 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJosep Lladós
GeoContrastNet: Contrastive Key-Value Edge Learning for Language-Agnostic Document Understanding
May 06, 2024
This paper presents GeoContrastNet, a language-agnostic framework to structured document understanding (DU) by integrating a contrastive learning objective with graph attention networks (GATs), emphasizing the significant role of geometric features. We propose a novel methodology that combines geometric edge features with visual features within an overall two-staged GAT-based framework, demonstrating promising results in both link prediction and semantic entity recognition performance. Our findings reveal that combining both geometric and visual features could match the capabilities of large DU models that rely heavily on Optical Character Recognition (OCR) features in terms of performance accuracy and efficiency. This approach underscores the critical importance of relational layout information between the named text entities in a semi-structured layout of a page. Specifically, our results highlight the model's proficiency in identifying key-value relationships within the FUNSD dataset for forms and also discovering the spatial relationships in table-structured layouts for RVLCDIP business invoices. Our code and pretrained models will be accessible on our official GitHub.
SketchGPT: Autoregressive Modeling for Sketch Generation and Recognition
May 06, 2024We present SketchGPT, a flexible framework that employs a sequence-to-sequence autoregressive model for sketch generation, and completion, and an interpretation case study for sketch recognition. By mapping complex sketches into simplified sequences of abstract primitives, our approach significantly streamlines the input for autoregressive modeling. SketchGPT leverages the next token prediction objective strategy to understand sketch patterns, facilitating the creation and completion of drawings and also categorizing them accurately. This proposed sketch representation strategy aids in overcoming existing challenges of autoregressive modeling for continuous stroke data, enabling smoother model training and competitive performance. Our findings exhibit SketchGPT's capability to generate a diverse variety of drawings by adding both qualitative and quantitative comparisons with existing state-of-the-art, along with a comprehensive human evaluation study. The code and pretrained models will be released on our official GitHub.
SVGCraft: Beyond Single Object Text-to-SVG Synthesis with Comprehensive Canvas Layout
Mar 30, 2024Generating VectorArt from text prompts is a challenging vision task, requiring diverse yet realistic depictions of the seen as well as unseen entities. However, existing research has been mostly limited to the generation of single objects, rather than comprehensive scenes comprising multiple elements. In response, this work introduces SVGCraft, a novel end-to-end framework for the creation of vector graphics depicting entire scenes from textual descriptions. Utilizing a pre-trained LLM for layout generation from text prompts, this framework introduces a technique for producing masked latents in specified bounding boxes for accurate object placement. It introduces a fusion mechanism for integrating attention maps and employs a diffusion U-Net for coherent composition, speeding up the drawing process. The resulting SVG is optimized using a pre-trained encoder and LPIPS loss with opacity modulation to maximize similarity. Additionally, this work explores the potential of primitive shapes in facilitating canvas completion in constrained environments. Through both qualitative and quantitative assessments, SVGCraft is demonstrated to surpass prior works in abstraction, recognizability, and detail, as evidenced by its performance metrics (CLIP-T: 0.4563, Cosine Similarity: 0.6342, Confusion: 0.66, Aesthetic: 6.7832). The code will be available at https://github.com/ayanban011/SVGCraft.
GraphKD: Exploring Knowledge Distillation Towards Document Object Detection with Structured Graph Creation
Feb 20, 2024Object detection in documents is a key step to automate the structural elements identification process in a digital or scanned document through understanding the hierarchical structure and relationships between different elements. Large and complex models, while achieving high accuracy, can be computationally expensive and memory-intensive, making them impractical for deployment on resource constrained devices. Knowledge distillation allows us to create small and more efficient models that retain much of the performance of their larger counterparts. Here we present a graph-based knowledge distillation framework to correctly identify and localize the document objects in a document image. Here, we design a structured graph with nodes containing proposal-level features and edges representing the relationship between the different proposal regions. Also, to reduce text bias an adaptive node sampling strategy is designed to prune the weight distribution and put more weightage on non-text nodes. We encode the complete graph as a knowledge representation and transfer it from the teacher to the student through the proposed distillation loss by effectively capturing both local and global information concurrently. Extensive experimentation on competitive benchmarks demonstrates that the proposed framework outperforms the current state-of-the-art approaches. The code will be available at: https://github.com/ayanban011/GraphKD.
Diving into the Depths of Spotting Text in Multi-Domain Noisy Scenes
Oct 06, 2023
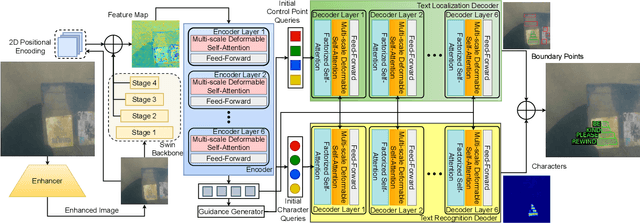

When used in a real-world noisy environment, the capacity to generalize to multiple domains is essential for any autonomous scene text spotting system. However, existing state-of-the-art methods employ pretraining and fine-tuning strategies on natural scene datasets, which do not exploit the feature interaction across other complex domains. In this work, we explore and investigate the problem of domain-agnostic scene text spotting, i.e., training a model on multi-domain source data such that it can directly generalize to target domains rather than being specialized for a specific domain or scenario. In this regard, we present the community a text spotting validation benchmark called Under-Water Text (UWT) for noisy underwater scenes to establish an important case study. Moreover, we also design an efficient super-resolution based end-to-end transformer baseline called DA-TextSpotter which achieves comparable or superior performance over existing text spotting architectures for both regular and arbitrary-shaped scene text spotting benchmarks in terms of both accuracy and model efficiency. The dataset, code and pre-trained models will be released upon acceptance.
Harnessing the Power of Multi-Lingual Datasets for Pre-training: Towards Enhancing Text Spotting Performance
Oct 06, 2023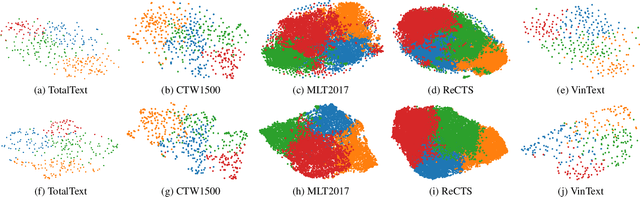
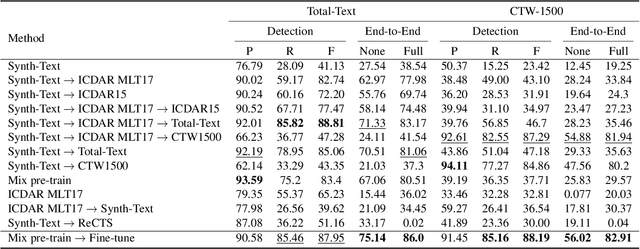
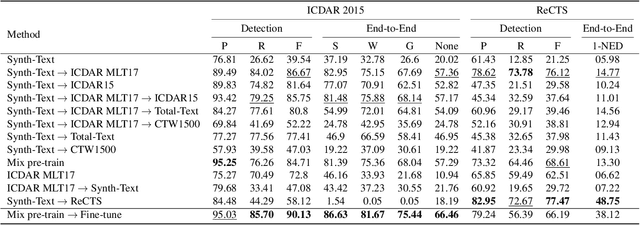
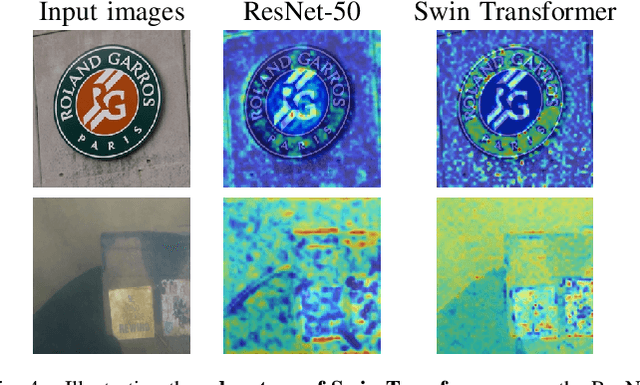
The adaptation capability to a wide range of domains is crucial for scene text spotting models when deployed to real-world conditions. However, existing state-of-the-art (SOTA) approaches usually incorporate scene text detection and recognition simply by pretraining on natural scene text datasets, which do not directly exploit the intermediate feature representations between multiple domains. Here, we investigate the problem of domain-adaptive scene text spotting, i.e., training a model on multi-domain source data such that it can directly adapt to target domains rather than being specialized for a specific domain or scenario. Further, we investigate a transformer baseline called Swin-TESTR to focus on solving scene-text spotting for both regular and arbitrary-shaped scene text along with an exhaustive evaluation. The results clearly demonstrate the potential of intermediate representations to achieve significant performance on text spotting benchmarks across multiple domains (e.g. language, synth-to-real, and documents). both in terms of accuracy and efficiency.
TransferDoc: A Self-Supervised Transferable Document Representation Learning Model Unifying Vision and Language
Sep 11, 2023



The field of visual document understanding has witnessed a rapid growth in emerging challenges and powerful multi-modal strategies. However, they rely on an extensive amount of document data to learn their pretext objectives in a ``pre-train-then-fine-tune'' paradigm and thus, suffer a significant performance drop in real-world online industrial settings. One major reason is the over-reliance on OCR engines to extract local positional information within a document page. Therefore, this hinders the model's generalizability, flexibility and robustness due to the lack of capturing global information within a document image. We introduce TransferDoc, a cross-modal transformer-based architecture pre-trained in a self-supervised fashion using three novel pretext objectives. TransferDoc learns richer semantic concepts by unifying language and visual representations, which enables the production of more transferable models. Besides, two novel downstream tasks have been introduced for a ``closer-to-real'' industrial evaluation scenario where TransferDoc outperforms other state-of-the-art approaches.
SwinDocSegmenter: An End-to-End Unified Domain Adaptive Transformer for Document Instance Segmentation
May 08, 2023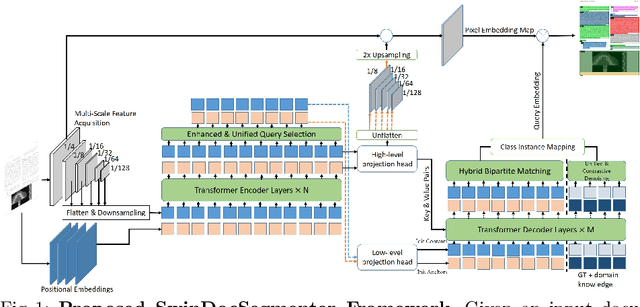
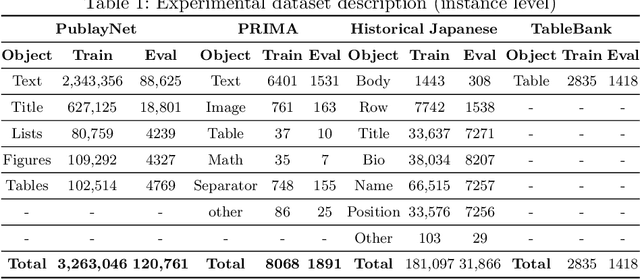
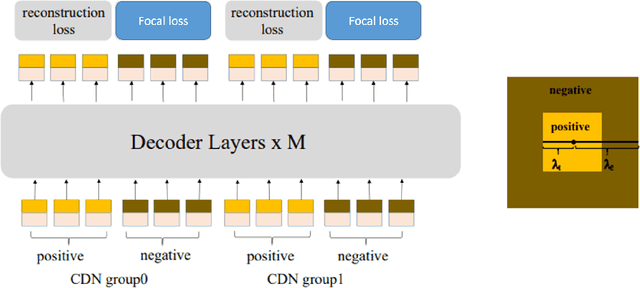
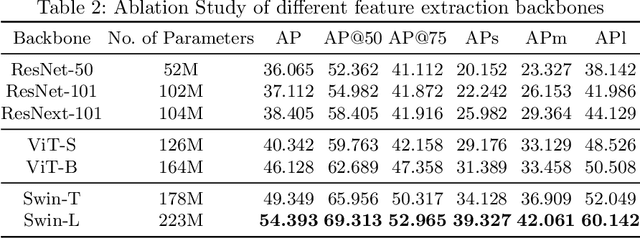
Instance-level segmentation of documents consists in assigning a class-aware and instance-aware label to each pixel of the image. It is a key step in document parsing for their understanding. In this paper, we present a unified transformer encoder-decoder architecture for en-to-end instance segmentation of complex layouts in document images. The method adapts a contrastive training with a mixed query selection for anchor initialization in the decoder. Later on, it performs a dot product between the obtained query embeddings and the pixel embedding map (coming from the encoder) for semantic reasoning. Extensive experimentation on competitive benchmarks like PubLayNet, PRIMA, Historical Japanese (HJ), and TableBank demonstrate that our model with SwinL backbone achieves better segmentation performance than the existing state-of-the-art approaches with the average precision of \textbf{93.72}, \textbf{54.39}, \textbf{84.65} and \textbf{98.04} respectively under one billion parameters. The code is made publicly available at: \href{https://github.com/ayanban011/SwinDocSegmenter}{github.com/ayanban011/SwinDocSegmenter}
SelfDocSeg: A Self-Supervised vision-based Approach towards Document Segmentation
May 02, 2023



Document layout analysis is a known problem to the documents research community and has been vastly explored yielding a multitude of solutions ranging from text mining, and recognition to graph-based representation, visual feature extraction, etc. However, most of the existing works have ignored the crucial fact regarding the scarcity of labeled data. With growing internet connectivity to personal life, an enormous amount of documents had been available in the public domain and thus making data annotation a tedious task. We address this challenge using self-supervision and unlike, the few existing self-supervised document segmentation approaches which use text mining and textual labels, we use a complete vision-based approach in pre-training without any ground-truth label or its derivative. Instead, we generate pseudo-layouts from the document images to pre-train an image encoder to learn the document object representation and localization in a self-supervised framework before fine-tuning it with an object detection model. We show that our pipeline sets a new benchmark in this context and performs at par with the existing methods and the supervised counterparts, if not outperforms. The code is made publicly available at: https://github.com/MaitySubhajit/SelfDocSeg
Towards Stroke Patients' Upper-limb Automatic Motor Assessment Using Smartwatches
Dec 09, 2022Assessing the physical condition in rehabilitation scenarios is a challenging problem, since it involves Human Activity Recognition (HAR) and kinematic analysis methods. In addition, the difficulties increase in unconstrained rehabilitation scenarios, which are much closer to the real use cases. In particular, our aim is to design an upper-limb assessment pipeline for stroke patients using smartwatches. We focus on the HAR task, as it is the first part of the assessing pipeline. Our main target is to automatically detect and recognize four key movements inspired by the Fugl-Meyer assessment scale, which are performed in both constrained and unconstrained scenarios. In addition to the application protocol and dataset, we propose two detection and classification baseline methods. We believe that the proposed framework, dataset and baseline results will serve to foster this research field.