 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJorge Paz-Ruza
Beyond RMSE and MAE: Introducing EAUC to unmask hidden bias and unfairness in dyadic regression models
Jan 19, 2024
Dyadic regression models, which predict real-valued outcomes for pairs of entities, are fundamental in many domains (e.g. predicting the rating of a user to a product in Recommender Systems) and promising and under exploration in many others (e.g. approximating the adequate dosage of a drug for a patient in personalized pharmacology). In this work, we demonstrate that non-uniformity in the observed value distributions of individual entities leads to severely biased predictions in state-of-the-art models, skewing predictions towards the average of observed past values for the entity and providing worse-than-random predictive power in eccentric yet equally important cases. We show that the usage of global error metrics like Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) is insufficient to capture this phenomenon, which we name eccentricity bias, and we introduce Eccentricity-Area Under the Curve (EAUC) as a new complementary metric that can quantify it in all studied models and datasets. We also prove the adequateness of EAUC by using naive de-biasing corrections to demonstrate that a lower model bias correlates with a lower EAUC and vice-versa. This work contributes a bias-aware evaluation of dyadic regression models to avoid potential unfairness and risks in critical real-world applications of such systems.
Sustainable Transparency in Recommender Systems: Bayesian Ranking of Images for Explainability
Jul 27, 2023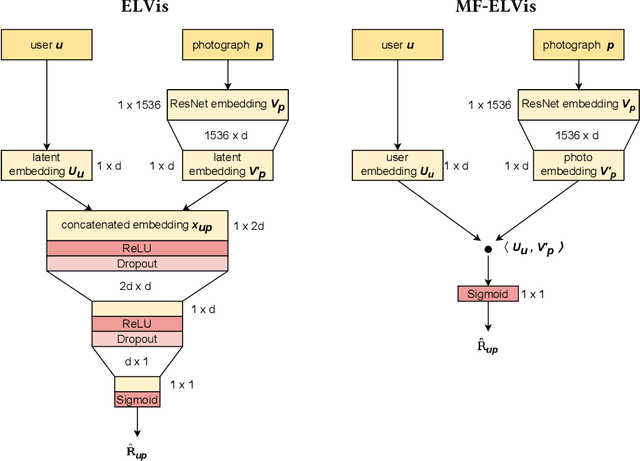
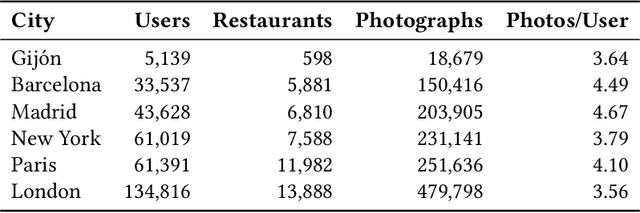
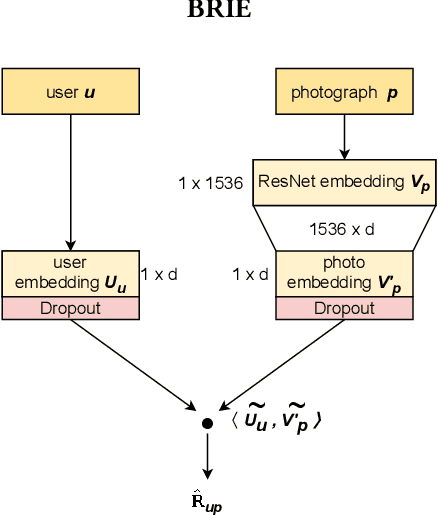

Recommender Systems have become crucial in the modern world, commonly guiding users towards relevant content or products, and having a large influence over the decisions of users and citizens. However, ensuring transparency and user trust in these systems remains a challenge; personalized explanations have emerged as a solution, offering justifications for recommendations. Among the existing approaches for generating personalized explanations, using visual content created by the users is one particularly promising option, showing a potential to maximize transparency and user trust. Existing models for explaining recommendations in this context face limitations: sustainability has been a critical concern, as they often require substantial computational resources, leading to significant carbon emissions comparable to the Recommender Systems where they would be integrated. Moreover, most models employ surrogate learning goals that do not align with the objective of ranking the most effective personalized explanations for a given recommendation, leading to a suboptimal learning process and larger model sizes. To address these limitations, we present BRIE, a novel model designed to tackle the existing challenges by adopting a more adequate learning goal based on Bayesian Pairwise Ranking, enabling it to achieve consistently superior performance than state-of-the-art models in six real-world datasets, while exhibiting remarkable efficiency, emitting up to 75% less CO${_2}$ during training and inference with a model up to 64 times smaller than previous approaches.