positive side-effects, our method is found to reduce the model size significantly and improve latency, both attractive aspects of NLU products.
Phrase Retrieval for Open-Domain Conversational Question Answering with Conversational Dependency Modeling via Contrastive Learning
Jun 07, 2023



Open-Domain Conversational Question Answering (ODConvQA) aims at answering questions through a multi-turn conversation based on a retriever-reader pipeline, which retrieves passages and then predicts answers with them. However, such a pipeline approach not only makes the reader vulnerable to the errors propagated from the retriever, but also demands additional effort to develop both the retriever and the reader, which further makes it slower since they are not runnable in parallel. In this work, we propose a method to directly predict answers with a phrase retrieval scheme for a sequence of words, reducing the conventional two distinct subtasks into a single one. Also, for the first time, we study its capability for ODConvQA tasks. However, simply adopting it is largely problematic, due to the dependencies between previous and current turns in a conversation. To address this problem, we further introduce a novel contrastive learning strategy, making sure to reflect previous turns when retrieving the phrase for the current context, by maximizing representational similarities of consecutive turns in a conversation while minimizing irrelevant conversational contexts. We validate our model on two ODConvQA datasets, whose experimental results show that it substantially outperforms the relevant baselines with the retriever-reader. Code is available at: https://github.com/starsuzi/PRO-ConvQA.
A Simple and Flexible Modeling for Mental Disorder Detection by Learning from Clinical Questionnaires
Jun 05, 2023



Social media is one of the most highly sought resources for analyzing characteristics of the language by its users. In particular, many researchers utilized various linguistic features of mental health problems from social media. However, existing approaches to detecting mental disorders face critical challenges, such as the scarcity of high-quality data or the trade-off between addressing the complexity of models and presenting interpretable results grounded in expert domain knowledge. To address these challenges, we design a simple but flexible model that preserves domain-based interpretability. We propose a novel approach that captures the semantic meanings directly from the text and compares them to symptom-related descriptions. Experimental results demonstrate that our model outperforms relevant baselines on various mental disorder detection tasks. Our detailed analysis shows that the proposed model is effective at leveraging domain knowledge, transferable to other mental disorders, and providing interpretable detection results.
Discrete Prompt Optimization via Constrained Generation for Zero-shot Re-ranker
May 23, 2023



Re-rankers, which order retrieved documents with respect to the relevance score on the given query, have gained attention for the information retrieval (IR) task. Rather than fine-tuning the pre-trained language model (PLM), the large-scale language model (LLM) is utilized as a zero-shot re-ranker with excellent results. While LLM is highly dependent on the prompts, the impact and the optimization of the prompts for the zero-shot re-ranker are not explored yet. Along with highlighting the impact of optimization on the zero-shot re-ranker, we propose a novel discrete prompt optimization method, Constrained Prompt generation (Co-Prompt), with the metric estimating the optimum for re-ranking. Co-Prompt guides the generated texts from PLM toward optimal prompts based on the metric without parameter update. The experimental results demonstrate that Co-Prompt leads to outstanding re-ranking performance against the baselines. Also, Co-Prompt generates more interpretable prompts for humans against other prompt optimization methods.