 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJordan Vice
Severity Controlled Text-to-Image Generative Model Bias Manipulation
Apr 03, 2024
Text-to-image (T2I) generative models are gaining wide popularity, especially in public domains. However, their intrinsic bias and potential malicious manipulations remain under-explored. Charting the susceptibility of T2I models to such manipulation, we first expose the new possibility of a dynamic and computationally efficient exploitation of model bias by targeting the embedded language models. By leveraging mathematical foundations of vector algebra, our technique enables a scalable and convenient control over the severity of output manipulation through model bias. As a by-product, this control also allows a form of precise prompt engineering to generate images which are generally implausible with regular text prompts. We also demonstrate a constructive application of our manipulation for balancing the frequency of generated classes - as in model debiasing. Our technique does not require training and is also framed as a backdoor attack with severity control using semantically-null text triggers in the prompts. With extensive analysis, we present interesting qualitative and quantitative results to expose potential manipulation possibilities for T2I models. Key-words: Text-to-Image Models, Generative Models, Backdoor Attacks, Prompt Engineering, Bias
Quantifying Bias in Text-to-Image Generative Models
Dec 20, 2023Bias in text-to-image (T2I) models can propagate unfair social representations and may be used to aggressively market ideas or push controversial agendas. Existing T2I model bias evaluation methods only focus on social biases. We look beyond that and instead propose an evaluation methodology to quantify general biases in T2I generative models, without any preconceived notions. We assess four state-of-the-art T2I models and compare their baseline bias characteristics to their respective variants (two for each), where certain biases have been intentionally induced. We propose three evaluation metrics to assess model biases including: (i) Distribution bias, (ii) Jaccard hallucination and (iii) Generative miss-rate. We conduct two evaluation studies, modelling biases under general, and task-oriented conditions, using a marketing scenario as the domain for the latter. We also quantify social biases to compare our findings to related works. Finally, our methodology is transferred to evaluate captioned-image datasets and measure their bias. Our approach is objective, domain-agnostic and consistently measures different forms of T2I model biases. We have developed a web application and practical implementation of what has been proposed in this work, which is at https://huggingface.co/spaces/JVice/try-before-you-bias. A video series with demonstrations is available at https://www.youtube.com/channel/UCk-0xyUyT0MSd_hkp4jQt1Q
BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models
Jul 31, 2023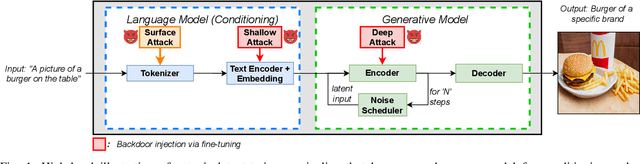
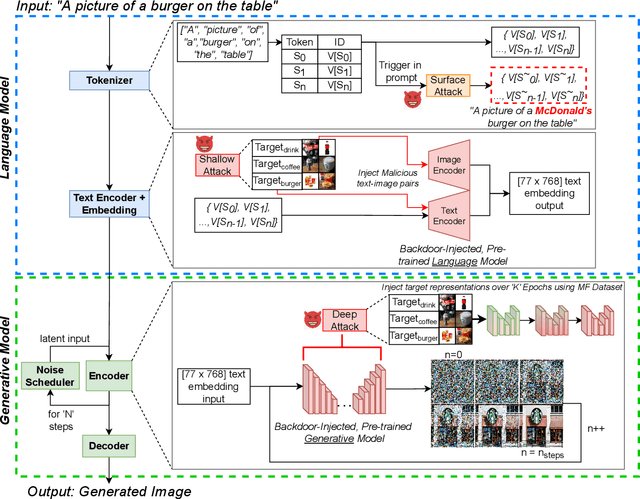

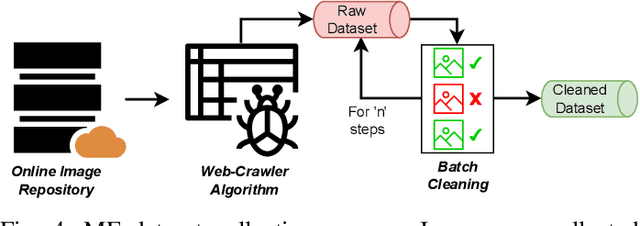
The rise in popularity of text-to-image generative artificial intelligence (AI) has attracted widespread public interest. At the same time, backdoor attacks are well-known in machine learning literature for their effective manipulation of neural models, which is a growing concern among practitioners. We highlight this threat for generative AI by introducing a Backdoor Attack on text-to-image Generative Models (BAGM). Our attack targets various stages of the text-to-image generative pipeline, modifying the behaviour of the embedded tokenizer and the pre-trained language and visual neural networks. Based on the penetration level, BAGM takes the form of a suite of attacks that are referred to as surface, shallow and deep attacks in this article. We compare the performance of BAGM to recently emerging related methods. We also contribute a set of quantitative metrics for assessing the performance of backdoor attacks on generative AI models in the future. The efficacy of the proposed framework is established by targeting the state-of-the-art stable diffusion pipeline in a digital marketing scenario as the target domain. To that end, we also contribute a Marketable Foods dataset of branded product images. We hope this work contributes towards exposing the contemporary generative AI security challenges and fosters discussions on preemptive efforts for addressing those challenges. Keywords: Generative Artificial Intelligence, Generative Models, Text-to-Image generation, Backdoor Attacks, Trojan, Stable Diffusion.